
PyTorch is a machine studying (ML) framework that’s extensively utilized by AWS clients for quite a lot of purposes, akin to laptop imaginative and prescient, pure language processing, content material creation, and extra. With the current PyTorch 2.0 launch, AWS clients can now do identical issues as they might with PyTorch 1.x however sooner and at scale with improved coaching speeds, decrease reminiscence utilization, and enhanced distributed capabilities. A number of new applied sciences together with torch.compile, TorchDynamo, AOTAutograd, PrimTorch, and TorchInductor have been included within the PyTorch2.0 launch. Discuss with PyTorch 2.0: Our next generation release that is faster, more Pythonic and Dynamic as ever for particulars.
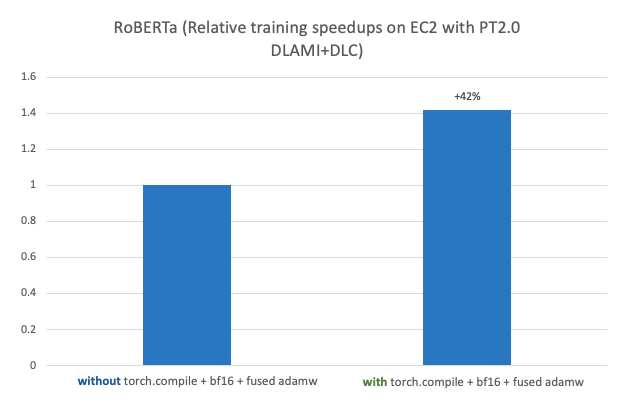
This publish demonstrates the efficiency and ease of operating large-scale, high-performance distributed ML mannequin coaching and deployment utilizing PyTorch 2.0 on AWS. This publish additional walks via a step-by-step implementation of fine-tuning a RoBERTa (Robustly Optimized BERT Pretraining Strategy) mannequin for sentiment evaluation utilizing AWS Deep Learning AMIs (AWS DLAMI) and AWS Deep Learning Containers (DLCs) on Amazon Elastic Compute Cloud (Amazon EC2 p4d.24xlarge) with an noticed 42% speedup when used with PyTorch 2.0 torch.compile + bf16 + fused AdamW. The fine-tuned mannequin is then deployed on AWS Graviton-based C7g EC2 occasion on Amazon SageMaker with an noticed 10% speedup in comparison with PyTorch 1.13.
The next determine exhibits a efficiency benchmark of fine-tuning a RoBERTa mannequin on Amazon EC2 p4d.24xlarge with AWS PyTorch 2.0 DLAMI + DLC.
Discuss with Optimized PyTorch 2.0 inference with AWS Graviton processors for particulars on AWS Graviton-based occasion inference efficiency benchmarks for PyTorch 2.0.
Help for PyTorch 2.0 on AWS
PyTorch2.0 help will not be restricted to the companies and compute proven in instance use-case on this publish; it extends to many others on AWS, which we talk about on this part.
Enterprise requirement
Many AWS clients, throughout a various set of industries, are reworking their companies through the use of synthetic intelligence (AI), particularly within the space of generative AI and huge language fashions (LLMs) which can be designed to generate human-like textual content. These are mainly massive fashions primarily based on deep studying strategies which can be educated with a whole lot of billions of parameters. The expansion in mannequin sizes is rising coaching time from days to weeks, and even months in some circumstances. That is driving an exponential improve in coaching and inference prices, which requires, greater than ever, a framework akin to PyTorch 2.0 with built-in help of accelerated mannequin coaching and the optimized infrastructure of AWS tailor-made to the particular workloads and efficiency wants.
