

Educating cellular robots to navigate in complicated outside environments is crucial to real-world purposes, comparable to supply or search and rescue. Nevertheless, that is additionally a difficult downside because the robotic must understand its environment, after which discover to determine possible paths in the direction of the purpose. One other frequent problem is that the robotic wants to beat uneven terrains, comparable to stairs, curbs, or rockbed on a path, whereas avoiding obstacles and pedestrians. In our prior work, we investigated the second problem by educating a quadruped robotic to sort out difficult uneven obstacles and various outdoor terrains.
In “IndoorSim-to-OutdoorReal: Learning to Navigate Outdoors without any Outdoor Experience”, we current our latest work to sort out the robotic problem of reasoning in regards to the perceived environment to determine a viable navigation path in outside environments. We introduce a learning-based indoor-to-outdoor switch algorithm that makes use of deep reinforcement studying to coach a navigation coverage in simulated indoor environments, and efficiently transfers that very same coverage to actual outside environments. We additionally introduce Context-Maps (maps with surroundings observations created by a consumer), that are utilized to our algorithm to allow environment friendly long-range navigation. We reveal that with this coverage, robots can efficiently navigate a whole lot of meters in novel outside environments, round beforehand unseen outside obstacles (bushes, bushes, buildings, pedestrians, and so forth.), and in several climate situations (sunny, overcast, sundown).
PointGoal navigation
Person inputs can inform a robotic the place to go together with instructions like “go to the Android statue”, photos exhibiting a goal location, or by merely choosing some extent on a map. On this work, we specify the navigation purpose (a particular level on a map) as a relative coordinate to the robotic’s present place (i.e., “go to ∆x, ∆y”), that is often known as the PointGoal Visual Navigation (PointNav) process. PointNav is a normal formulation for navigation duties and is among the normal selections for indoor navigation duties. Nevertheless, as a result of numerous visuals, uneven terrains and lengthy distance objectives in outside environments, coaching PointNav insurance policies for outside environments is a difficult process.
Indoor-to-outdoor switch
Latest successes in coaching wheeled and legged robotic brokers to navigate in indoor environments have been enabled by the event of quick, scalable simulators and the supply of large-scale datasets of photorealistic 3D scans of indoor environments. To leverage these successes, we develop an indoor-to-outdoor switch method that permits our robots to study from simulated indoor environments and to be deployed in actual outside environments.
To beat the variations between simulated indoor environments and actual outside environments, we apply kinematic control and picture augmentation methods in our studying system. When utilizing kinematic management, we assume the existence of a dependable low-level locomotion controller that may management the robotic to exactly attain a brand new location. This assumption permits us to immediately transfer the robotic to the goal location throughout simulation coaching via a forward Euler integration and relieves us from having to explicitly mannequin the underlying robotic dynamics in simulation, which drastically improves the throughput of simulation knowledge era. Prior work has proven that kinematic management can result in higher sim-to-real switch in comparison with a dynamic control approach, the place full robotic dynamics are modeled and a low-level locomotion controller is required for transferring the robotic.
| Left Kinematic management; Proper: Dynamic management |
We created an out of doors maze-like surroundings utilizing objects discovered indoors for preliminary experiments, the place we used Boston Dynamics’ Spot robot for check navigation. We discovered that the robotic may navigate round novel obstacles within the new outside surroundings.
| The Spot robotic efficiently navigates round obstacles present in indoor environments, with a coverage skilled totally in simulation. |
Nevertheless, when confronted with unfamiliar outside obstacles not seen throughout coaching, comparable to a big slope, the robotic was unable to navigate the slope.
| The robotic is unable to navigate up slopes, as slopes are uncommon in indoor environments and the robotic was not skilled to sort out it. |
To allow the robotic to stroll up and down slopes, we apply a picture augmentation method throughout the simulation coaching. Particularly, we randomly tilt the simulated digicam on the robotic throughout coaching. It may be pointed up or down inside 30 levels. This augmentation successfully makes the robotic understand slopes regardless that the ground is stage. Coaching on these perceived slopes allows the robotic to navigate slopes within the real-world.
