
Introducing RGB-Stacking as a brand new benchmark for vision-based robotic manipulation
Choosing up a stick and balancing it atop a log or stacking a pebble on a stone could appear to be easy — and fairly comparable — actions for an individual. Nevertheless, most robots battle with dealing with multiple such process at a time. Manipulating a stick requires a unique set of behaviours than stacking stones, by no means thoughts piling varied dishes on prime of each other or assembling furnishings. Earlier than we are able to educate robots how one can carry out these sorts of duties, they first must discover ways to work together with a far larger vary of objects. As a part of DeepMind’s mission and as a step towards making extra generalisable and helpful robots, we’re exploring how one can allow robots to higher perceive the interactions of objects with various geometries.
In a paper to be offered at CoRL 2021 (Convention on Robotic Studying) and accessible now as a preprint on OpenReview, we introduce RGB-Stacking as a brand new benchmark for vision-based robotic manipulation. On this benchmark, a robotic has to discover ways to grasp completely different objects and steadiness them on prime of each other. What units our analysis other than prior work is the variety of objects used and the massive variety of empirical evaluations carried out to validate our findings. Our outcomes reveal {that a} mixture of simulation and real-world information can be utilized to be taught advanced multi-object manipulation and recommend a robust baseline for the open downside of generalising to novel objects. To assist different researchers, we’re open-sourcing a model of our simulated atmosphere, and releasing the designs for constructing our real-robot RGB-stacking atmosphere, together with the RGB-object fashions and data for 3D printing them. We’re additionally open-sourcing a collection of libraries and tools utilized in our robotics analysis extra broadly.
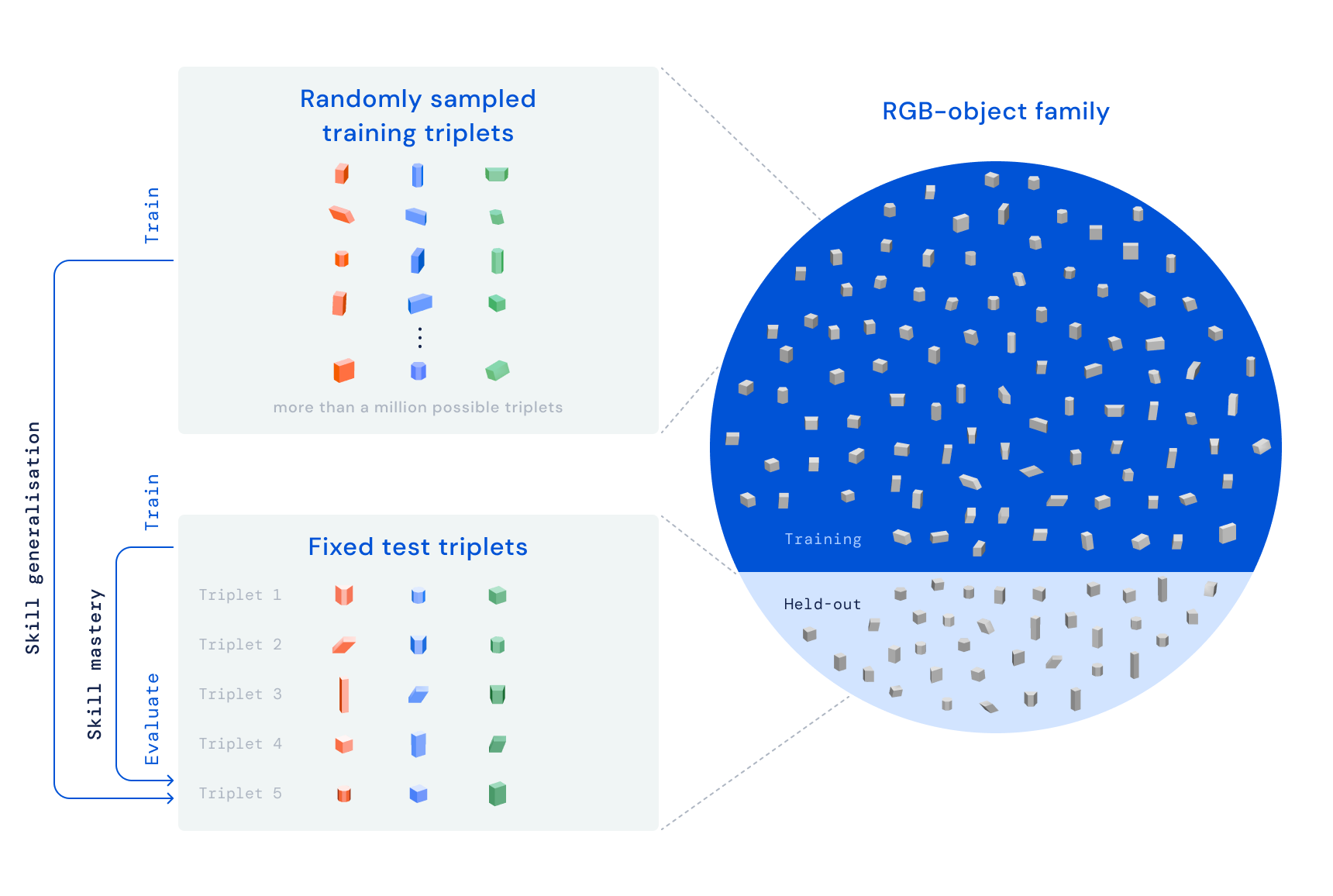
With RGB-Stacking, our aim is to coach a robotic arm through reinforcement studying to stack objects of various shapes. We place a parallel gripper hooked up to a robotic arm above a basket, and three objects within the basket — one pink, one inexperienced, and one blue, therefore the title RGB. The duty is straightforward: stack the pink object on prime of the blue object inside 20 seconds, whereas the inexperienced object serves as an impediment and distraction. The educational course of ensures that the agent acquires generalised expertise by means of coaching on a number of object units. We deliberately fluctuate the grasp and stack affordances — the qualities that outline how the agent can grasp and stack every object. This design precept forces the agent to exhibit behaviours that transcend a easy pick-and-place technique.

