
Public well being organizations have a wealth of knowledge about several types of ailments, well being traits, and danger components. Their employees has lengthy used statistical fashions and regression analyses to make vital choices comparable to concentrating on populations with the very best danger components for a illness with therapeutics, or forecasting the development of regarding outbreaks.
When public well being threats emerge, knowledge velocity will increase, incoming datasets can develop bigger, and knowledge administration turns into tougher. This makes it tougher to research knowledge holistically and seize insights from it. And when time is of the essence, pace and agility in analyzing knowledge and drawing insights from it are key blockers to forming fast and sturdy well being responses.
Typical questions public well being organizations face throughout occasions of stress embrace:
- Will there be adequate therapeutics in a sure location?
- What danger components are driving well being outcomes?
- Which populations have a better danger of reinfection?
As a result of answering these questions requires understanding complicated relationships between many alternative components—typically altering and dynamic—one highly effective instrument we now have at our disposal is machine studying (ML), which will be deployed to research, predict, and resolve these complicated quantitative issues. Now we have more and more seen ML utilized to deal with tough health-related issues comparable to classifying brain tumors with picture evaluation and predicting the need for mental health to deploy early intervention packages.
However what occurs if public well being organizations are in brief provide of the abilities required to use ML to those questions? The applying of ML to public well being issues is impeded, and public well being organizations lose the power to use highly effective quantitative instruments to deal with their challenges.
So how can we take away these bottlenecks? The reply is to democratize ML and permit a bigger variety of well being professionals with deep area experience to make use of it and apply it to the questions they need to resolve.
Amazon SageMaker Canvas is a no-code ML instrument that empowers public well being professionals comparable to epidemiologists, informaticians, and bio-statisticians to use ML to their questions, with out requiring an information science background or ML experience. They will spend their time on the information, apply their area experience, shortly take a look at speculation, and quantify insights. Canvas helps make public well being extra equitable by democratizing ML, permitting well being specialists to guage giant datasets and empowering them with superior insights utilizing ML.
On this submit, we present how public well being specialists can forecast on-hand demand for a sure therapeutic for the following 30 days utilizing Canvas. Canvas gives you with a visible interface that means that you can generate correct ML predictions by yourself with out requiring any ML expertise or having to write down a single line of code.
Resolution overview
Let’s say we’re engaged on knowledge that we collected from states throughout the US. We might kind a speculation {that a} sure municipality or location doesn’t have sufficient therapeutics within the coming weeks. How can we take a look at this shortly and with a excessive diploma of accuracy?
For this submit, we use a publicly out there dataset from the US Division of Well being and Human Companies, which comprises state-aggregated time collection knowledge associated to COVID-19, together with hospital utilization, availability of sure therapeutics, and rather more. The dataset (COVID-19 Reported Patient Impact and Hospital Capacity by State Timeseries (RAW)) is downloadable from healthdata.gov, and has 135 columns and over 60,000 rows. The dataset is up to date periodically.
Within the following sections, we display easy methods to carry out exploratory knowledge evaluation and preparation, construct the ML forecasting mannequin, and generate predictions utilizing Canvas.
Carry out exploratory knowledge evaluation and preparation
When doing a time collection forecast in Canvas, we have to scale back the variety of options or columns in accordance with the service quotas. Initially, we scale back the variety of columns to the 12 which are prone to be essentially the most related. For instance, we dropped the age-specific columns as a result of we’re seeking to forecast complete demand. We additionally dropped columns whose knowledge was much like different columns we saved. In future iterations, it’s cheap to experiment with retaining different columns and utilizing function explainability in Canvas to quantify the significance of those options and which we need to preserve. We additionally rename the state column to location.
Wanting on the dataset, we additionally determine to take away all of the rows for 2020, as a result of there have been restricted therapeutics out there at the moment. This enables us to cut back the noise and enhance the standard of the information for the ML mannequin to be taught from.
Lowering the variety of columns will be carried out in several methods. You may edit the dataset in a spreadsheet, or instantly inside Canvas utilizing the consumer interface.
You may import knowledge into Canvas from varied sources, together with from native recordsdata out of your pc, Amazon Simple Storage Service (Amazon S3) buckets, Amazon Athena, Snowflake (see Prepare training and validation dataset for facies classification using Snowflake integration and train using Amazon SageMaker Canvas), and over 40 additional data sources.
