
Total, the high-level objectives of Acme are as follows:
- To allow the reproducibility of our strategies and outcomes — it will assist make clear what makes an RL drawback onerous or simple, one thing that’s seldom obvious.
- To simplify the best way we (and the neighborhood at massive) design new algorithms — we would like that subsequent RL agent to be simpler for everybody to write down!
- To boost the readability of RL brokers — there needs to be no hidden surprises when transitioning from a paper to code.
With the intention to allow these objectives, the design of Acme additionally bridges the hole between large-, medium-, and small-scale experiments. We now have accomplished so by rigorously occupied with the design of brokers at many alternative scales.
On the highest degree, we will consider Acme as a classical RL interface (present in any introductory RL textual content) which connects an actor (i.e. an action-selecting agent) to an setting. This actor is an easy interface which has strategies for choosing actions, making observations, and updating itself. Internally, studying brokers additional break up the issue up into an “appearing” and a “studying from information” element. Superficially, this permits us to re-use the appearing parts throughout many alternative brokers. Nevertheless, extra importantly this gives a vital boundary upon which to separate and parallelize the educational course of. We are able to even scale down from right here and seamlessly assault the batch RL setting the place there exists no setting and solely a set dataset. Illustrations of those completely different ranges of complexity are proven beneath:
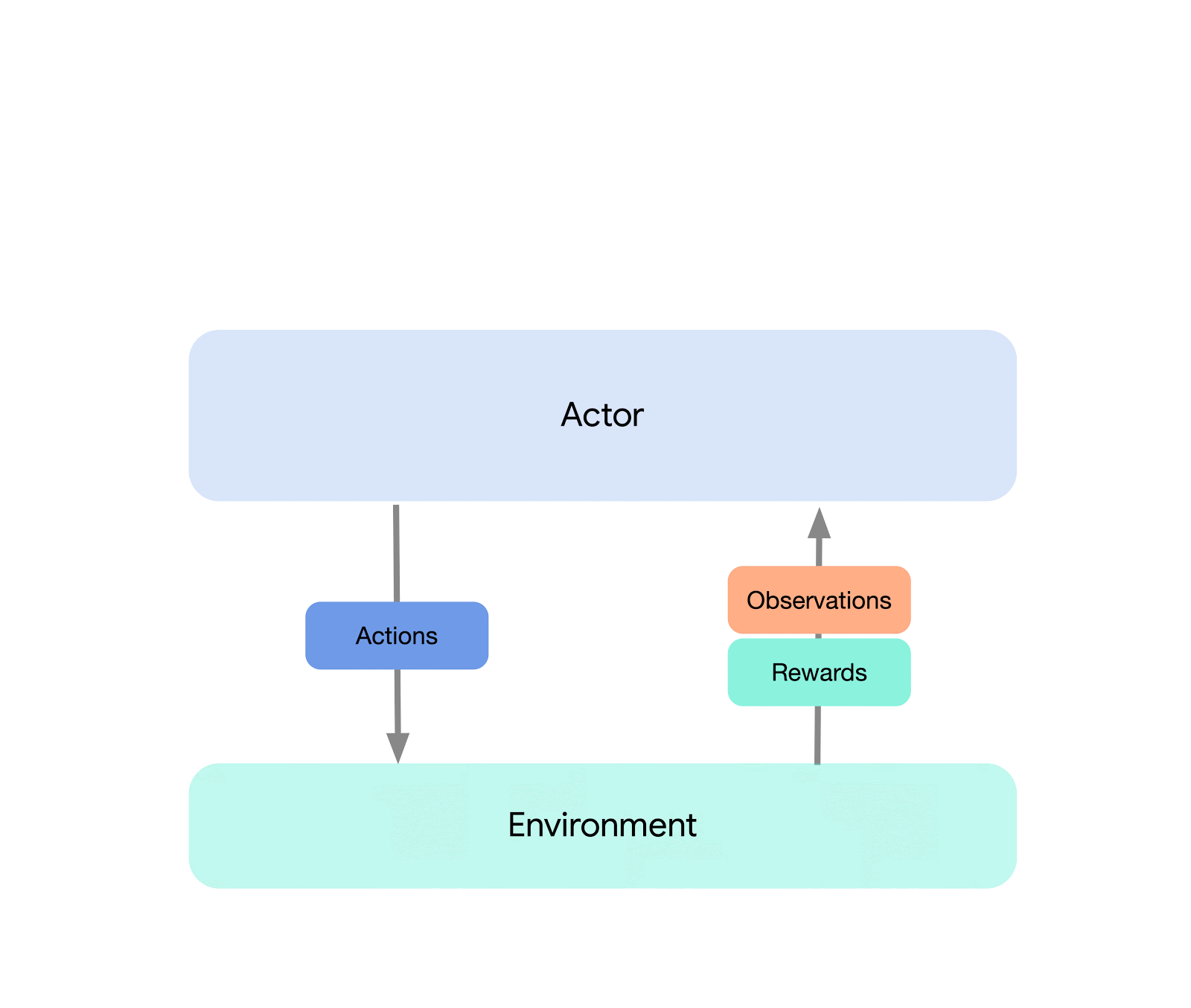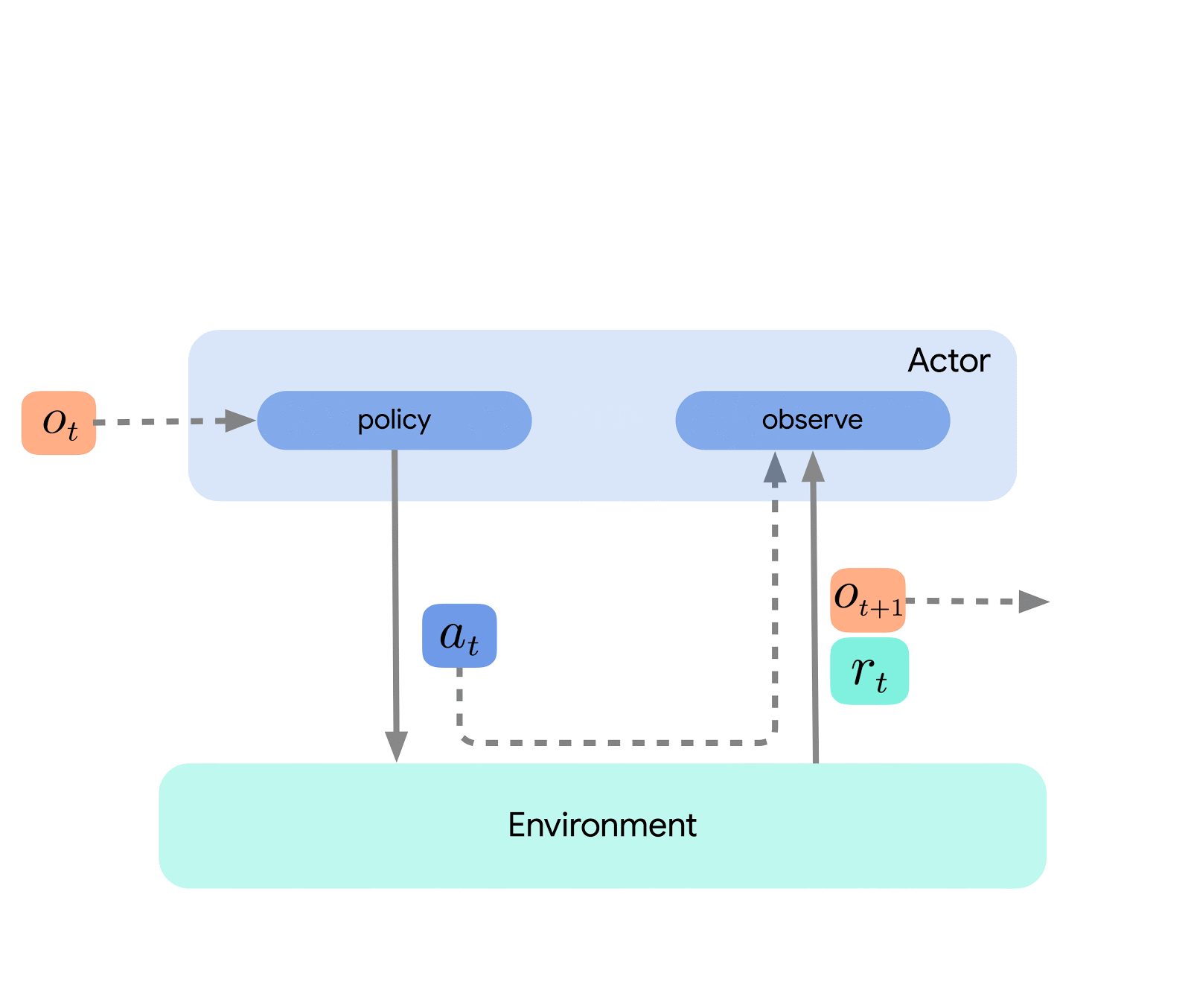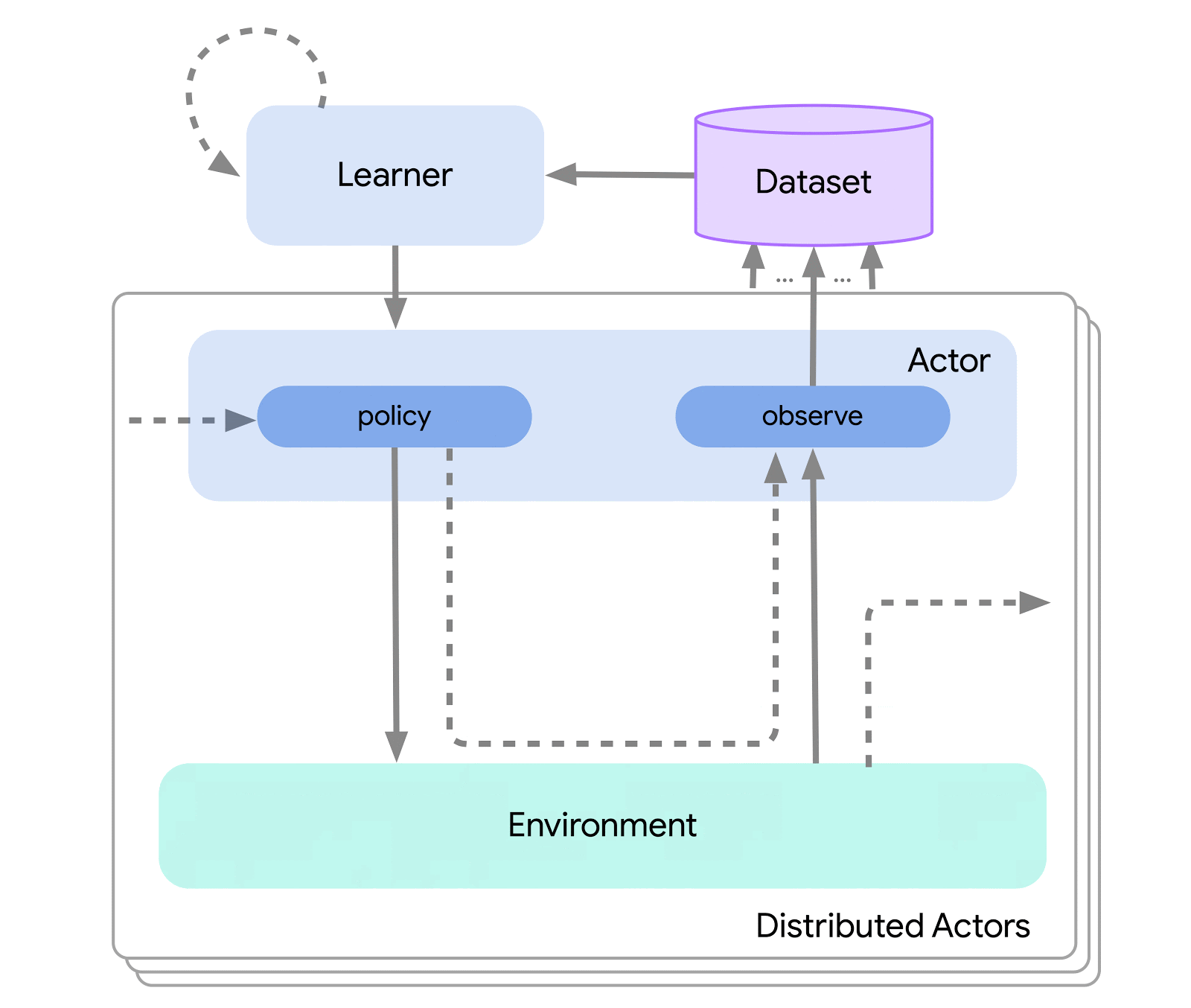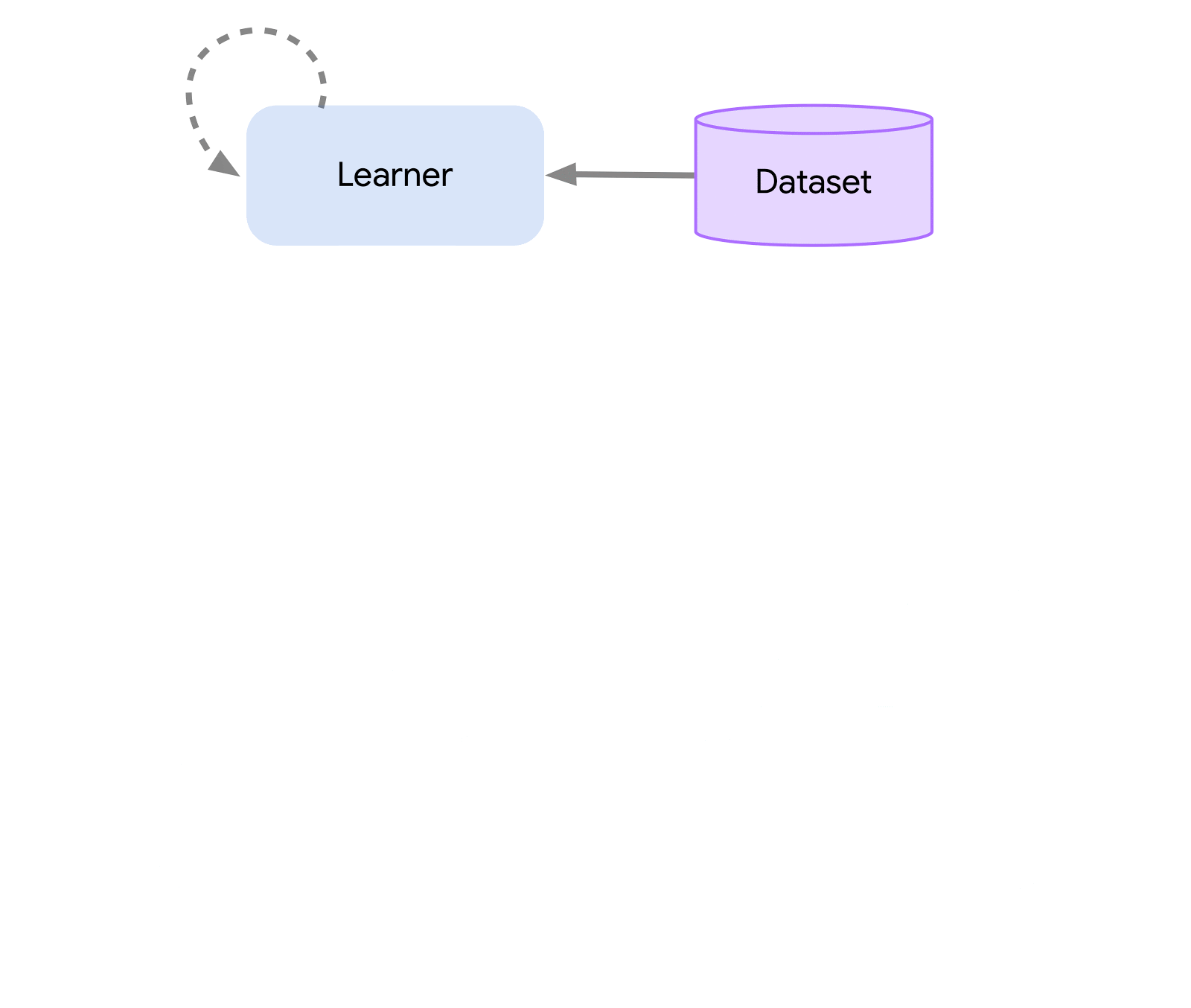
This design permits us to simply create, check, and debug novel brokers in small-scale situations earlier than scaling them up — all whereas utilizing the identical appearing and studying code. Acme additionally gives numerous helpful utilities from checkpointing, to snapshotting, to low-level computational helpers. These instruments are sometimes the unsung heroes of any RL algorithm, and in Acme we attempt to maintain them as easy and comprehensible as potential.