| By randomly tilting the digicam angle throughout coaching in simulation, the robotic is now in a position to stroll up and down slopes. |
Because the robots have been solely skilled in simulated indoor environments, by which they usually must stroll to a purpose just some meters away, we discover that the discovered community didn’t course of longer-range inputs — e.g., the coverage didn’t stroll ahead for 100 meters in an empty house. To allow the coverage community to deal with long-range inputs which are frequent for outside navigation, we normalize the purpose vector through the use of the log of the purpose distance.
Context-Maps for complicated long-range navigation
Placing all the pieces collectively, the robotic can navigate open air in the direction of the purpose, whereas strolling on uneven terrain, and avoiding bushes, pedestrians and different outside obstacles. Nevertheless, there’s nonetheless one key element lacking: the robotic’s means to plan an environment friendly long-range path. At this scale of navigation, taking a incorrect flip and backtracking could be pricey. For instance, we discover that the native exploration technique discovered by normal PointNav insurance policies are inadequate to find a long-range purpose and often results in a lifeless finish (proven under). It is because the robotic is navigating with out context of its surroundings, and the optimum path is probably not seen to the robotic from the beginning.
| Navigation insurance policies with out context of the surroundings don’t deal with complicated long-range navigation objectives. |
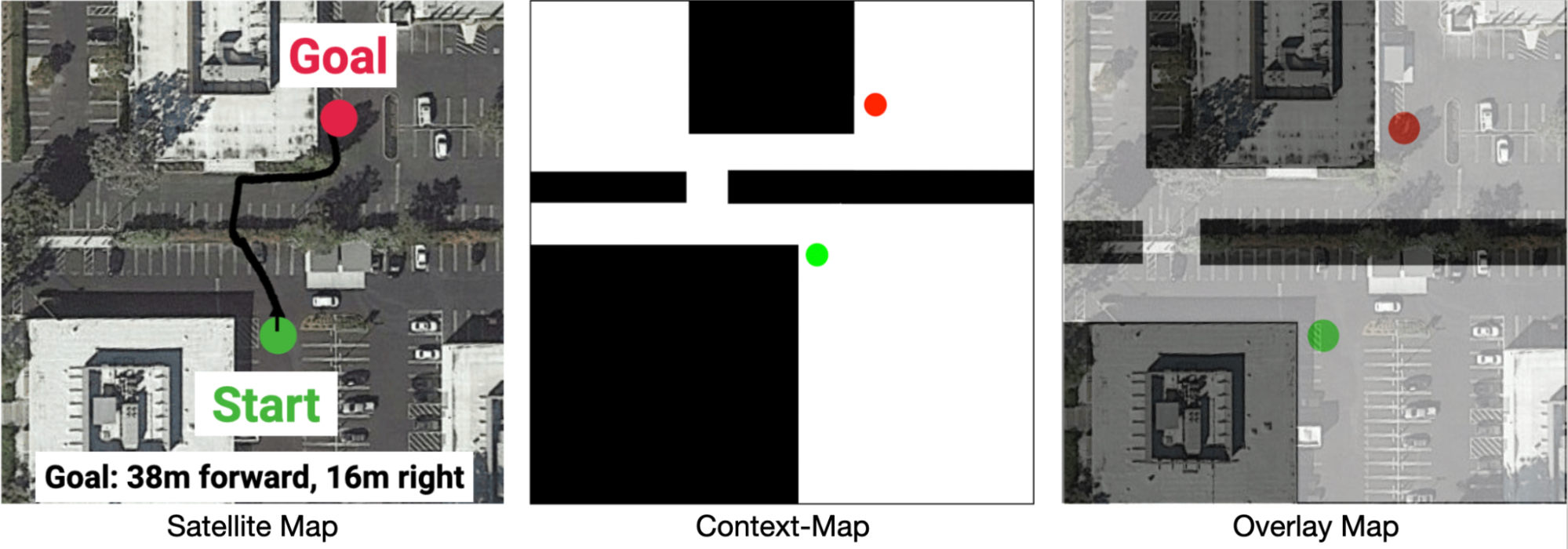
To allow the robotic to take the context into consideration and purposefully plan an environment friendly path, we offer a Context-Map (a binary picture that represents a top-down occupancy map of the area that the robotic is inside) as further observations for the robotic. An instance Context-Map is given under, the place the black area denotes areas occupied by obstacles and white area is walkable by the robotic. The inexperienced and pink circle denotes the beginning and purpose location of the navigation process. By means of the Context-Map, we are able to present hints to the robotic (e.g., the slender opening within the route under) to assist it plan an environment friendly navigation route. In our experiments, we create the Context-Map for every route guided by Google Maps satellite pictures. We denote this variant of PointNav with environmental context, as Context-Guided PointNav.
