Remodeling Information Pipelines with OpenAI’s Perform Calling Function: Implementing an E-mail Sending Workflow Utilizing PostgreSQL and FastAPI
The thrilling world of AI has taken one other leap ahead by the introduction of perform calling capabilities in OpenAI’s newest Giant Language Fashions (LLMs). This new function enhances the interplay between people and AI, reworking it from a easy question-and-answer format to a extra dynamic and lively dialogue.
However what precisely are these perform calling capabilities? At their core, they permit the LLM to name predefined features throughout a dialog primarily based on the enter directions. This might be something from sending an e mail to fetching knowledge from a database primarily based on the context of the dialog.
The advantages and functions of utilizing perform calling capabilities are huge. It considerably will increase the dynamic utility of AI in varied functions, from customer support to how we construct knowledge pipelines.
Think about a customer support AI that may reply questions and carry out actions reminiscent of reserving appointments, sending data to an e mail handle, or updating buyer particulars in actual time. Or contemplate a knowledge pipeline the place the LLM agent can fetch, replace, and manipulate knowledge on command.
Within the upcoming sections, we’ll discover these functions additional and supply a step-by-step information on leveraging this new functionality by constructing an email-sending pipeline.
As all the time, the code is accessible on my Github.
We wish to perceive what OpenAI’s newly launched perform calling function brings to the AI race. For that, let’s perceive what differentiates it from different instruments and frameworks out there, like LangChain. We already launched LangChain within the first article of this sequence. It’s a common framework for growing AI-powered functions. The perform calling function and LangChain carry distinctive benefits and capabilities to the desk and are constructed round making AI extra usable, versatile, and dynamic.
We already know that the perform calling function provides an additional layer of interactivity to AI functions. It allows the mannequin to name predefined features inside a dialog, enhancing the LLM’s dynamism and reactivity. This new function can probably simplify the method of including performance to AI functions. Builders would want to outline these features, and the mannequin may then execute them as a part of the dialog, relying on the context. The first benefit right here is its direct integration with the OpenAI fashions, which facilitates ease of use, fast setup, and a decrease studying curve for builders aware of the OpenAI ecosystem.
Then again, LangChain gives a complete and versatile framework designed for growing extra complicated, data-aware, and agentic AI functions. It permits a language mannequin to work together with its atmosphere and make choices primarily based on high-level directives. Its modules present abstractions and customary interfaces for constructing functions, together with fashions, prompts, reminiscence, indexes, chains, brokers, and callbacks.
LangChain’s strategy facilitates constructing functions the place an LLM can persist its state throughout completely different interactions, sequence and chain calls to completely different utilities, and even work together with exterior knowledge sources. We are able to see these as perform calling capabilities on steroids. Thus, it’s notably helpful for builders constructing complicated, multi-step functions that leverage language fashions. The draw back of the added complexity is that it creates a steeper studying curve to make use of it totally.
In my opinion, knowledge pipelines are among the many most enjoyable utility areas for the brand new perform calling capabilities in LLMs. Information pipelines are a vital element of any data-driven group that collects, processes, and distributes knowledge. Sometimes, these processes are static, predefined, and require guide intervention for any modifications or updates. That is the place the dynamic conduct of an LLM that we mentioned above creates a possibility.
Historically, database querying requires particular data of question languages like SQL. With LLMs’ capability to name features, companies, and databases straight, customers can retrieve knowledge conversationally with out the necessity for specific question formulation. An LLM may translate a consumer’s request right into a database question, fetch the info, and return it in a user-friendly format, all in actual time. This function may democratize knowledge entry throughout completely different roles inside a corporation.
One other side that would change is knowledge transformation. It typically requires separate knowledge cleansing and processing steps earlier than evaluation. An LLM may streamline this course of by performing knowledge cleansing and manipulation duties interactively primarily based on the consumer’s directions. Furthermore, manipulating real-time knowledge throughout a dialog permits for extra exploratory and iterative knowledge evaluation.
