
Introduction
The Adam optimizer is an algorithm utilized in deep studying that helps enhance the accuracy of neural networks by adjusting the mannequin’s learnable parameters. It was first launched in 2014 and is an extension of the stochastic gradient descent (SGD) algorithm. The identify “Adam” stands for Adaptive Second Estimation, which refers to its adaptive studying price and second estimation capabilities. It’s an extension of the favored stochastic gradient descent algorithm, which is used for updating the weights of a neural community. By analyzing the historic gradients, Adam can regulate the training price for every parameter in real-time, leading to quicker convergence and higher efficiency. Total, the Adam optimizer is a strong instrument for enhancing the accuracy and velocity of deep studying fashions.
The Adam (Adaptive Second Estimation) optimizer is a well-liked optimization algorithm in machine studying, notably in deep studying purposes. It combines the advantages of two different optimization strategies – Momentum and Adaptive Gradient Algorithm (AdaGrad) – to offer an environment friendly and adaptive replace of mannequin parameters. By computing each first-order momentum (shifting common of gradients) and second-order second (shifting common of squared gradients) of the loss operate, Adam adjusts the training price for every parameter individually, guaranteeing a easy and quick convergence. This optimization method has gained reputation due to its adaptive studying charges, robustness to noise, and suitability for dealing with sparse gradients, making it a go-to alternative for coaching numerous machine studying fashions, together with neural networks.
What Are Optimizers in Deep Studying?
Optimizers are a key element in deep studying that assist enhance the accuracy and effectivity of neural networks. In layman’s phrases, optimizers are algorithms that regulate the learnable parameters of a neural community to be able to decrease the error or value operate throughout coaching.
Throughout coaching, the neural community is fed enter knowledge and produces output predictions, that are then in comparison with the precise goal values. The distinction between the anticipated output and the precise goal worth is named the loss or value operate. The optimizer’s job is to reduce this loss operate by adjusting the community’s parameters.
There are a number of forms of optimizers utilized in deep studying, together with the favored stochastic gradient descent (SGD) algorithm, in addition to extra superior optimizers like Adam and AdaGrad. These optimizers use totally different strategies to regulate the parameters of the neural community, resembling adaptive studying charges and momentum.
The aim of an optimizer is to assist the neural community converge quicker and extra precisely by discovering the optimum set of parameters that decrease the fee operate. That is achieved by adjusting the weights and biases of the neural community in a method that reduces the error between the anticipated and precise values.
Optimizers may assist forestall overfitting, which is a standard drawback in deep studying the place the neural community turns into too advanced and begins to memorize the coaching knowledge as an alternative of studying to generalize to new knowledge.
Total, optimizers play a crucial function in deep studying by serving to neural networks study and enhance their accuracy over time. By utilizing the precise optimizer and adjusting its parameters, builders will help their neural networks obtain higher efficiency and quicker convergence throughout coaching.
Additionally Learn: Introduction to XGBoost and its Uses in Machine Learning
What’s Adam Optimizer?
The Adam optimizer is a well-liked algorithm utilized in deep studying that helps regulate the parameters of a neural community in real-time to enhance its accuracy and velocity. Adam stands for Adaptive Second Estimation, which implies that it adapts the training price of every parameter based mostly on its historic gradients and momentum.
In easy phrases, Adam makes use of a mix of adaptive studying charges and momentum to make changes to the community’s parameters throughout coaching. This helps the neural community study quicker and converge extra shortly in direction of the optimum set of parameters that decrease the fee or loss operate.
Adam is understood for its quick convergence and talent to work nicely on noisy and sparse datasets. It may possibly additionally deal with issues the place the optimum answer lies in a variety of parameter values.
Total, the Adam optimizer is a strong instrument for enhancing the accuracy and velocity of deep studying fashions. By analyzing the historic gradients and adjusting the training price for every parameter in real-time, Adam will help the neural community converge quicker and extra precisely throughout coaching.

Adam is Efficient
Sure, the Adam optimizer is taken into account to be efficient for deep studying purposes. It has been proven to carry out nicely on a variety of datasets and will help neural networks converge quicker and extra precisely throughout coaching.