Selection of compute
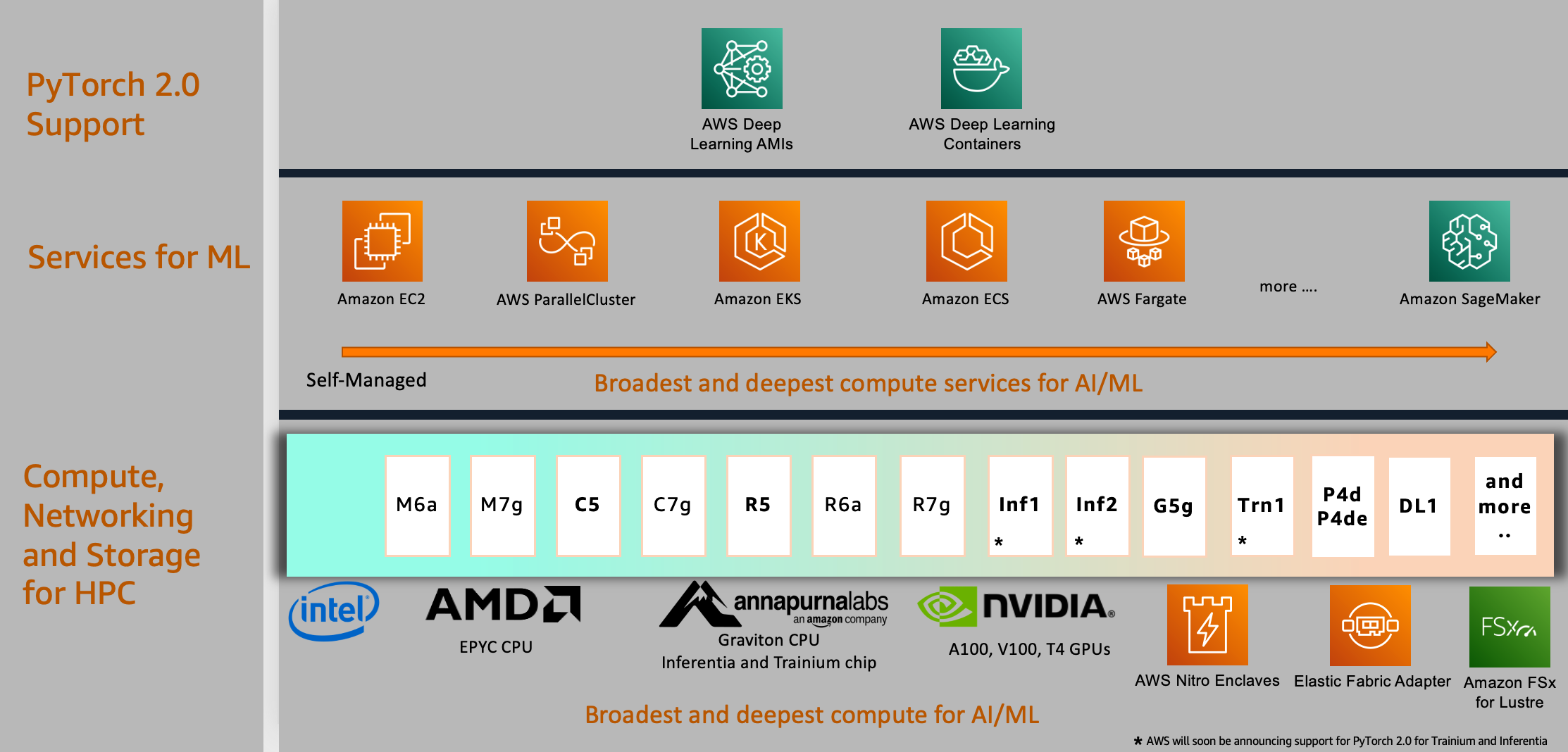
AWS supplies PyTorch 2.0 help on the broadest alternative of highly effective compute, high-speed networking, and scalable high-performance storage choices that you should utilize for any ML venture or utility and customise to suit your efficiency and price range necessities. That is manifested within the diagram within the subsequent part; within the backside tier, we offer a broad choice of compute cases powered by AWS Graviton, Nvidia, AMD, and Intel processors.
For mannequin deployments, you should utilize ARM-based processors such because the not too long ago introduced AWS Graviton-based occasion that gives inference efficiency for PyTorch 2.0 with as much as 3.5 instances the pace for Resnet50 in comparison with the earlier PyTorch launch, and as much as 1.4 instances the pace for BERT, making AWS Graviton-based cases the quickest compute-optimized cases on AWS for CPU-based mannequin inference options.