To allow this design Acme additionally makes use of Reverb: a novel, environment friendly information storage system goal constructed for machine studying (and reinforcement studying) information. Reverb is primarily used as a system for expertise replay in distributed reinforcement studying algorithms, however it additionally helps different information construction representations equivalent to FIFO and precedence queues. This permits us to make use of it seamlessly for on- and off-policy algorithms. Acme and Reverb have been designed from the start to play properly with each other, however Reverb can also be totally usable by itself, so go test it out!
Together with our infrastructure, we’re additionally releasing single-process instantiations of numerous brokers now we have constructed utilizing Acme. These run the gamut from steady management (D4PG, MPO, and so forth.), discrete Q-learning (DQN and R2D2), and extra. With a minimal variety of adjustments — by splitting throughout the appearing/studying boundary — we will run these similar brokers in a distributed method. Our first launch focuses on single-process brokers as these are those largely utilized by college students and analysis practitioners.
We now have additionally rigorously benchmarked these brokers on numerous environments, particularly the control suite, Atari, and bsuite.
Playlist of movies exhibiting brokers skilled utilizing Acme framework
Whereas extra outcomes are available in our paper, we present a number of plots evaluating the efficiency of a single agent (D4PG) when measured towards each actor steps and wall clock time for a steady management job. Because of the method by which we restrict the speed at which information is inserted into replay — discuss with the paper for a extra in-depth dialogue — we will see roughly the identical efficiency when evaluating the rewards an agent receives versus the variety of interactions it has taken with the setting (actor steps). Nevertheless, because the agent is additional parallelised we see features by way of how briskly the agent is ready to be taught. On comparatively small domains, the place the observations are constrained to small characteristic areas, even a modest enhance on this parallelisation (4 actors) ends in an agent that takes below half the time to be taught an optimum coverage:

However for much more advanced domains the place the observations are pictures which are comparatively pricey to generate we see way more intensive features:

And the features might be even larger nonetheless for domains equivalent to Atari video games the place the info is dearer to gather and the educational processes usually take longer. Nevertheless, it is very important notice that these outcomes share the identical appearing and studying code between each the distributed and non-distributed setting. So it’s completely possible to experiment with these brokers and outcomes at a smaller scale — in reality that is one thing we do on a regular basis when growing novel brokers!
For a extra detailed description of this design, together with additional outcomes for our baseline brokers, see our paper. Or higher but, check out our GitHub repository to see how one can begin utilizing Acme to simplify your personal brokers!