After our knowledge has been imported, we will discover and visualize our knowledge to get extra insights into it, comparable to with scatterplots or bar charts. We additionally take a look at the correlation between totally different options to make sure that we now have chosen what we expect are the most effective ones. The next screenshot reveals an instance visualization.
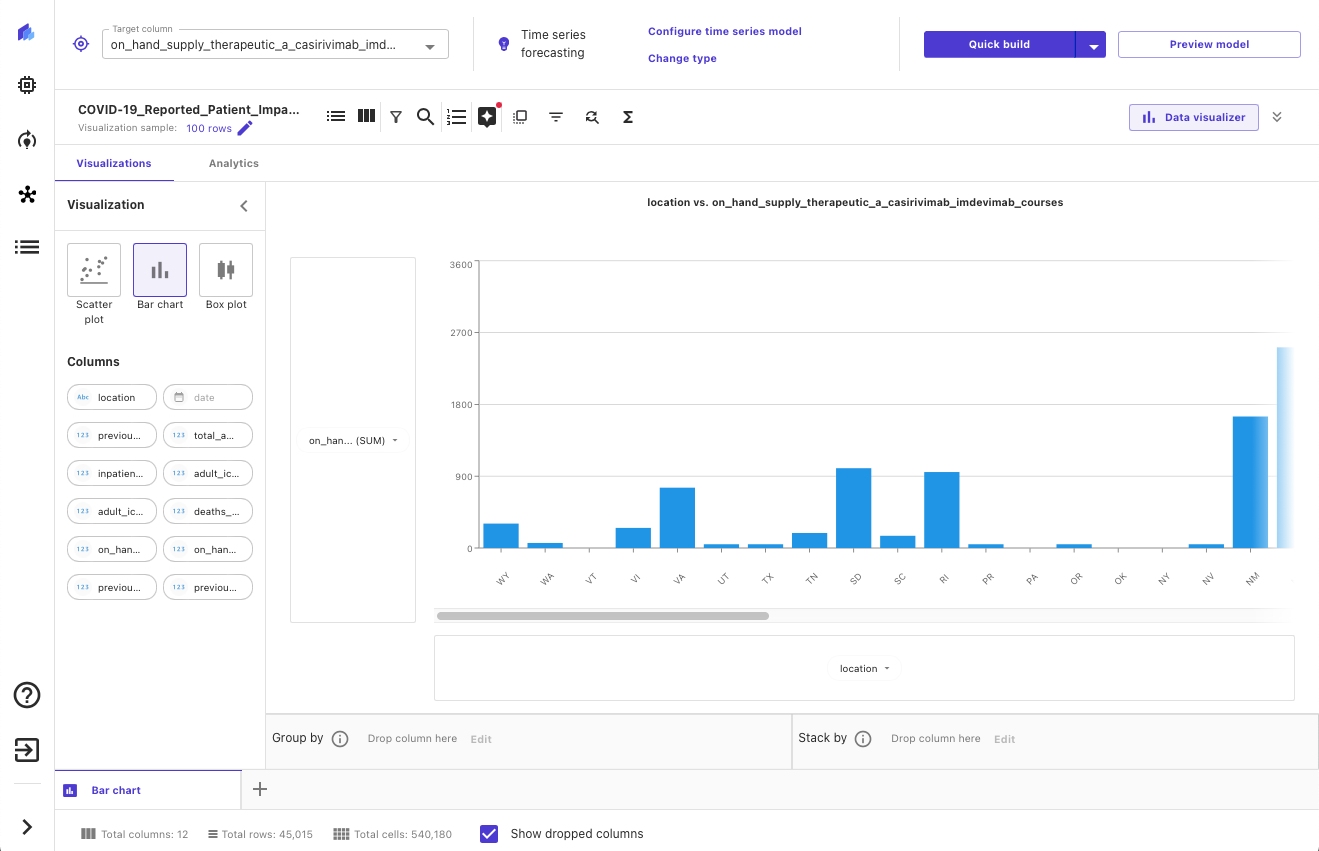
Construct the ML forecasting mannequin
Now we’re able to create our mannequin, which we will do with only a few clicks. We select the column figuring out on-hand therapeutics as our goal. Canvas mechanically identifies our downside as a time collection forecast primarily based on the goal column we simply chosen, and we will configure the parameters wanted.