A 3rd use case is knowledge monitoring. It entails common checks to make sure the accuracy and consistency of information in a knowledge pipeline. With LLMs, monitoring duties can turn out to be extra interactive and environment friendly. As an illustration, an LLM can alert customers to knowledge inconsistencies throughout conversations and take corrective actions instantly.
Lastly, the LLMs may automate the creation and distribution of information studies. Customers can instruct the LLM to generate a report primarily based on particular standards, and the LLM can fetch the info, create the report, and even ship it to the related recipients.
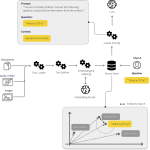
We purpose to create a pipeline that sends an e mail to a consumer. Whereas this may occasionally sound easy, the great thing about this course of lies within the interaction of the completely different elements managed by the LLM. The AI mannequin doesn’t merely generate an e mail physique; it dynamically interacts with a database to retrieve consumer data, composes a contextually applicable e mail, after which instructs a service to ship it.
Our pipeline consists of three primary elements: PostgreSQL, FastAPI, and the OpenAI LLM. We use PostgreSQL to retailer our consumer knowledge. This knowledge contains consumer names and their related e mail addresses. It serves as our supply of fact for consumer data. FastAPI is a contemporary, high-performance net framework for constructing APIs with Python. We use a FastAPI service to simulate the method of sending an e mail. When the service receives a request to ship an e mail, it returns a response confirming the e-mail has been despatched. The LLM serves because the orchestrator of the complete course of. It controls the dialog, determines the required actions primarily based on the context, interacts with the PostgreSQL database to fetch consumer data, crafts an e mail message, and instructs the FastAPI service to ship the e-mail.
Implementing PostgreSQL Database
The primary element of our pipeline is the PostgreSQL database the place we retailer our consumer knowledge. Establishing a PostgreSQL occasion is made simple and reproducible with Docker, a platform that enables us to containerize and isolate our database atmosphere.
You first want to put in Docker to arrange a PostgreSQL Docker container. As soon as put in, you possibly can pull the PostgreSQL picture and run it as a container. We map the container’s port 5432 to the host’s port 5432 to entry the database. In a manufacturing atmosphere, please set your password as an atmosphere variable and don’t set them straight in a command as beneath. We’re doing this technique to velocity up our course of.
docker run --name user_db -e POSTGRES_PASSWORD=testpass -p 5432:5432 -d postgres
With our PostgreSQL occasion working, we will now create a database and a desk to retailer our consumer knowledge. We’ll use an initialization script to create a customersdesk with username and e mailcolumns and populate it with some dummy knowledge. This script is positioned in a listing which is then mapped to the /docker-entrypoint-initdb.d listing within the container. PostgreSQL executes any scripts discovered on this listing upon startup. Right here’s what the script (user_init.sql) seems to be like:
CREATE DATABASE user_database;
c user_database;CREATE TABLE customers (
username VARCHAR(50),
e mail VARCHAR(50)
);
INSERT INTO customers (username, e mail) VALUES
('user1', '[email protected]'),
('user2', '[email protected]'),
('user3', '[email protected]'),
...
('user10', '[email protected]');
The LLM is able to understanding SQL instructions and can be utilized to question the PostgreSQL database. When the LLM receives a request that entails fetching consumer knowledge, it may well formulate a SQL question to fetch the required knowledge from the database.
As an illustration, in case you ask the LLM to ship an e mail to user10, the LLM can formulate the question :
SELECT e mail FROM customers WHERE username=’user10';
This permits it to fetch user10 e mail handle from the customers desk. The LLM can then use this e mail handle to instruct the FastAPI service to ship the e-mail.
Within the subsequent part, we’ll information you thru the implementation of the FastAPI service that sends the emails.
Creating the FastAPI E-mail Service
Our second element is a FastAPI service. This service will simulate the method of sending emails. It’s a simple API that receives a POST request containing the recipient’s title, e mail, and the e-mail physique. It can return a response confirming the e-mail was despatched. We’ll once more use Docker to make sure our service is remoted and reproducible.
