
In recent times, vital efficiency features in autoregressive language modeling have been achieved by growing the variety of parameters in Transformer fashions. This has led to an amazing improve in coaching power value and resulted in a technology of dense “Giant Language Fashions” (LLMs) with 100+ billion parameters. Concurrently, giant datasets containing trillions of phrases have been collected to facilitate the coaching of those LLMs.
We discover an alternate path for bettering language fashions: we increase transformers with retrieval over a database of textual content passages together with internet pages, books, information and code. We name our methodology RETRO, for “Retrieval Enhanced TRansfOrmers”.
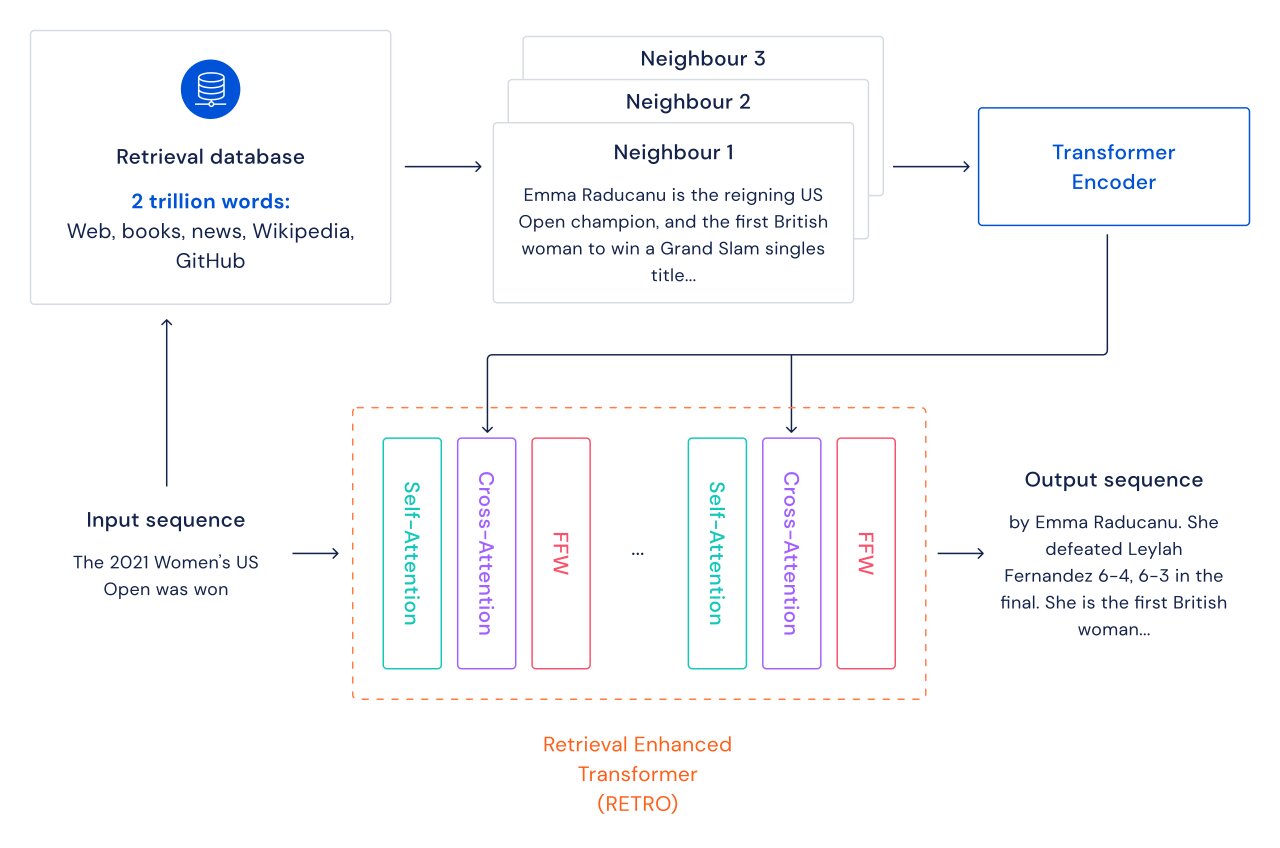
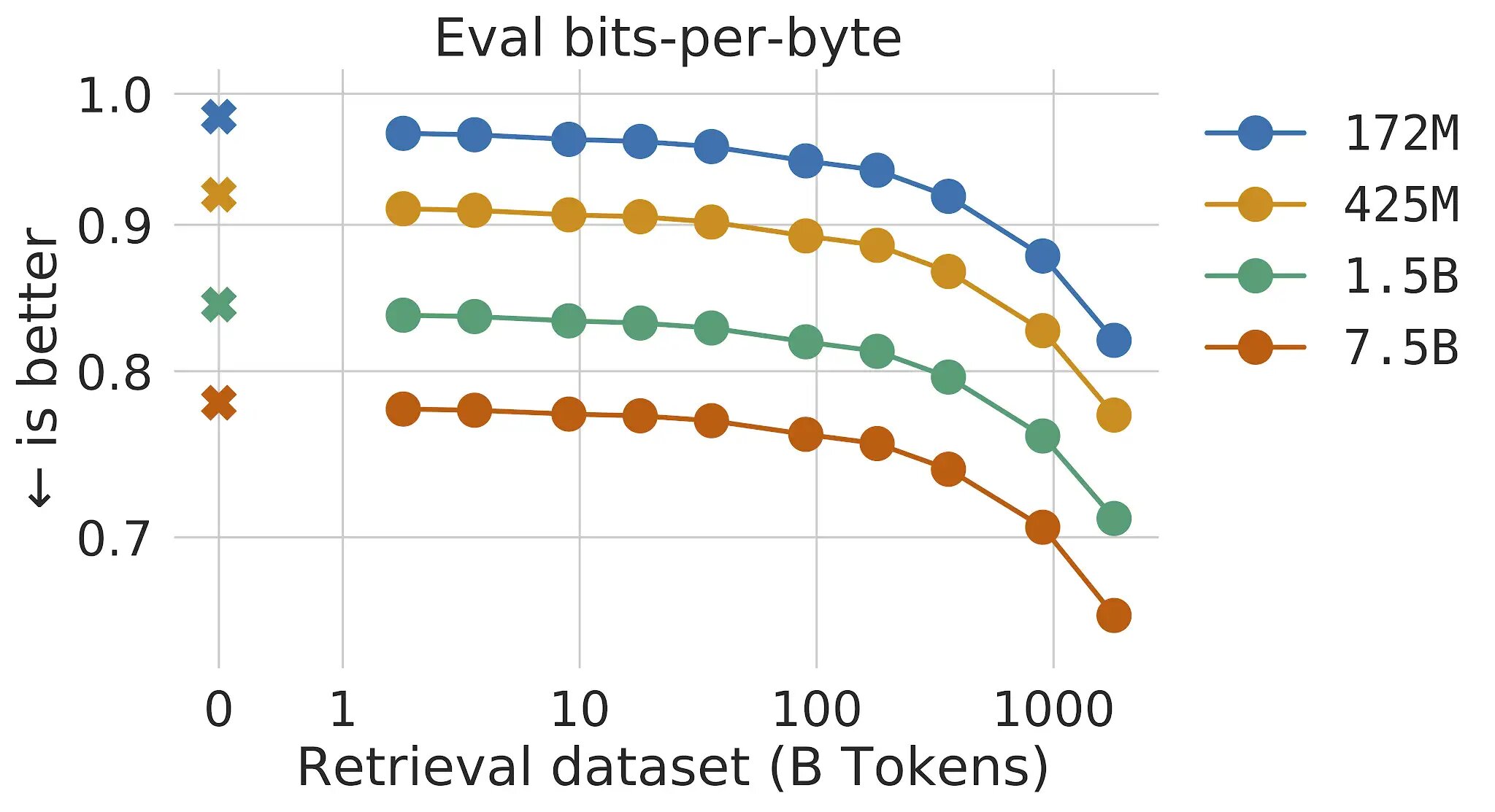
In conventional transformer language fashions, the advantages of mannequin measurement and information measurement are linked: so long as the dataset is giant sufficient, language modeling efficiency is proscribed by the dimensions of the mannequin. Nevertheless, with RETRO the mannequin is just not restricted to the information seen throughout coaching– it has entry to the whole coaching dataset via the retrieval mechanism. This leads to vital efficiency features in comparison with a typical Transformer with the identical variety of parameters. We present that language modeling improves constantly as we improve the dimensions of the retrieval database, at the least as much as 2 trillion tokens – 175 full lifetimes of steady studying.
For every textual content passage (roughly a paragraph of a doc), a nearest-neighbor search is carried out which returns comparable sequences discovered within the coaching database, and their continuation. These sequences assist predict the continuation of the enter textual content. The RETRO structure interleaves common self-attention at a doc stage and cross-attention with retrieved neighbors at a finer passage stage. This leads to each extra correct and extra factual continuations. Moreover, RETRO will increase the interpretability of mannequin predictions, and gives a route for direct interventions via the retrieval database to enhance the protection of textual content continuation. In our experiments on the Pile, a typical language modeling benchmark, a 7.5 billion parameter RETRO mannequin outperforms the 175 billion parameter Jurassic-1 on 10 out of 16 datasets and outperforms the 280B Gopher on 9 out of 16 datasets.
Beneath, we present two samples from our 7B baseline mannequin and from our 7.5B RETRO mannequin mannequin that spotlight how RETRO’s samples are extra factual and keep extra on subject than the baseline pattern.