We configure the item_id, the distinctive identifier, as location as a result of our dataset is supplied by location (US states). As a result of we’re making a time collection forecast, we have to choose a time stamp, which is date in our dataset. Lastly, we specify what number of days into the long run we need to forecast (for this instance, we select 30 days). Canvas additionally gives the power to incorporate a vacation schedule to enhance accuracy. On this case, we use US holidays as a result of this can be a US-based dataset.
With Canvas, you may get insights out of your knowledge earlier than you construct a mannequin by selecting Preview mannequin. This protects you time and price by not constructing a mannequin if the outcomes are unlikely to be passable. By previewing our mannequin, we understand that the influence of some columns is low, which means the anticipated worth of the column to the mannequin is low. We take away columns by deselecting them in Canvas (crimson arrows within the following screenshot) and see an enchancment in an estimated high quality metric (inexperienced arrow).
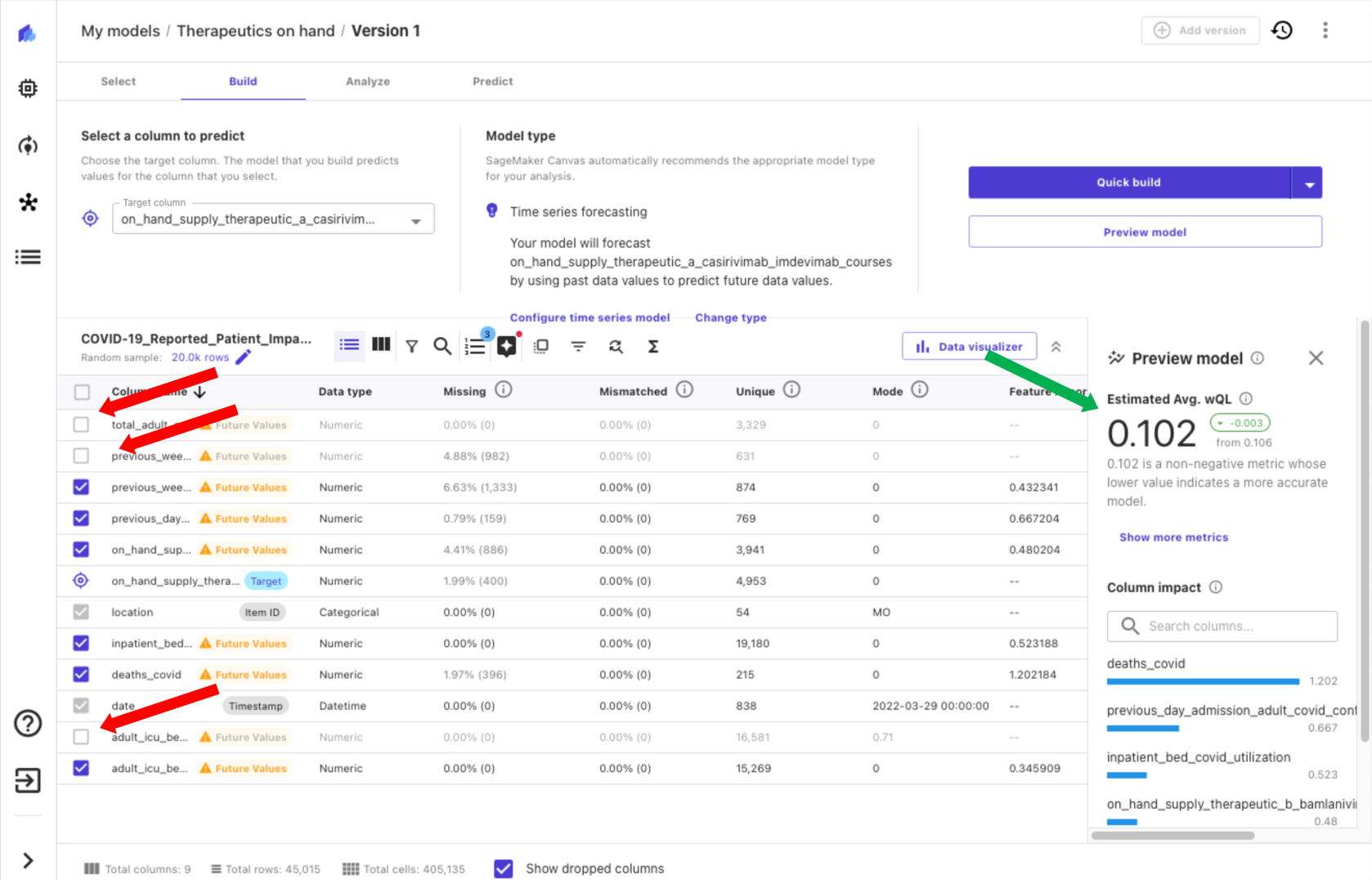
Transferring on to constructing our mannequin, we now have two choices, Fast construct and Commonplace construct. Fast construct produces a skilled mannequin in lower than 20 minutes, prioritizing pace over accuracy. That is nice for experimentation, and is a extra thorough mannequin than the preview mannequin. Commonplace construct produces a skilled mannequin in underneath 4 hours, prioritizing accuracy over latency, iterating via quite a lot of mannequin configurations to mechanically choose the most effective mannequin.