One of many fundamental benefits of Adam is its skill to deal with noisy and sparse datasets, that are frequent in real-world purposes. It may possibly additionally deal with issues the place the optimum answer lies in a variety of parameter values.
Research have proven that Adam can usually outperform different optimization strategies, resembling stochastic gradient descent and its variants, by way of convergence velocity and generalization to new knowledge. Nonetheless, the optimum alternative of optimizer might rely on the precise dataset and drawback being solved.
Total, the Adam optimizer is a strong instrument for enhancing the accuracy and velocity of deep studying fashions. Its adaptive studying price and momentum-based strategy will help the neural community study quicker and converge extra shortly in direction of the optimum set of parameters that decrease the fee or loss operate.
Adam Configuration Parameters
The Adam optimizer has a number of configuration parameters that may be adjusted to enhance the efficiency of a deep studying mannequin. Listed below are a number of the fundamental Adam configuration parameters defined:
- Studying price: This parameter controls how a lot the mannequin’s parameters are up to date throughout every coaching step. A excessive studying price may end up in massive updates to the mannequin’s parameters, which may trigger the optimization course of to develop into unstable. Alternatively, a low studying price may end up in gradual convergence and should require extra coaching steps to succeed in the optimum set of parameters.
- Beta1 and Beta2: These parameters management the exponential decay charges for the primary and second second estimates of the gradient, respectively. In different phrases, they assist the optimizer preserve monitor of the historic gradients for every parameter throughout coaching.
- Epsilon: This parameter is used to keep away from dividing by zero when calculating the replace rule. It’s a small worth added to the denominator of the replace rule to make sure numerical stability.
- Weight decay: This can be a regularization time period that may be added to the fee operate throughout coaching to forestall overfitting. It penalizes massive values of the mannequin’s parameters, which will help enhance generalization to new knowledge.
- Batch measurement: This parameter controls what number of coaching examples are utilized in every coaching step. A bigger batch measurement may end up in quicker convergence, however may improve reminiscence necessities and decelerate the coaching course of.
- Max epochs: This parameter determines the utmost variety of coaching epochs or iterations that will probably be carried out throughout coaching. It helps forestall overfitting and might enhance the generalization of the mannequin to new knowledge.
Total, adjusting these configuration parameters will help enhance the efficiency and accuracy of a deep studying mannequin skilled utilizing the Adam optimizer. By fine-tuning these parameters, builders can obtain quicker convergence and higher generalization to new knowledge
The Adam Algorithm for Stochastic Optimization
The Adam optimizer is an algorithm used for stochastic optimization in deep studying. It’s designed to enhance the efficiency of gradient-based optimization strategies, resembling stochastic gradient descent.
The algorithm works by sustaining two shifting averages of the gradient and its sq., that are used to estimate the primary and second moments of the gradient. These estimates are then used to regulate the training price and weight replace vectors throughout coaching.
Throughout every coaching step, the algorithm calculates the gradient of the fee or loss operate with respect to every parameter within the mannequin. It then updates the shifting averages and calculates the adaptive studying price for every parameter.
The burden replace vector is then calculated by combining the adaptive studying price with the present gradient estimate and making use of a momentum-based replace rule. The ensuing replace vector is then used to replace the mannequin’s parameters and transfer them nearer to the optimum set of values that decrease the fee or loss operate.
Total, the Adam algorithm is an efficient and environment friendly methodology for optimizing deep studying fashions. Its adaptive studying price and momentum-based strategy will help the mannequin converge quicker and extra precisely in direction of the optimum set of parameters that decrease the fee or loss operate.
Visible Comparability Between Optimizers
Some fashionable optimization strategies are stochastic gradient descent (SGD), momentum, Nesterov accelerated gradient (NAG), AdaGrad, AdaDelta, and RMSprop.
SGD is a straightforward optimization methodology that updates the mannequin parameters based mostly on the gradient of the fee operate with respect to the parameters. It’s a fashionable alternative due to its simplicity, however it may be gradual to converge and might get caught in native minima.
Momentum optimization is a variant of SGD that provides a momentum time period to the parameter updates. This helps the optimizer speed up in direction of the minimal and overcome small gradients or noise within the knowledge. Nonetheless, it may possibly additionally get caught in saddle factors or oscillate across the minimal.