Our RGB-Stacking benchmark contains two process variations with completely different ranges of issue. In “Talent Mastery,” our aim is to coach a single agent that’s expert in stacking a predefined set of 5 triplets. In “Talent Generalisation,” we use the identical triplets for analysis, however prepare the agent on a big set of coaching objects — totalling greater than one million potential triplets. To check for generalisation, these coaching objects exclude the household of objects from which the check triplets have been chosen. In each variations, we decouple our studying pipeline into three phases:
- First, we prepare in simulation utilizing an off-the-shelf RL algorithm: Maximum a Posteriori Policy Optimisation (MPO). At this stage, we use the simulator’s state, permitting for quick coaching because the object positions are given on to the agent as a substitute of the agent needing to be taught to search out the objects in pictures. The ensuing coverage just isn’t straight transferable to the true robotic since this data just isn’t accessible in the true world.
- Subsequent, we prepare a brand new coverage in simulation that makes use of solely life like observations: pictures and the robotic’s proprioceptive state. We use a domain-randomised simulation to enhance switch to real-world pictures and dynamics. The state coverage serves as a trainer, offering the educational agent with corrections to its behaviours, and people corrections are distilled into the brand new coverage.
- Lastly, we acquire information utilizing this coverage on actual robots and prepare an improved coverage from this information offline by weighting up good transitions primarily based on a realized Q perform, as accomplished in Critic Regularised Regression (CRR). This enables us to make use of the info that’s passively collected in the course of the undertaking as a substitute of working a time-consuming on-line coaching algorithm on the true robots.
Decoupling our studying pipeline in such a method proves essential for 2 major causes. Firstly, it permits us to resolve the issue in any respect, since it might merely take too lengthy if we have been to begin from scratch on the robots straight. Secondly, it will increase our analysis velocity, since completely different folks in our group can work on completely different components of the pipeline earlier than we mix these adjustments for an total enchancment.