First, we experiment with Fast construct to validate our mannequin preview. Then, as a result of we’re proud of the mannequin, we select Commonplace construct to have Canvas assist construct the very best mannequin for our dataset. If the Fast construct mannequin had produced unsatisfactory outcomes, then we’d return and alter the enter knowledge to seize a better degree of accuracy. We may accomplish this by, as an example, including or eradicating columns or rows in our authentic dataset. The Fast construct mannequin helps fast experimentation with out having to depend on scarce knowledge science sources or look forward to a full mannequin to be accomplished.
Generate predictions
Now that the mannequin has been constructed, we will predict the provision of therapeutics by location. Let’s take a look at what our estimated on-hand stock seems like for the following 30 days, on this case for Washington, DC.
Canvas outputs probabilistic forecasts for therapeutic demand, permitting us to grasp each the median worth in addition to higher and decrease bounds. Within the following screenshot, you’ll be able to see the tail finish of the historic knowledge (the information from the unique dataset). You may then see three new strains: the median (fiftieth quantile) forecast in purple, the decrease certain (tenth quantile) in gentle blue, and higher certain (ninetieth quantile) in darkish blue.
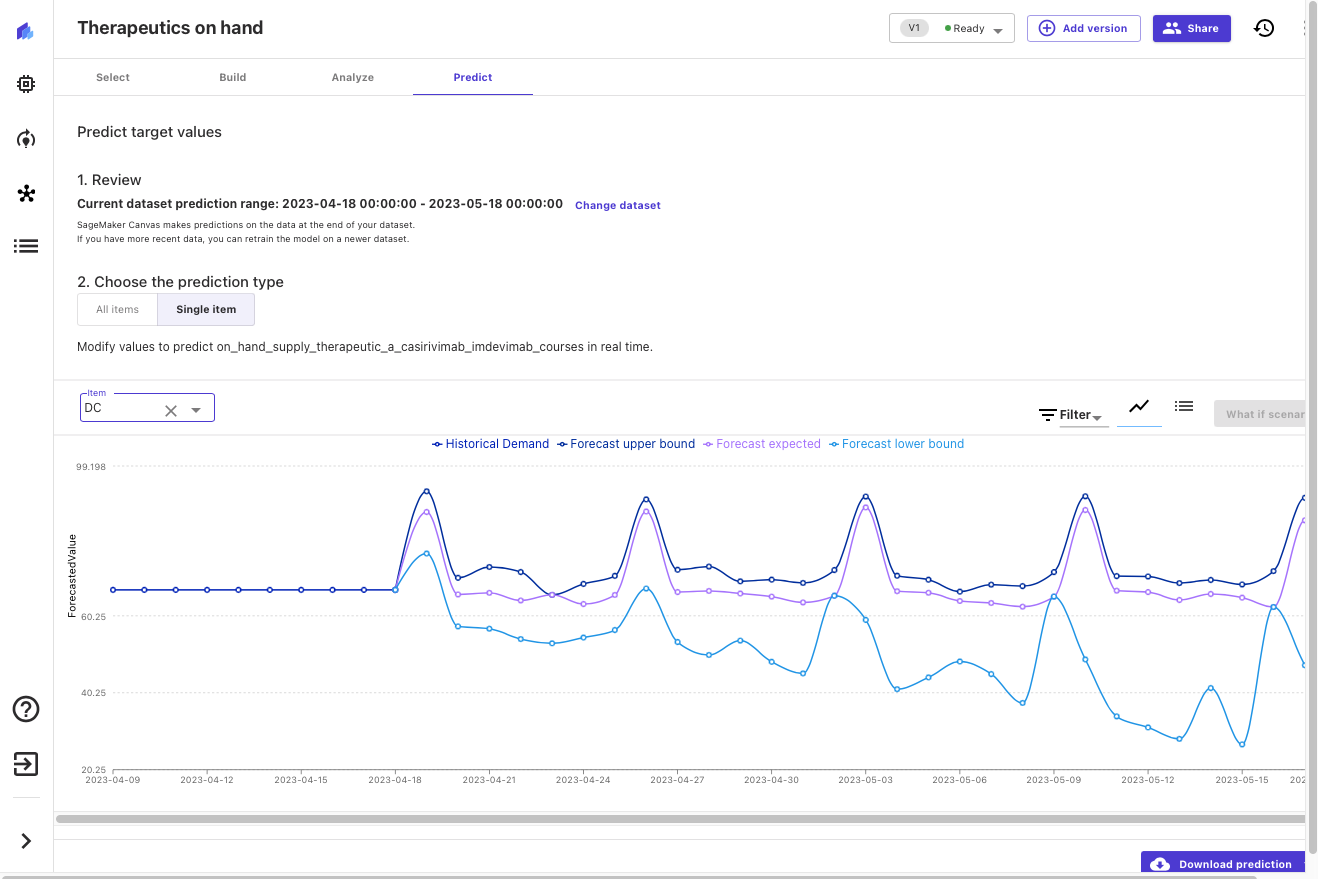
Analyzing higher and decrease bounds gives perception into the chance distribution of the forecast and permits us to make knowledgeable choices about desired ranges of native stock for this therapeutic. We will add this perception to different knowledge (for instance, illness development forecasts, or therapeutic efficacy and uptake) to make knowledgeable choices about future orders and stock ranges.
Conclusion
No-code ML instruments empower public well being specialists to shortly and successfully apply ML to public well being threats. This democratization of ML makes public well being organizations extra agile and extra environment friendly of their mission of defending public well being. Advert hoc analyses that may determine vital traits or inflection factors in public well being considerations can now be carried out instantly by specialists, with out having to compete for restricted ML professional sources and slowing down response occasions and decision-making.