Selection of ML companies
To make use of AWS compute, you possibly can choose from a broad set of worldwide cloud-based companies for ML growth, compute, and workflow orchestration. This alternative means that you can align with your corporation and cloud methods and run PyTorch 2.0 jobs on the platform of your alternative. For example, in case you have on-premises restrictions or present investments in open-source merchandise, you should utilize Amazon EC2, AWS ParallelCluster, or AWS UltraCluster to run distributed coaching workloads primarily based on a self-managed method. You might additionally use a totally managed service like SageMaker for a cost-optimized, totally managed, and production-scale coaching infrastructure. SageMaker additionally integrates with varied MLOps instruments, which lets you scale your mannequin deployment, cut back inference prices, handle fashions extra successfully in manufacturing, and cut back operational burden.
Equally, in case you have present Kubernetes investments, you may also use Amazon Elastic Kubernetes Service (Amazon EKS) and Kubeflow on AWS to implement an ML pipeline for distributed coaching or use an AWS-native container orchestration service like Amazon Elastic Container Service (Amazon ECS) for mannequin coaching and deployments. Choices to construct your ML platform usually are not restricted to those companies; you possibly can choose and select relying in your organizational necessities on your PyTorch 2.0 jobs.
Enabling PyTorch 2.0 with AWS DLAMI and AWS DLC
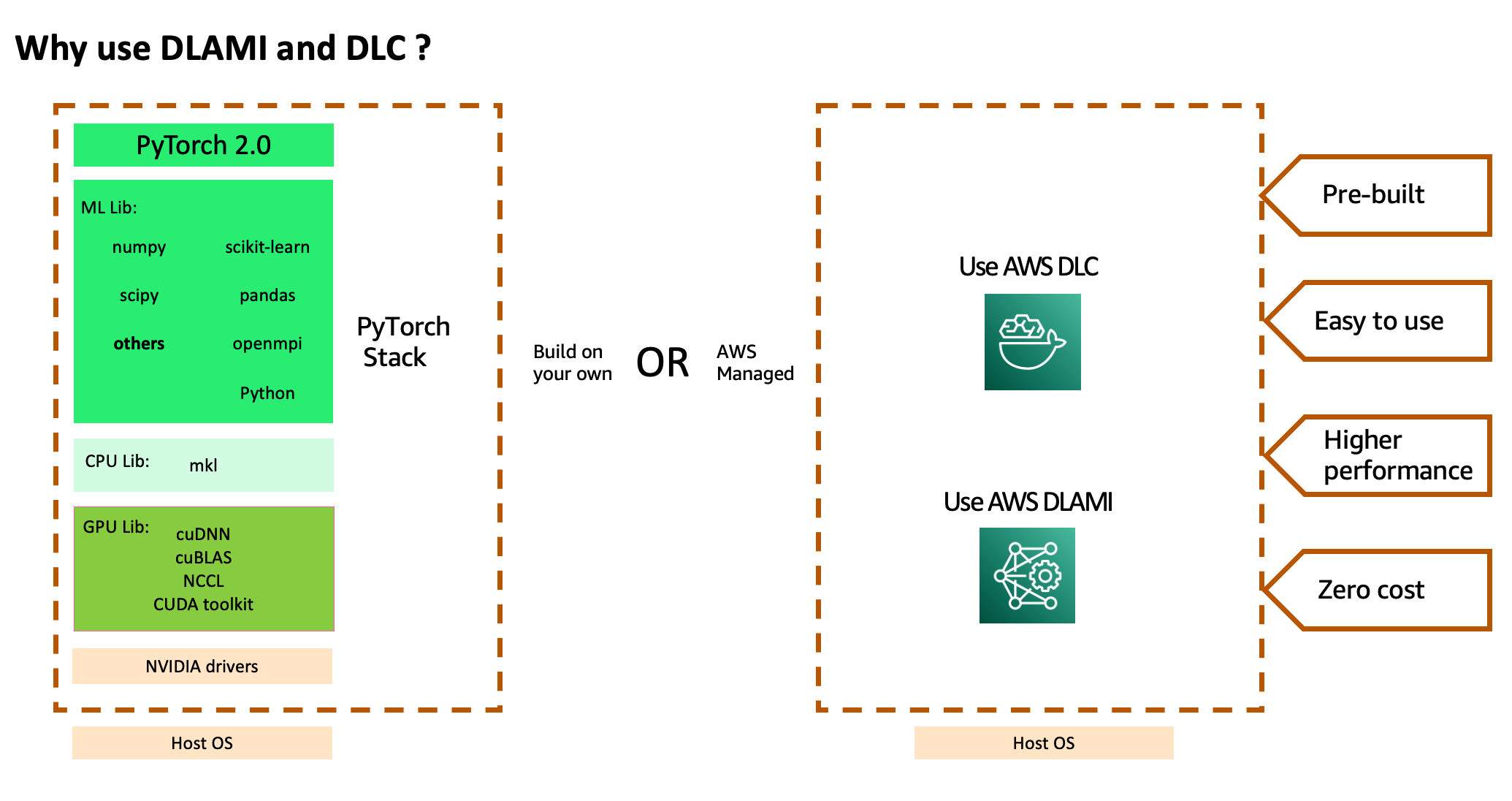
To make use of the aforementioned stack of AWS companies and highly effective compute, you need to set up an optimized compiled model of the PyTorch2.0 framework and its required dependencies, lots of that are unbiased tasks, and check them finish to finish. You may additionally want CPU-specific libraries for accelerated math routines, GPU-specific libraries for accelerated math and inter-GPU communication routines, and GPU drivers that have to be aligned with the GPU compiler used to compile the GPU libraries. In case your jobs require large-scale multi-node coaching, you want an optimized community that may present lowest latency and highest throughput. After you construct your stack, it’s essential to frequently scan and patch them for safety vulnerabilities and rebuild and retest the stack after each framework model improve.