First, it’s good to set up Docker (if not already put in). Then, create a brand new listing in your FastAPI service and transfer into it. Right here, create a brand new Python file (e.g., primary.py) and add the next code:
from fastapi import FastAPI
from pydantic import BaseModelapp = FastAPI()
class Person(BaseModel):
title: str
e mail: str
physique: str
@app.put up("/send_email")
async def send_email(consumer: Person):
return {
"message": f"E-mail efficiently despatched to {consumer.title} with e mail {consumer.e mail}. E-mail physique:nn{consumer.physique}"
}
This code defines a FastAPI utility with a single endpoint /send_email/. This endpoint accepts POST requests and expects a JSON physique containing the recipient’s title, e mail, and the e-mail physique.
Subsequent, create a Dockerfile in the identical listing with the next content material:
FROM python:3.9-slim-busterWORKDIR /app
ADD . /app
RUN pip set up --no-cache-dir fastapi uvicorn
EXPOSE 1000
CMD ["uvicorn", "app:app", "--host", "0.0.0.0", "--port", "1000"]
This Dockerfile instructs Docker to create a picture primarily based on thepython:3.9-slim-buster picture, a light-weight picture preferrred for effectively working python functions. It then copies our primary.py file into the /app/ listing within the picture.
You possibly can construct the Docker picture utilizing the command:
docker construct -t fastapi_email_service .
After which run it with:
docker run -d -p 1000:1000 fastapi_email_service
The LLM interacts with the FastAPI service utilizing a POST request. When the LLM decides to ship an e mail, it generates a perform name to the send_email perform. The arguments of this perform name include the title, e mail, and the e-mail physique.
The perform name is processed by our Python script, which extracts the perform arguments and makes use of them to ship a POST request to our FastAPI service. The FastAPI service responds with a message indicating the e-mail was efficiently despatched.
Now, we now have all elements of our pipeline. The subsequent part will tie every little thing collectively, explaining how the LLM orchestrates the interplay between the PostgreSQL database and the FastAPI service to ship an e mail.
Integrating with OpenAI LLM
The final piece of our pipeline is the OpenAI LLM integration. The LLM serves because the orchestrator, deciphering our instructions, querying the database for consumer data, and instructing the FastAPI service to ship emails.
Our script makes use of OpenAI’s API to make chat-based completions with the LLM. Every completion request consists of a sequence of messages and optionally an inventory of perform specs that the mannequin may name. We begin the dialog with a consumer message, which gives a immediate to the assistant.
Right here’s the chat_completion_request perform we use to ship a request to the API:
@retry(wait=wait_random_exponential(min=1, max=40), cease=stop_after_attempt(3))
def chat_completion_request(messages, features=None, mannequin=GPT_MODEL):
headers = {
"Content material-Kind": "utility/json",
"Authorization": "Bearer " + openai.api_key,
}
json_data = {"mannequin": mannequin, "messages": messages}
if features isn't None:
json_data.replace({"features": features})response = requests.put up(
"https://api.openai.com/v1/chat/completions",
headers=headers,
json=json_data,
)
return response
We use the Chat class to handle the dialog historical past. It has strategies so as to add a brand new message to the historical past and show the complete dialog:
class Chat:
def __init__(self):
self.conversation_history = []def add_prompt(self, position, content material):
message = {"position": position, "content material": content material}
self.conversation_history.append(message)
def display_conversation(self):
for message in self.conversation_history:
print(f"{message['role']}: {message['content']}")
In our use case, the LLM must work together with our PostgreSQL database and FastAPI service. We outline these features and embody them in our completion request. Right here’s how we outline our sql_query_email and send_emailfeatures:
features = [
{
"name": "send_email",
"description": "Send a new email",
"parameters": {
"type": "object",
"properties": {
"to": {
"type": "string",
"description": "The destination email.",
},
"name": {
"type": "string",
"description": "The name of the person that will receive the email.",
},
"body": {
"type": "string",
"description": "The body of the email.",
},
},
"required": ["to", "name", "body"],
},
},
{
"title": "sql_query_email",
"description": "SQL question to get consumer emails",
"parameters": {
"sort": "object",
"properties": {
"question": {
"sort": "string",
"description": "The question to get customers emails.",
},
},
"required": ["query"],
},
},
]
After we make a completion request, the LLM responds with its supposed actions. If the response features a perform name, our script executes that perform. For instance, if the LLM decides to name the sql_query_emailperform, our script retrieves the consumer’s e mail from the database after which provides the outcome to the dialog historical past. When the send_emailperform is named, our script sends an e mail utilizing the FastAPI service.
