
As machine studying (ML) turns into more and more prevalent in a variety of industries, organizations are discovering the necessity to practice and serve massive numbers of ML fashions to satisfy the varied wants of their clients. For software program as a service (SaaS) suppliers specifically, the power to coach and serve 1000’s of fashions effectively and cost-effectively is essential for staying aggressive in a quickly evolving market.
Coaching and serving 1000’s of fashions requires a sturdy and scalable infrastructure, which is the place Amazon SageMaker can assist. SageMaker is a completely managed platform that allows builders and information scientists to construct, practice, and deploy ML fashions shortly, whereas additionally providing the cost-saving advantages of utilizing the AWS Cloud infrastructure.
On this submit, we discover how you should use SageMaker options, together with Amazon SageMaker Processing, SageMaker coaching jobs, and SageMaker multi-model endpoints (MMEs), to coach and serve 1000’s of fashions in a cheap approach. To get began with the described resolution, you may consult with the accompanying pocket book on GitHub.
Use case: Vitality forecasting
For this submit, we assume the function of an ISV firm that helps their clients develop into extra sustainable by monitoring their power consumption and offering forecasts. Our firm has 1,000 clients who wish to higher perceive their power utilization and make knowledgeable selections about the right way to cut back their environmental impression. To do that, we use an artificial dataset and practice an ML mannequin based mostly on Prophet for every buyer to make power consumption forecasts. With SageMaker, we are able to effectively practice and serve these 1,000 fashions, offering our clients with correct and actionable insights into their power utilization.
There are three options within the generated dataset:
- customer_id – That is an integer identifier for every buyer, starting from 0–999.
- timestamp – This can be a date/time worth that signifies the time at which the power consumption was measured. The timestamps are randomly generated between the beginning and finish dates specified within the code.
- consumption – This can be a float worth that signifies the power consumption, measured in some arbitrary unit. The consumption values are randomly generated between 0–1,000 with sinusoidal seasonality.
Resolution overview
To effectively practice and serve 1000’s of ML fashions, we are able to use the next SageMaker options:
- SageMaker Processing – SageMaker Processing is a completely managed information preparation service that lets you carry out information processing and mannequin analysis duties in your enter information. You need to use SageMaker Processing to remodel uncooked information into the format wanted for coaching and inference, in addition to to run batch and on-line evaluations of your fashions.
- SageMaker training jobs – You need to use SageMaker coaching jobs to coach fashions on a wide range of algorithms and enter information sorts, and specify the compute sources wanted for coaching.
- SageMaker MMEs – Multi-model endpoints allow you to host a number of fashions on a single endpoint, which makes it simple to serve predictions from a number of fashions utilizing a single API. SageMaker MMEs can save time and sources by lowering the variety of endpoints wanted to serve predictions from a number of fashions. MMEs help internet hosting of each CPU- and GPU-backed fashions. Word that in our situation, we use 1,000 fashions, however this isn’t a limitation of the service itself.
The next diagram illustrates the answer structure.
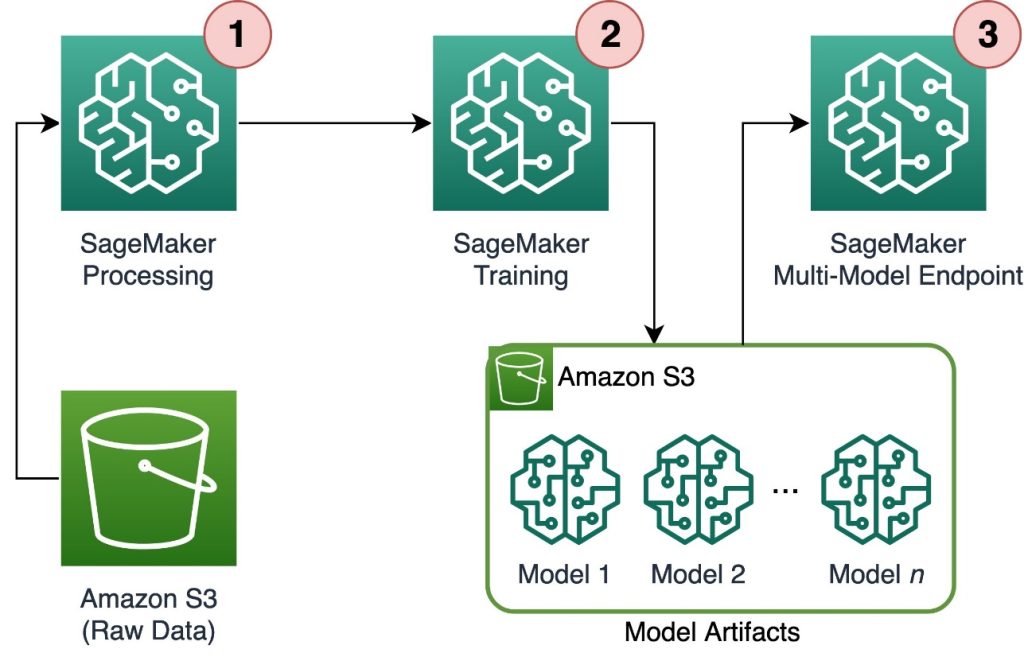
The workflow consists of the next steps:
- We use SageMaker Processing to preprocess information and create a single CSV file per buyer and retailer it in Amazon Simple Storage Service (Amazon S3).