AWS helps cut back this heavy lifting by providing a curated and safe set of frameworks, dependencies, and instruments to speed up deep studying within the cloud although AWS DLAMIs and AWS DLCs. These pre-built and examined machine photos and containers are optimized for deep studying on EC2 Accelerated Computing Occasion sorts, permitting you to scale out to a number of nodes for distributed workloads extra effectively and simply. It features a pre-built Elastic Fabric Adapter (EFA), Nvidia GPU stack, and plenty of deep studying frameworks (TensorFlow, MXNet, and PyTorch with newest launch of two.0) for high-performance distributed deep studying coaching. You don’t have to spend time putting in and troubleshooting deep studying software program and drivers or constructing ML infrastructure, nor do you need to incur the recurring price of patching these photos for safety vulnerabilities or recreating the pictures after each new framework model improve. As an alternative, you possibly can deal with the upper value-added effort of coaching jobs at scale in a shorter period of time and iterating in your ML fashions sooner.
Answer overview
Contemplating that coaching on GPU and inference on CPU is a well-liked use case for AWS clients, we’ve got included as a part of this publish a step-by-step implementation of a hybrid structure (as proven within the following diagram). We’ll discover the art-of-the-possible and use a P4 EC2 occasion with BF16 help initialized with Base GPU DLAMI together with NVIDIA drivers, CUDA, NCCL, EFA stack, and PyTorch2.0 DLC for fine-tuning a RoBERTa sentiment evaluation mannequin that provides you management and suppleness to make use of any open-source or proprietary libraries. Then we use SageMaker for a totally managed mannequin internet hosting infrastructure to host our mannequin on AWS Graviton3-based C7g instances. We picked C7g on SageMaker as a result of it’s confirmed to scale back inference prices by as much as 50% relative to comparable EC2 cases for real-time inference on SageMaker. The next diagram illustrates this structure.