NAG is one other variant of momentum optimization that makes use of a “look-ahead” technique to estimate the gradient of the fee operate on the subsequent step. This will help the optimizer keep away from overshooting the minimal and result in quicker convergence. Nonetheless, it may possibly additionally endure from oscillation or instability.
AdaGrad is an optimization methodology that adapts the training price for every parameter based mostly on its historic gradients. This helps the optimizer make smaller updates to parameters which were often up to date and bigger updates to parameters that haven’t. Nonetheless, it may possibly additionally endure from a gradual convergence price and an extreme lower within the studying price over time.
AdaDelta is a variant of AdaGrad that makes use of an exponential decay price to regulate the adaptive studying price. This helps overcome the lowering studying price drawback of AdaGrad and might result in quicker convergence. Nonetheless, it may be slower than different optimizers within the early phases of coaching.
RMSprop is an optimization methodology that makes use of a shifting common of the squared gradients to adapt the training price for every parameter. This helps the optimizer overcome the gradual convergence of AdaGrad and might deal with non-stationary issues. Nonetheless, it may possibly additionally endure from excessive reminiscence necessities and instability in some circumstances.
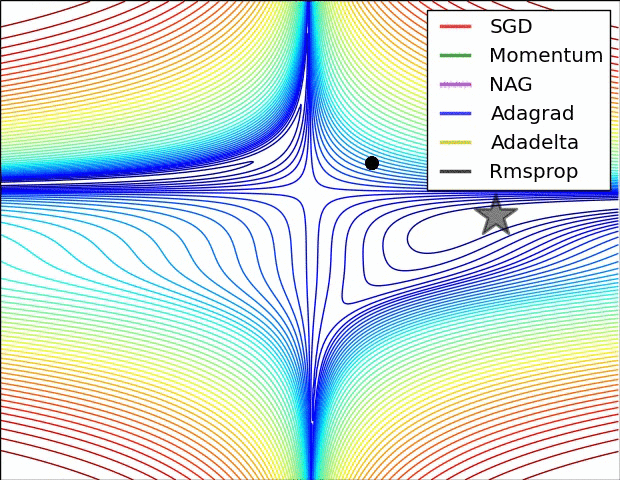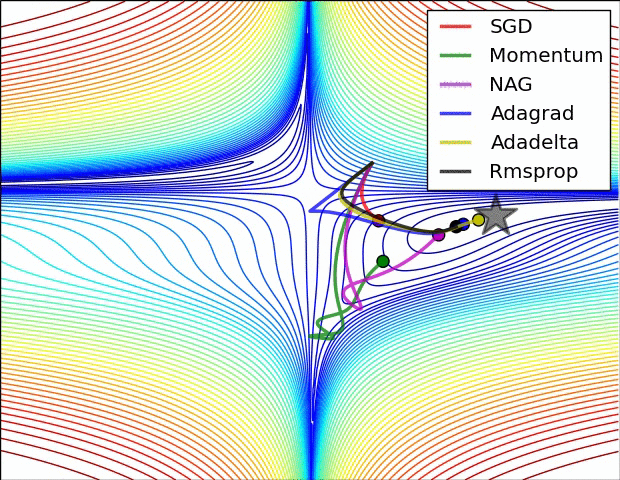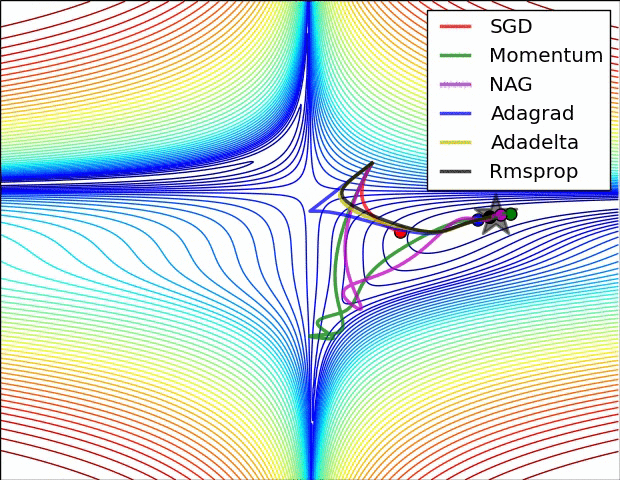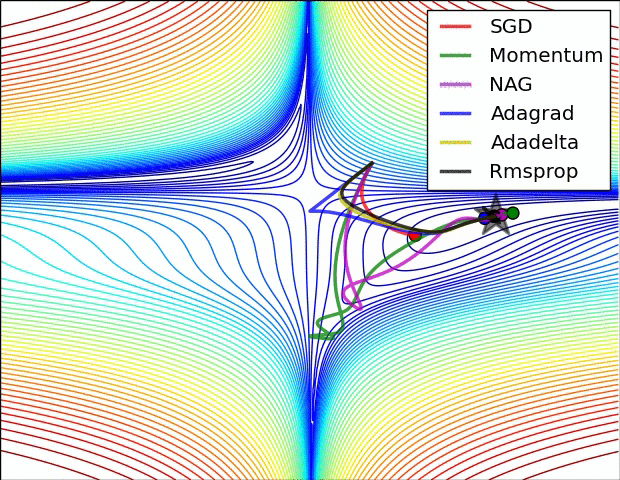
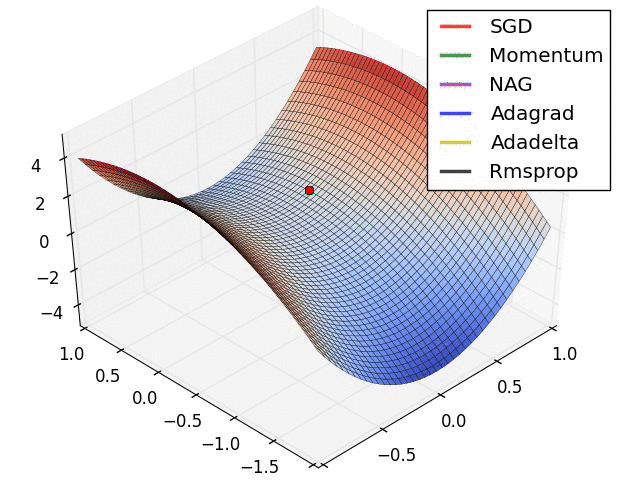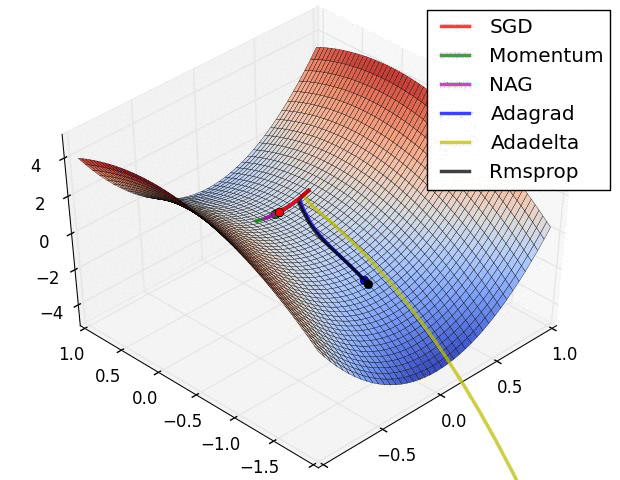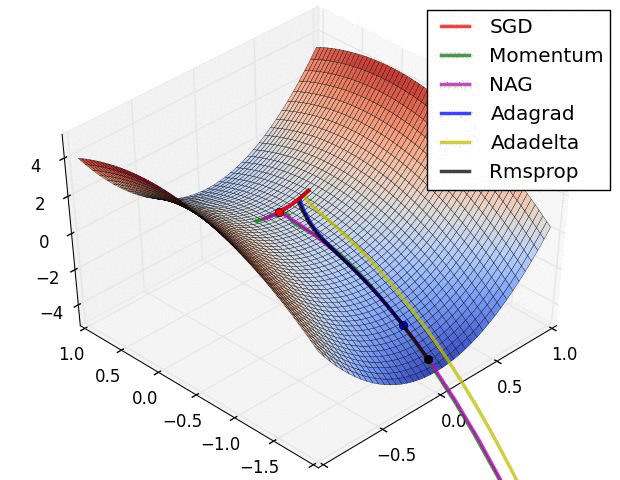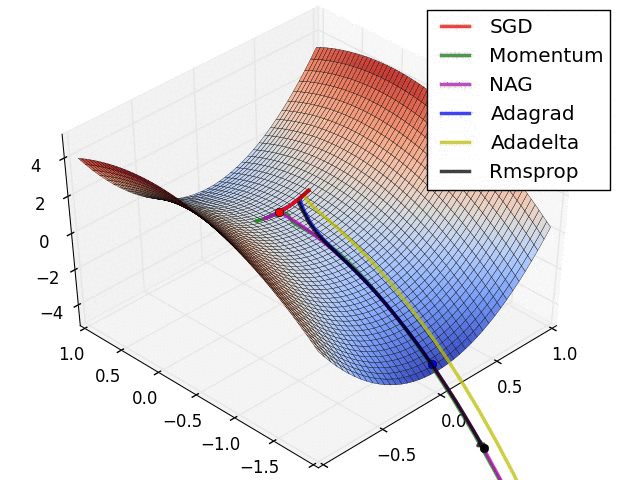
Total, the selection of optimizer will depend on the precise dataset and drawback being solved. Every optimizer has its personal strengths and weaknesses and should carry out in a different way on several types of knowledge. You will need to check totally different optimizers and examine their efficiency on the coaching and validation datasets earlier than selecting one of the best one for the precise deep studying utility.