- The SageMaker coaching job is configured to learn the output of the SageMaker Processing job and distribute it in a round-robin vogue to the coaching situations. Word that this can be achieved with Amazon SageMaker Pipelines.
- The mannequin artifacts are saved in Amazon S3 by the coaching job, and are served instantly from the SageMaker MME.
Scale coaching to 1000’s of fashions
Scaling the coaching of 1000’s of fashions is feasible by way of the distribution parameter of the TrainingInput class within the SageMaker Python SDK, which lets you specify how information is distributed throughout a number of coaching situations for a coaching job. There are three choices for the distribution parameter: FullyReplicated, ShardedByS3Key, and ShardedByRecord. The ShardedByS3Key choice signifies that the coaching information is sharded by S3 object key, with every coaching occasion receiving a novel subset of the information, avoiding duplication. After the information is copied by SageMaker to the coaching containers, we are able to learn the folder and recordsdata construction to coach a novel mannequin per buyer file. The next is an instance code snippet:
Each SageMaker coaching job shops the mannequin saved within the /choose/ml/mannequin folder of the coaching container earlier than archiving it in a mannequin.tar.gz file, after which uploads it to Amazon S3 upon coaching job completion. Energy customers also can automate this course of with SageMaker Pipelines. When storing a number of fashions by way of the identical coaching job, SageMaker creates a single mannequin.tar.gz file containing all of the skilled fashions. This could then imply that, so as to serve the mannequin, we would want to unpack the archive first. To keep away from this, we use checkpoints to avoid wasting the state of particular person fashions. SageMaker gives the performance to repeat checkpoints created throughout the coaching job to Amazon S3. Right here, the checkpoints must be saved in a pre-specified location, with the default being /choose/ml/checkpoints. These checkpoints can be utilized to renew coaching at a later second or as a mannequin to deploy on an endpoint. For a high-level abstract of how the SageMaker coaching platform manages storage paths for coaching datasets, mannequin artifacts, checkpoints, and outputs between AWS Cloud storage and coaching jobs in SageMaker, consult with Amazon SageMaker Training Storage Folders for Training Datasets, Checkpoints, Model Artifacts, and Outputs.
The next code makes use of a fictitious mannequin.save() operate contained in the practice.py script containing the coaching logic:
Scale inference to 1000’s of fashions with SageMaker MMEs
SageMaker MMEs help you serve a number of fashions on the identical time by creating an endpoint configuration that features a checklist of all of the fashions to serve, after which creating an endpoint utilizing that endpoint configuration. There isn’t any have to re-deploy the endpoint each time you add a brand new mannequin as a result of the endpoint will robotically serve all fashions saved within the specified S3 paths. That is achieved with Multi Model Server (MMS), an open-source framework for serving ML fashions that may be put in in containers to offer the entrance finish that fulfills the necessities for the brand new MME container APIs. As well as, you should use different mannequin servers together with TorchServe and Triton. MMS could be put in in your customized container by way of the SageMaker Inference Toolkit. To be taught extra about the right way to configure your Dockerfile to incorporate MMS and use it to serve your fashions, consult with Build Your Own Container for SageMaker Multi-Model Endpoints.
The next code snippet reveals the right way to create an MME utilizing the SageMaker Python SDK:
When the MME is stay, we are able to invoke it to generate predictions. Invocations could be achieved in any AWS SDK in addition to with the SageMaker Python SDK, as proven within the following code snippet:
When calling a mannequin, the mannequin is initially loaded from Amazon S3 on the occasion, which may end up in a chilly begin when calling a brand new mannequin. Often used fashions are cached in reminiscence and on disk to offer low-latency inference.
Conclusion
SageMaker is a strong and cost-effective platform for coaching and serving 1000’s of ML fashions. Its options, together with SageMaker Processing, coaching jobs, and MMEs, allow organizations to effectively practice and serve 1000’s of fashions at scale, whereas additionally benefiting from the cost-saving benefits of utilizing the AWS Cloud infrastructure. To be taught extra about the right way to use SageMaker for coaching and serving 1000’s of fashions, consult with Process data, Train a Model with Amazon SageMaker and Host multiple models in one container behind one endpoint.
In regards to the Authors
 Davide Gallitelli is a Specialist Options Architect for AI/ML within the EMEA area. He’s based mostly in Brussels and works carefully with clients all through Benelux. He has been a developer since he was very younger, beginning to code on the age of seven. He began studying AI/ML at college, and has fallen in love with it since then.
Davide Gallitelli is a Specialist Options Architect for AI/ML within the EMEA area. He’s based mostly in Brussels and works carefully with clients all through Benelux. He has been a developer since he was very younger, beginning to code on the age of seven. He began studying AI/ML at college, and has fallen in love with it since then.
 Maurits de Groot is a Options Architect at Amazon Net Companies, based mostly out of Amsterdam. He likes to work on machine learning-related subjects and has a predilection for startups. In his spare time, he enjoys snowboarding and enjoying squash.
Maurits de Groot is a Options Architect at Amazon Net Companies, based mostly out of Amsterdam. He likes to work on machine learning-related subjects and has a predilection for startups. In his spare time, he enjoys snowboarding and enjoying squash.