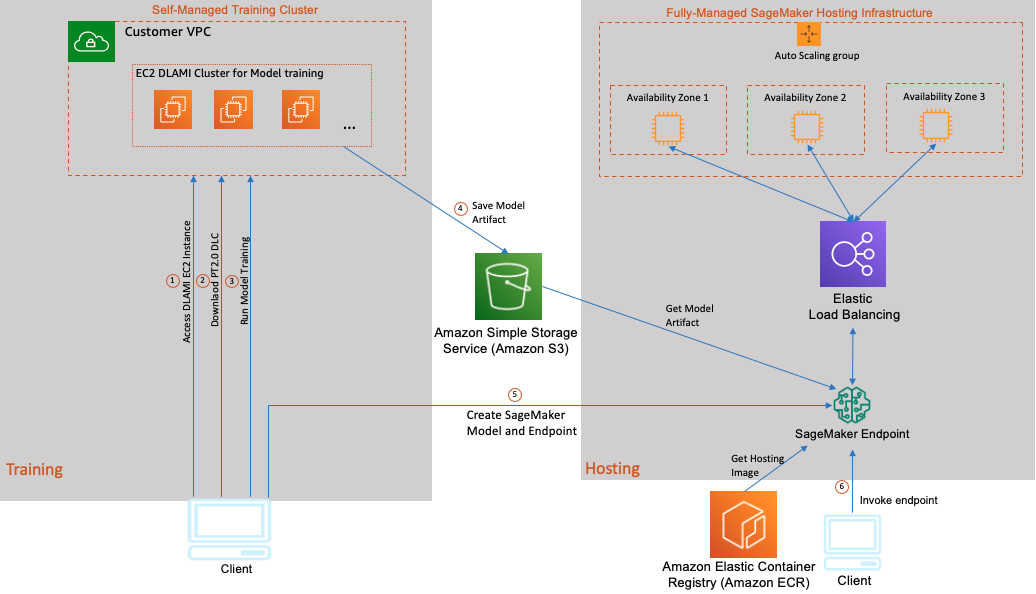
The mannequin coaching and internet hosting on this use case consists of the next steps:
- Launch a GPU DLAMI-based EC2 Ubuntu occasion in your VPC and hook up with your occasion utilizing SSH.
- After you log in to your EC2 occasion, obtain the AWS PyTorch 2.0 DLC.
- Run your DLC container with a mannequin coaching script to fine-tune the RoBERTa mannequin.
- After mannequin coaching is full, package deal the saved mannequin, inference scripts, and some metadata recordsdata right into a tar file that SageMaker inference can use and add the mannequin package deal to an Amazon Simple Storage Service (Amazon S3) bucket.
- Deploy the mannequin utilizing SageMaker and create an HTTPS inference endpoint. The SageMaker inference endpoint holds a load balancer and a number of cases of your inference container in several Availability Zones. You may deploy both a number of variations of the identical mannequin or fully completely different fashions behind this single endpoint. On this instance, we host a single mannequin.
- Invoke your mannequin endpoint by sending it check knowledge and confirm the inference output.
Within the following sections, we showcase fine-tuning a RoBERTa mannequin for sentiment evaluation. RoBERTa is developed by Fb AI, bettering on the favored BERT mannequin by modifying key hyperparameters and pre-training on a bigger corpus. This results in improved efficiency in comparison with vanilla BERT.
We use the transformers library by Hugging Face to get the RoBERTa mannequin pre-trained on roughly 124 million tweets, and we fine-tune it on the Twitter dataset for sentiment evaluation.
Conditions
Be sure you meet the next conditions:
- You might have an AWS account.
- Be sure you’re within the
us-west-2Area to run this instance. (This instance is examined inus-west-2; nevertheless, you possibly can run in another Area.) - Create a role with the identify
sagemakerrole. Add managed insurance policiesAmazonSageMakerFullAccessandAmazonS3FullAccessto offer SageMaker entry to S3 buckets. - Create an EC2 role with the identify
ec2_role. Use the next permission coverage:
1. Launch your growth occasion
We create a p4d.24xlarge occasion that gives 8 NVIDIA A100 Tensor Core GPUs in us-west-2:
When choosing the AMI, comply with the release notes to run this command utilizing the AWS Command Line Interface (AWS CLI) to seek out the AMI ID to make use of in us-west-2:
Be certain that the dimensions of the gp3 root quantity is 200 GiB.
EBS quantity encryption will not be enabled by default. Contemplate altering this when shifting this answer to manufacturing.