Implementation
Implementation of optimizers in deep studying requires defining the optimizer and setting its hyper-parameters, resembling studying price, momentum, decay charges, and batch sizes. These hyper-parameters decide how the optimizer updates the weights and biases of the neural community throughout coaching.
To implement an optimizer, first, the optimizer object must be created and handed to the coaching algorithm. The coaching algorithm then makes use of the optimizer to compute the gradients of the fee operate with respect to the weights and biases, and updates them accordingly.
The hyper-parameters of the optimizer will be set manually or will be tuned routinely utilizing strategies resembling grid search or random search. The educational price is crucial hyper-parameter and determines how briskly or gradual the optimizer ought to study. The next studying price can result in quicker convergence, however can also trigger the optimizer to overshoot the minimal and result in unstable habits. A decrease studying price can result in slower convergence, however can also result in a extra secure optimizer.
Batch measurement is one other essential hyper-parameter that determines what number of coaching examples are utilized in every weight replace. A bigger batch measurement can result in quicker convergence and extra secure gradients, however may require extra reminiscence and computation time. A smaller batch measurement can result in slower convergence and noisier gradients, however can require much less reminiscence and computation time.
Implementation of optimizers additionally entails monitoring the coaching and validation loss throughout coaching to make sure that the mannequin is enhancing and never overfitting. Numerous metrics resembling coaching accuracy, validation accuracy, and loss line plots can be utilized to evaluate the efficiency of the optimizer.
