
Many current successes in language fashions (LMs) have been achieved inside a ‘static paradigm’, the place the main focus is on enhancing efficiency on the benchmarks which are created with out contemplating the temporal facet of information. As an illustration, answering questions on occasions that the mannequin may study throughout coaching, or evaluating on textual content sub-sampled from the identical interval because the coaching information. Nevertheless, our language and information are dynamic and ever evolving. Due to this fact, to allow a extra practical analysis of question-answering fashions for the following leap in efficiency, it’s important to make sure they’re versatile and sturdy when encountering new and unseen information.
In 2021, we launched Mind the Gap: Assessing Temporal Generalization in Neural Language Models and the dynamic language modelling benchmarks for WMT and arXiv to facilitate language mannequin analysis that take temporal dynamics under consideration. On this paper, we highlighted points that present state-of-the-art giant LMs face with temporal generalisation and located that knowledge-intensive tokens take a substantial efficiency hit.
In the present day, we’re releasing two papers and a brand new benchmark that additional advance analysis on this matter. In StreamingQA: A Benchmark for Adaptation to New Knowledge over Time in Question Answering Models, we examine the downstream job of question-answering on our newly proposed benchmark, StreamingQA: we wish to perceive how parametric and retrieval-augmented, semi-parametric question-answering fashions adapt to new info, to be able to reply questions on new occasions. In Internet-augmented language models through few-shot prompting for open-domain question answering, we discover the facility of mixing a few-shot prompted giant language mannequin together with Google Search as a retrieval element. In doing so, we intention to enhance the mannequin’s factuality, whereas ensuring it has entry to up-to-date info for answering a various set of questions.
StreamingQA: A Benchmark for Adaptation to New Information over Time in Query Answering Fashions
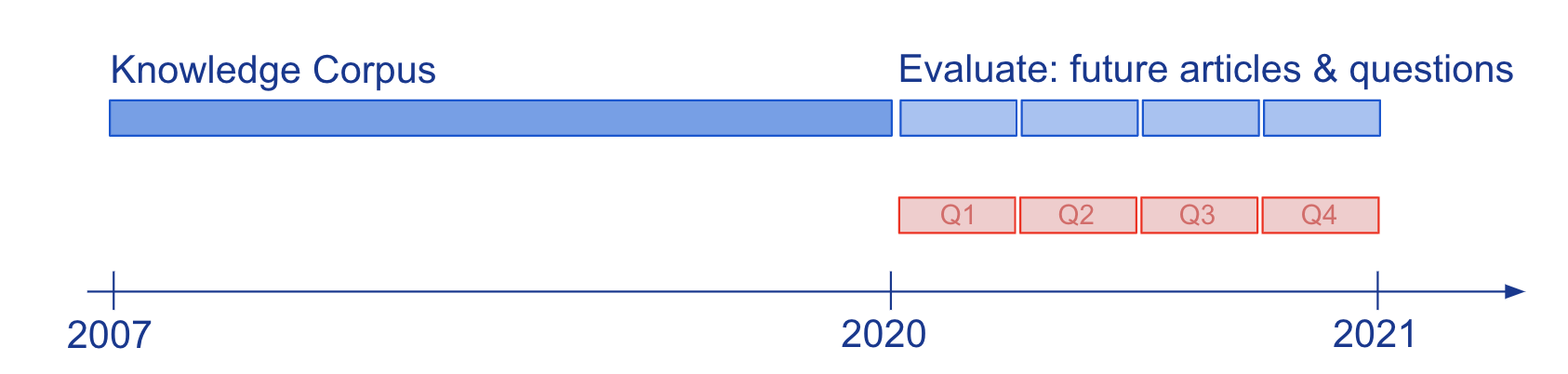
Information and language understanding of fashions evaluated by question-answering (QA) has been generally studied on static snapshots of information, like Wikipedia. To check how semi-parametric QA fashions and their underlying parametric LMs adapt to evolving information, we constructed the brand new large-scale benchmark, StreamingQA, with human-written and routinely generated questions requested on a given date, to be answered from 14 years of time-stamped information articles (see Determine 2). We present that parametric fashions could be up to date with out full retraining, whereas avoiding catastrophic forgetting. For semi-parametric fashions, including new articles into the search house permits for speedy adaptation, nevertheless, fashions with an outdated underlying LM underperform these with a retrained LM.

Web-augmented language fashions by few-shot prompting for open-domain question-answering
We’re aiming to capitalise on the distinctive few-shot capabilities supplied by large-scale language fashions to beat a few of their challenges, with respect to grounding to factual and up-to-date info. Motivated by semi-parametric LMs, which floor their selections in externally retrieved proof, we use few-shot prompting to study to situation LMs on info returned from the net utilizing Google Search, a broad and continually up to date information supply. Our strategy doesn’t contain fine-tuning or studying extra parameters, thus making it relevant to nearly any language mannequin. And certainly, we discover that LMs conditioned on the net surpass the efficiency of closed-book fashions of comparable, and even bigger, mannequin dimension in open-domain question-answering.