On this submit, we confirmed how somebody with none information of ML can use Canvas to forecast the on-hand stock of a sure therapeutic. This evaluation will be carried out by any analyst within the area, via the facility of cloud applied sciences and no-code ML. Doing so distributes capabilities broadly and permits public well being businesses to be extra responsive, and to extra effectively use centralized and area workplace sources to ship higher public well being outcomes.
What are a few of the questions you could be asking, and the way might low-code/no-code instruments give you the chance that can assist you reply them? If you’re excited by studying extra about Canvas, check with Amazon SageMaker Canvas and begin making use of ML to your personal quantitative well being questions.
In regards to the authors
 Henrik Balle is a Sr. Options Architect at AWS supporting the US Public Sector. He works carefully with prospects on a variety of subjects from machine studying to safety and governance at scale. In his spare time, he loves street biking, motorcycling, otherwise you would possibly discover him engaged on one more residence enchancment challenge.
Henrik Balle is a Sr. Options Architect at AWS supporting the US Public Sector. He works carefully with prospects on a variety of subjects from machine studying to safety and governance at scale. In his spare time, he loves street biking, motorcycling, otherwise you would possibly discover him engaged on one more residence enchancment challenge.
 Dan Sinnreich leads Go to Market product administration for Amazon SageMaker Canvas and Amazon Forecast. He’s centered on democratizing low-code/no-code machine studying and making use of it to enhance enterprise outcomes. Earlier to AWS Dan constructed enterprise SaaS platforms and time-series danger fashions utilized by institutional buyers to handle danger and assemble portfolios. Exterior of labor, he will be discovered enjoying hockey, scuba diving, touring, and studying science fiction.
Dan Sinnreich leads Go to Market product administration for Amazon SageMaker Canvas and Amazon Forecast. He’s centered on democratizing low-code/no-code machine studying and making use of it to enhance enterprise outcomes. Earlier to AWS Dan constructed enterprise SaaS platforms and time-series danger fashions utilized by institutional buyers to handle danger and assemble portfolios. Exterior of labor, he will be discovered enjoying hockey, scuba diving, touring, and studying science fiction.

