
Pre-training visible language (VL) fashions on web-scale image-caption datasets has just lately emerged as a strong different to conventional pre-training on picture classification knowledge. Picture-caption datasets are thought-about to be extra “open-domain” as a result of they include broader scene sorts and vocabulary phrases, which end in fashions with strong performance in few- and zero-shot recognition tasks. Nonetheless, photos with fine-grained class descriptions might be uncommon, and the category distribution might be imbalanced since image-caption datasets don’t undergo handbook curation. In contrast, large-scale classification datasets, resembling ImageNet, are sometimes curated and might thus present fine-grained classes with a balanced label distribution. Whereas it could sound promising, immediately combining caption and classification datasets for pre-training is commonly unsuccessful because it can lead to biased representations that don’t generalize nicely to numerous downstream duties.
In “Prefix Conditioning Unifies Language and Label Supervision”, introduced at CVPR 2023, we show a pre-training technique that makes use of each classification and caption datasets to offer complementary advantages. First, we present that naïvely unifying the datasets ends in sub-optimal efficiency on downstream zero-shot recognition duties because the mannequin is affected by dataset bias: the protection of picture domains and vocabulary phrases is completely different in every dataset. We tackle this drawback throughout coaching by means of prefix conditioning, a novel easy and efficient technique that makes use of prefix tokens to disentangle dataset biases from visible ideas. This strategy permits the language encoder to be taught from each datasets whereas additionally tailoring characteristic extraction to every dataset. Prefix conditioning is a generic technique that may be simply built-in into current VL pre-training goals, resembling Contrastive Language-Image Pre-training (CLIP) or Unified Contrastive Learning (UniCL).
Excessive-level concept
We observe that classification datasets are typically biased in at the very least two methods: (1) the pictures principally include single objects from restricted domains, and (2) the vocabulary is proscribed and lacks the linguistic flexibility required for zero-shot studying. For instance, the category embedding of “a photograph of a canine” optimized for ImageNet often ends in a photograph of 1 canine within the heart of the picture pulled from the ImageNet dataset, which doesn’t generalize nicely to different datasets containing photos of a number of canines in numerous spatial places or a canine with different topics.
In contrast, caption datasets include a greater diversity of scene sorts and vocabularies. As proven under, if a mannequin merely learns from two datasets, the language embedding can entangle the bias from the picture classification and caption dataset, which might lower the generalization in zero-shot classification. If we will disentangle the bias from two datasets, we will use language embeddings which are tailor-made for the caption dataset to enhance generalization.
 |
| High: Language embedding entangling the bias from picture classification and caption dataset. Backside: Language embeddings disentangles the bias from two datasets. |
Prefix conditioning
Prefix conditioning is partially impressed by prompt tuning, which prepends learnable tokens to the enter token sequences to instruct a pre-trained mannequin spine to be taught task-specific information that can be utilized to unravel downstream duties. The prefix conditioning strategy differs from immediate tuning in two methods: (1) it’s designed to unify image-caption and classification datasets by disentangling the dataset bias, and (2) it’s utilized to VL pre-training whereas the usual immediate tuning is used to fine-tune fashions. Prefix conditioning is an specific technique to particularly steer the habits of mannequin backbones primarily based on the kind of datasets supplied by customers. That is particularly useful in manufacturing when the variety of various kinds of datasets is thought forward of time.
Throughout coaching, prefix conditioning learns a textual content token (prefix token) for every dataset kind, which absorbs the bias of the dataset and permits the remaining textual content tokens to deal with studying visible ideas. Particularly, it prepends prefix tokens for every dataset kind to the enter tokens that inform the language and visible encoder of the enter knowledge kind (e.g., classification vs. caption). Prefix tokens are educated to be taught the dataset-type-specific bias, which permits us to disentangle that bias in language representations and make the most of the embedding realized on the image-caption dataset throughout take a look at time, even with out an enter caption.
We make the most of prefix conditioning for CLIP utilizing a language and visible encoder. Throughout take a look at time, we make use of the prefix used for the image-caption dataset because the dataset is meant to cowl broader scene sorts and vocabulary phrases, main to higher efficiency in zero-shot recognition.
 |
| Illustration of the Prefix Conditioning. |
Experimental outcomes
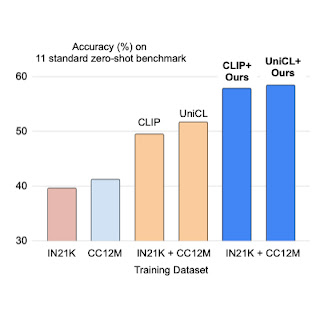
We apply prefix conditioning to 2 forms of contrastive loss, CLIP and UniCL, and consider their efficiency on zero-shot recognition duties in comparison with fashions educated with ImageNet21K (IN21K) and Conceptual 12M (CC12M). CLIP and UniCL fashions educated with two datasets utilizing prefix conditioning present giant enhancements in zero-shot classification accuracy.
 |
| Zero-shot classification accuracy of fashions educated with solely IN21K or CC12M in comparison with CLIP and UniCL fashions educated with each two datasets utilizing prefix conditioning (“Ours”). |
Examine on test-time prefix
The desk under describes the efficiency change by the prefix used throughout take a look at time. We show that through the use of the identical prefix used for the classification dataset (“Immediate”), the efficiency on the classification dataset (IN-1K) improves. When utilizing the identical prefix used for the image-caption dataset (“Caption”), the efficiency on different datasets (Zero-shot AVG) improves. This evaluation illustrates that if the prefix is tailor-made for the image-caption dataset, it achieves higher generalization of scene sorts and vocabulary phrases.
 |
| Evaluation of the prefix used for test-time. |
Examine on robustness to picture distribution shift
We examine the shift in picture distribution utilizing ImageNet variants. We see that the “Caption” prefix performs higher than “Immediate” in ImageNet-R (IN-R) and ImageNet-Sketch (IN-S), however underperforms in ImageNet-V2 (IN-V2). This means that the “Caption” prefix achieves generalization on domains removed from the classification dataset. Subsequently, the optimum prefix most likely differs by how far the take a look at area is from the classification dataset.
 |
| Evaluation on the robustness to image-level distribution shift. IN: ImageNet, IN-V2: ImageNet-V2, IN-R: Artwork, Cartoon type ImageNet, IN-S: ImageNet Sketch. |
Conclusion and future work
We introduce prefix conditioning, a method for unifying picture caption and classification datasets for higher zero-shot classification. We present that this strategy results in higher zero-shot classification accuracy and that the prefix can management the bias within the language embedding. One limitation is that the prefix realized on the caption dataset will not be essentially optimum for the zero-shot classification. Figuring out the optimum prefix for every take a look at dataset is an fascinating route for future work.
Acknowledgements
This analysis was performed by Kuniaki Saito, Kihyuk Sohn, Xiang Zhang, Chun-Liang Li, Chen-Yu Lee, Kate Saenko, and Tomas Pfister. Due to Zizhao Zhang and Sergey Ioffe for his or her priceless suggestions.