2. Obtain a Deep Studying Container
AWS DLCs can be found as Docker photos in Amazon Elastic Container Registry Public, a managed AWS container picture registry service that’s safe, scalable, and dependable. Every Docker picture is constructed for coaching or inference on a selected deep studying framework model, Python model, with CPU or GPU help. Choose the PyTorch 2.0 framework from the checklist of accessible Deep Learning Containers images.
Full the next steps to obtain your DLC:
a. SSH to the occasion. By default, safety group used with EC2 opens up SSH port to all. Please contemplate this in case you are shifting this answer to manufacturing:
By default, the safety group used with Amazon EC2 opens up the SSH port to all. Contemplate altering this in case you are shifting this answer to manufacturing.
b. Set the surroundings variables required to run the remaining steps of this implementation:
Amazon ECR helps public picture repositories with resource-based permissions utilizing AWS Identity and Access Management (IAM) in order that particular customers or companies can entry photos.
c. Log in to the DLC registry:
d. Pull the most recent PyTorch 2.0 container with GPU help in us-west-2
When you get the error “no house left on machine”, be sure you increase the EC2 EBS quantity to 200 GiB after which extend the Linux file system.
3. Clone the most recent scripts tailored to PyTorch 2.0
Clone the scripts with the next code:
As a result of we’re utilizing the Hugging Face transformers API with the most recent model 4.28.1, it has already enabled PyTorch 2.0 help. We added the next argument to the coach API in train_sentiment.py to allow new PyTorch 2.0 options:
- Torch compile – Expertise a median 43% speedup on Nvidia A100 GPUs with single line of change.
- BF16 datatype – New knowledge sort help (Mind Floating Level) for Ampere or newer GPUs.
- Fused AdamW optimizer – Fused AdamW implementation to additional pace up coaching. This stochastic optimization technique modifies the standard implementation of weight decay in Adam by decoupling weight decay from the gradient replace.
4. Construct a brand new Docker picture with dependencies
We lengthen the pre-built PyTorch 2.0 DLC picture to put in the Hugging Face transformer and different libraries that we have to fine-tune our mannequin. This lets you use the included examined and optimized deep studying libraries and settings with out having to create a picture from scratch. See the next code:
5. Begin coaching utilizing the container
Run the next Docker command to start fine-tuning the mannequin on the tweet_eval sentiment dataset. We’re utilizing the Docker container arguments (shared reminiscence measurement, max locked reminiscence, and stack measurement) recommend by Nvidia for deep studying workloads.
You need to anticipate the next output. The script first downloads the TweetEval dataset, which consists of seven heterogenous duties in Twitter, all framed as multi-class tweet classification. The duties embody irony, hate, offensive, stance, emoji, emotion, and sentiment.
The script then downloads the bottom mannequin and begins the fine-tuning course of. Coaching and analysis metrics are reported on the finish of every epoch.
Efficiency statistics
With PyTorch 2.0 and the most recent Hugging Face transformers library 4.28.1, we noticed a 42% speedup on a single p4d.24xlarge occasion with 8 A100 40GB GPUs. Efficiency enhancements comes from a mixture of torch.compile, the BF16 knowledge sort, and the fused AdamW optimizer. The next code is the ultimate results of two coaching runs with and with out new options:
6. Take a look at the educated mannequin domestically earlier than making ready for SageMaker inference
You’ll find the next recordsdata beneath $ml_working_dir/saved_model/ after coaching:
Let’s be sure that we will run inference domestically earlier than making ready for SageMaker inference. We will load the saved mannequin and run inference domestically utilizing the test_trained_model.py script:
You need to anticipate the next output with the enter “Covid circumstances are rising quick!”:
7. Put together the mannequin tarball for SageMaker inference
Underneath the listing the place the mannequin is positioned, make a brand new listing referred to as code:
Within the new listing, create the file inference.py and add the next to it:
Ultimately, it’s best to have the next folder construction:
The mannequin is able to be packaged and uploaded to Amazon S3 to be used with SageMaker inference:
8. Deploy the mannequin on a SageMaker AWS Graviton occasion
New generations of CPUs supply a major efficiency enchancment in ML inference attributable to specialised built-in directions. On this use case, we use the SageMaker totally managed internet hosting infrastructure with AWS Graviton3-based C7g cases. AWS has additionally measured as much as a 50% price financial savings for PyTorch inference with AWS Graviton3-based EC2 C7g cases throughout Torch Hub ResNet50, and a number of Hugging Face fashions relative to comparable EC2 cases.