The principle loop of our script checks for perform calls within the LLM’s response and acts accordingly:
chat = Chat()
chat.add_prompt("consumer", "Ship an e mail to user10 saying that he must pay the month-to-month subscription price.")
result_query = ''for i in vary(2):
chat_response = chat_completion_request(
chat.conversation_history,
features=features
)
response_content = chat_response.json()['choices'][0]['message']
if 'function_call' in response_content:
if response_content['function_call']['name'] == 'send_email':
res = json.hundreds(response_content['function_call']['arguments'])
send_email(res['name'], res['to'], res['body'])
break
elif response_content['function_call']['name'] == 'sql_query_email':
result_query = query_db(json.hundreds(response_content['function_call']['arguments'])['query'])
chat.add_prompt('consumer', str(result_query))
else:
chat.add_prompt('assistant', response_content['content'])
After we run the script, we get the next output:
{
"message": "E-mail efficiently despatched to Person 10 with e mail [email protected].",
"E-mail physique": "nnDear Person 10, nnThis is a reminder that your month-to-month subscription price is due. Please make the cost as quickly as doable to make sure uninterrupted service. Thanks in your cooperation. nnBest regards, nYour Subscription Service Workforce"
}
Let’s break down what occurred for us to get this output. Our immediate was “Ship an e mail to user10 saying that he must pay the month-to-month subscription price.”. Be aware that there is no such thing as a details about the user10e mail in our message. The LLM recognized the lacking data and understood that our perform query_emailwould enable it to question a database to get the e-mail from that consumer. After getting the e-mail, it bought two issues proper as soon as once more: first, it ought to generate the physique of the e-mail, and second, it ought to name the send_emailperform to set off the e-mail utilizing the FastAPI e mail service.
This text explored the perform calling function by implementing a case research the place the LLM coordinates a pipeline involving a PostgreSQL database and a FastAPI e mail service. The LLM efficiently navigated the duty of retrieving a consumer’s e mail from the database and instructing the e-mail service to ship a personalised message, all in response to a single immediate.
The implications of perform calling in AI fashions might be huge, opening up new potentialities for automating and streamlining processes. Information pipelines may change from static and engineering heavy to dynamic entities, permitting non-technical customers to shortly get their arms on the newest knowledge utilizing pure language.
This text belongs to “Giant Language Fashions Chronicles: Navigating the NLP Frontier”, a brand new weekly sequence of articles that may discover the right way to leverage the facility of huge fashions for varied NLP duties. By diving into these cutting-edge applied sciences, we purpose to empower builders, researchers, and fans to harness the potential of NLP and unlock new potentialities.
Articles printed up to now:
- Summarizing the latest Spotify releases with ChatGPT
- Master Semantic Search at Scale: Index Millions of Documents with Lightning-Fast Inference Times using FAISS and Sentence Transformers
- Unlock the Power of Audio Data: Advanced Transcription and Diarization with Whisper, WhisperX, and PyAnnotate
- Whisper JAX vs PyTorch: Uncovering the Truth about ASR Performance on GPUs
- Vosk for Efficient Enterprise-Grade Speech Recognition: An Evaluation and Implementation Guide
- Testing the Massively Multilingual Speech (MMS) Model that Supports 1162 Languages
- Harnessing the Falcon 40B Model, the Most Powerful Open-Source LLM
Be in contact: LinkedIn