Total, implementing an optimizer requires setting the hyper-parameters, monitoring the coaching and validation loss, and adjusting the hyper-parameters as needed to make sure one of the best efficiency of the deep studying mannequin.
Adam optimizer in PyTorch
In PyTorch, the Adam optimizer is applied as a part of the torch.optim module. To make use of the Adam optimizer for coaching a mannequin, you must import the optimizer and create an occasion by passing the mannequin’s parameters and the specified studying price. Right here’s a easy instance:
import torch
import torch.nn as nn
from torch.optim import Adam
# Outline your mannequin (a easy neural community, for instance)
class SimpleNet(nn.Module):
def __init__(self):
tremendous(SimpleNet, self).__init__()
self.fc1 = nn.Linear(784, 128)
self.fc2 = nn.Linear(128, 10)
def ahead(self, x):
x = torch.relu(self.fc1(x))
x = self.fc2(x)
return x
# Create an occasion of the mannequin
mannequin = SimpleNet()
# Initialize the Adam optimizer with the mannequin's parameters and a studying price
optimizer = Adam(mannequin.parameters(), lr=0.001)After initializing the optimizer, you should utilize it within the coaching loop to replace the mannequin’s parameters. For instance:
# Coaching loop
for epoch in vary(num_epochs):
for batch_data, batch_labels in data_loader:
# Zero the gradients
optimizer.zero_grad()
# Ahead move
outputs = mannequin(batch_data)
# Calculate loss
loss = loss_function(outputs, batch_loss)Benefits and Disadvantages of Adam Optimizer
The Adam optimizer has a number of benefits over different optimization algorithms in deep studying. First, it has adaptive studying charges that regulate based mostly on the gradient magnitude, which makes it appropriate for a variety of issues and architectures. This adaptive studying price additionally permits the optimizer to converge quicker and extra precisely, even in noisy or sparse datasets.