To deploy the fashions to AWS Graviton cases, we use AWS DLCs that present help for PyTorch 2.0 and TorchServe 0.8.0, or you possibly can bring your own containers which can be appropriate with the ARMv8.2 structure.
We use the mannequin we educated earlier: s3://<your-s3-bucket>/twitter-roberta-base-sentiment-latest.tar.gz. When you haven’t used SageMaker earlier than, assessment Get Started with Amazon SageMaker.
To begin, be sure that the SageMaker package deal is updated:
As a result of that is an instance, create a file referred to as start_endpoint.py and add the next code. This would be the Python script to start out a SageMaker inference endpoint with the mode:
We’re utilizing ml.c7g.4xlarge for the occasion and are retrieving PT 2.0 with a picture scope inference_graviton. That is our AWS Graviton3 occasion.
Subsequent, we create the file that runs the prediction. We do these as separate scripts so we will run the predictions as many instances as we wish. Create predict.py with the next code:
With the scripts generated, we will now begin an endpoint, do predictions towards the endpoint, and clear up once we’re achieved:
9. Clear up
Lastly, we need to clear up from this instance. Create cleanup.py and add the next code:
Conclusion
AWS DLAMIs and DLCs have change into the go-to customary for operating deep studying workloads on a broad choice of compute and ML companies on AWS. Together with utilizing framework-specific DLCs on AWS ML companies, you may also use a single framework on Amazon EC2, which removes the heavy lifting mandatory for builders to construct and keep deep studying purposes. Discuss with Release Notes for DLAMI and Available Deep Learning Containers Images to get began.
This publish confirmed one in every of many potentialities to coach and serve your subsequent mannequin on AWS and mentioned a number of codecs that you could undertake to fulfill your corporation aims. Give this instance a attempt or use our different AWS ML companies to broaden the info productiveness for your corporation. We now have included a easy sentiment evaluation downside in order that clients new to ML can perceive how easy it’s to get began with PyTorch 2.0 on AWS. We shall be masking extra superior use circumstances, fashions, and AWS applied sciences in upcoming weblog posts.
In regards to the authors
 Kanwaljit Khurmi is a Principal Options Architect at Amazon Net Providers. He works with the AWS clients to supply steerage and technical help serving to them enhance the worth of their options when utilizing AWS. Kanwaljit makes a speciality of serving to clients with containerized and machine studying purposes.
Kanwaljit Khurmi is a Principal Options Architect at Amazon Net Providers. He works with the AWS clients to supply steerage and technical help serving to them enhance the worth of their options when utilizing AWS. Kanwaljit makes a speciality of serving to clients with containerized and machine studying purposes.
 Mike Schneider is a Methods Developer, primarily based in Phoenix AZ. He’s a member of Deep Studying containers, supporting varied Framework container photos, to incorporate Graviton Inference. He’s devoted to infrastructure effectivity and stability.
Mike Schneider is a Methods Developer, primarily based in Phoenix AZ. He’s a member of Deep Studying containers, supporting varied Framework container photos, to incorporate Graviton Inference. He’s devoted to infrastructure effectivity and stability.
 Lai Wei is a Senior Software program Engineer at Amazon Net Providers. He’s specializing in constructing straightforward to make use of, high-performance and scalable deep studying frameworks for accelerating distributed mannequin coaching. Outdoors of labor, he enjoys spending time along with his household, mountain climbing, and snowboarding.
Lai Wei is a Senior Software program Engineer at Amazon Net Providers. He’s specializing in constructing straightforward to make use of, high-performance and scalable deep studying frameworks for accelerating distributed mannequin coaching. Outdoors of labor, he enjoys spending time along with his household, mountain climbing, and snowboarding.