 |
| Instance of the Context-Map (proper) for a navigation process (left). |
It is very important be aware that the Context-Map doesn’t should be correct as a result of it solely serves as a tough define for planning. Throughout navigation, the robotic nonetheless must depend on its onboard cameras to determine and adapt its path to pedestrians, that are absent on the map. In our experiments, a human operator rapidly sketches the Context-Map from the satellite tv for pc picture, masking out the areas to be averted. This Context-Map, along with different onboard sensory inputs, together with depth pictures and relative place to the purpose, are fed right into a neural community with attention fashions (i.e., transformers), that are skilled utilizing DD-PPO, a distributed implementation of proximal policy optimization, in large-scale simulations.
 |
| The Context-Guided PointNav structure consists of a 3-layer convolutional neural network (CNN) to course of depth pictures from the robotic’s digicam, and a multilayer perceptron (MLP) to course of the purpose vector. The options are handed right into a gated recurrent unit (GRU). We use a further CNN encoder to course of the context-map (top-down map). We compute the scaled dot product attention between the map and the depth picture, and use a second GRU to course of the attended options (Context Attn., Depth Attn.). The output of the coverage are linear and angular velocities for the Spot robotic to comply with. |
Outcomes
We consider our system throughout three long-range outside navigation duties. The supplied Context-Maps are tough, incomplete surroundings outlines that omit obstacles, comparable to automobiles, bushes, or chairs.
With the proposed algorithm, our robotic can efficiently attain the distant purpose location 100% of the time, and not using a single collision or human intervention. The robotic was in a position to navigate round pedestrians and real-world litter that aren’t current on the context-map, and navigate on numerous terrain together with dust slopes and grass.
Route 1
 |
Route 2
 |
Route 3
 |
Conclusion
This work opens up robotic navigation analysis to the much less explored area of numerous outside environments. Our indoor-to-outdoor switch algorithm makes use of zero real-world expertise and doesn’t require the simulator to mannequin predominantly-outdoor phenomena (terrain, ditches, sidewalks, automobiles, and so forth). The success within the strategy comes from a mixture of a sturdy locomotion management, low sim-to-real hole in depth and map sensors, and large-scale coaching in simulation. We reveal that offering robots with approximate, high-level maps can allow long-range navigation in novel outside environments. Our outcomes present compelling proof for difficult the (admittedly affordable) speculation {that a} new simulator should be designed for each new state of affairs we want to examine. For extra info, please see our project page.
Acknowledgements
We want to thank Sonia Chernova, Tingnan Zhang, April Zitkovich, Dhruv Batra, and Jie Tan for advising and contributing to the challenge. We’d additionally wish to thank Naoki Yokoyama, Nubby Lee, Diego Reyes, Ben Jyenis, and Gus Kouretas for assist with the robotic experiment setup.