One other benefit of the Adam optimizer is that it may possibly deal with massive and sophisticated datasets with out overfitting or getting caught in native minima. It’s because it makes use of a decaying common of the previous gradients, which ensures that the optimizer all the time strikes within the related route and avoids oscillations.
Furthermore, the Adam optimizer has a low reminiscence requirement, because it solely must retailer the primary and second moments of the gradient, which makes it extra reminiscence environment friendly than different optimization algorithms. This additionally makes it appropriate for coaching deep studying fashions on restricted assets, resembling cellular gadgets or edge gadgets.
Nonetheless, there are additionally some disadvantages to utilizing the Adam optimizer. One drawback is that it may be delicate to the preliminary studying price and different hyper-parameters, which may have an effect on the convergence and stability of the optimizer. As well as, the adaptive second estimation utilized by the Adam optimizer can result in poor convergence in sure circumstances, particularly when the coaching knowledge is very redundant.
One other drawback of the Adam optimizer is that it may possibly overfit in some circumstances, particularly when the dataset is small or the mannequin has a lot of learnable parameters. This may be mitigated by utilizing regularization strategies or lowering the training price throughout coaching.
Total, the Adam optimizer has many benefits and is extensively utilized in deep studying purposes, however you will need to perceive its limitations and use it appropriately in several contexts.
Additionally Learn: How to Use Linear Regression in Machine Learning
Conclusion
In conclusion, the Adam optimizer is a well-liked and efficient optimization algorithm for coaching deep studying fashions. It has a number of benefits over different optimization algorithms, resembling adaptive studying charges, low reminiscence necessities, and quicker convergence. These benefits make it appropriate for a variety of issues and architectures, and it’s extensively utilized in deep studying purposes.
Nonetheless, the Adam optimizer additionally has some limitations and drawbacks that should be considered when utilizing it. These embrace sensitivity to hyper-parameters, poor convergence in sure circumstances, and potential for overfitting. To mitigate these limitations, you will need to tune the hyper-parameters fastidiously and use applicable regularization strategies throughout coaching.
On the whole, the selection of optimization algorithm will depend on the precise drawback and structure getting used, and totally different optimization algorithms might have totally different strengths and weaknesses in several contexts. Due to this fact, you will need to experiment with totally different optimization algorithms and examine their efficiency to seek out one of the best one for a given job.
In abstract, the Adam optimizer is a strong instrument for optimizing deep studying fashions, however you will need to use it appropriately and perceive its strengths and limitations. By fastidiously tuning the hyper-parameters and utilizing applicable regularization strategies, the Adam optimizer is usually a extremely efficient instrument for coaching deep studying fashions and attaining excessive accuracy on a variety of duties.

References
Alabdullatef, Layan. “Full Information to Adam Optimization.” In the direction of Information Science, 2 Sept. 2020, https://towardsdatascience.com/complete-guide-to-adam-optimization-1e5f29532c3d. Accessed 28 Mar. 2023.
Brownlee, Jason. “Light Introduction to the Adam Optimization Algorithm for Deep Studying.” MachineLearningMastery.Com, 2 July 2017, https://machinelearningmastery.com/adam-optimization-algorithm-for-deep-learning/. Accessed 28 Mar. 2023.
Gupta, Ayush. “Optimizers in Deep Studying: A Complete Information.” Analytics Vidhya, 7 Oct. 2021, https://www.analyticsvidhya.com/blog/2021/10/a-comprehensive-guide-on-deep-learning-optimizers/. Accessed 28 Mar. 2023.
“Instinct of Adam Optimizer.” GeeksforGeeks, 22 Oct. 2020, https://www.geeksforgeeks.org/intuition-of-adam-optimizer/ Accessed 28 Mar. 2023.