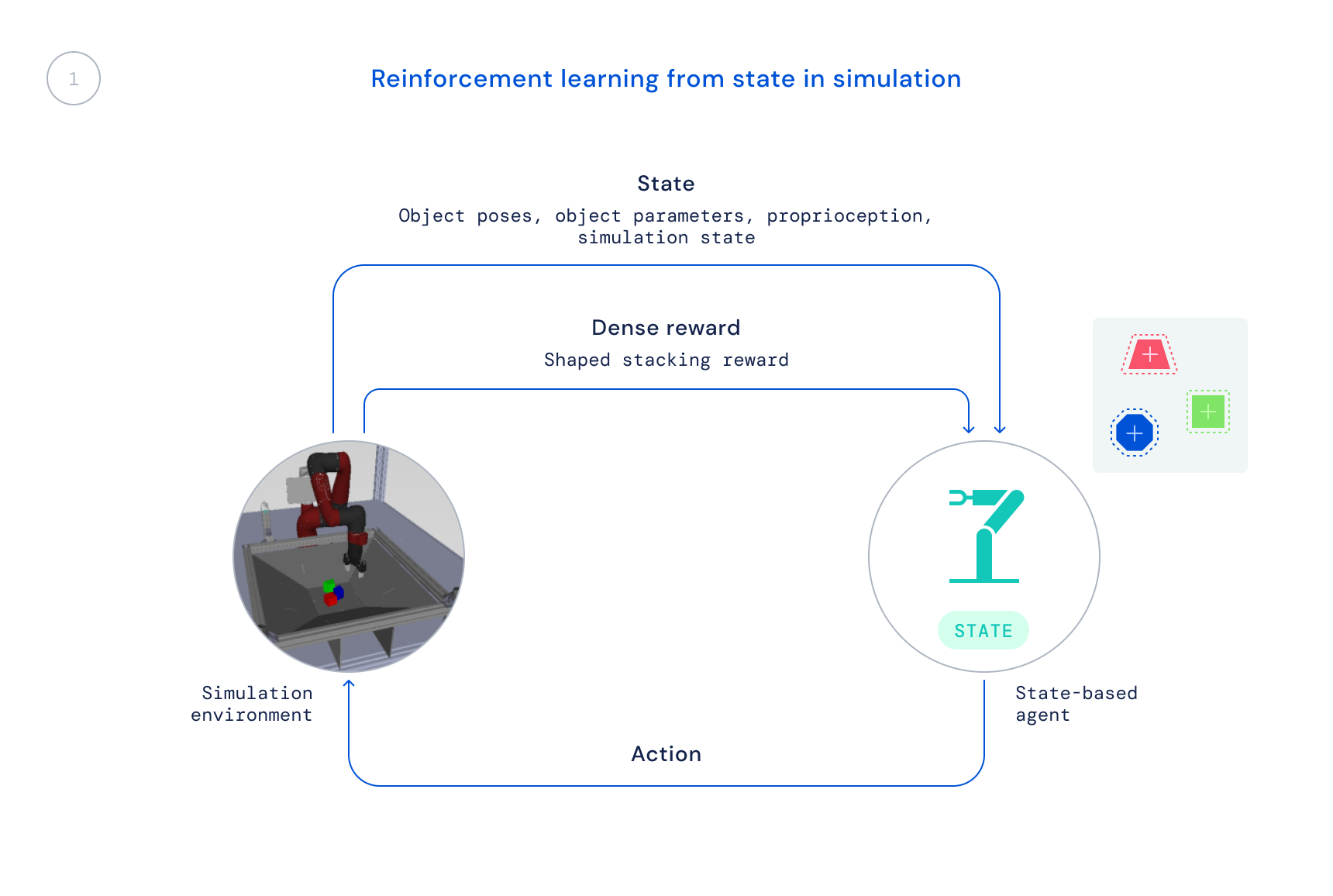
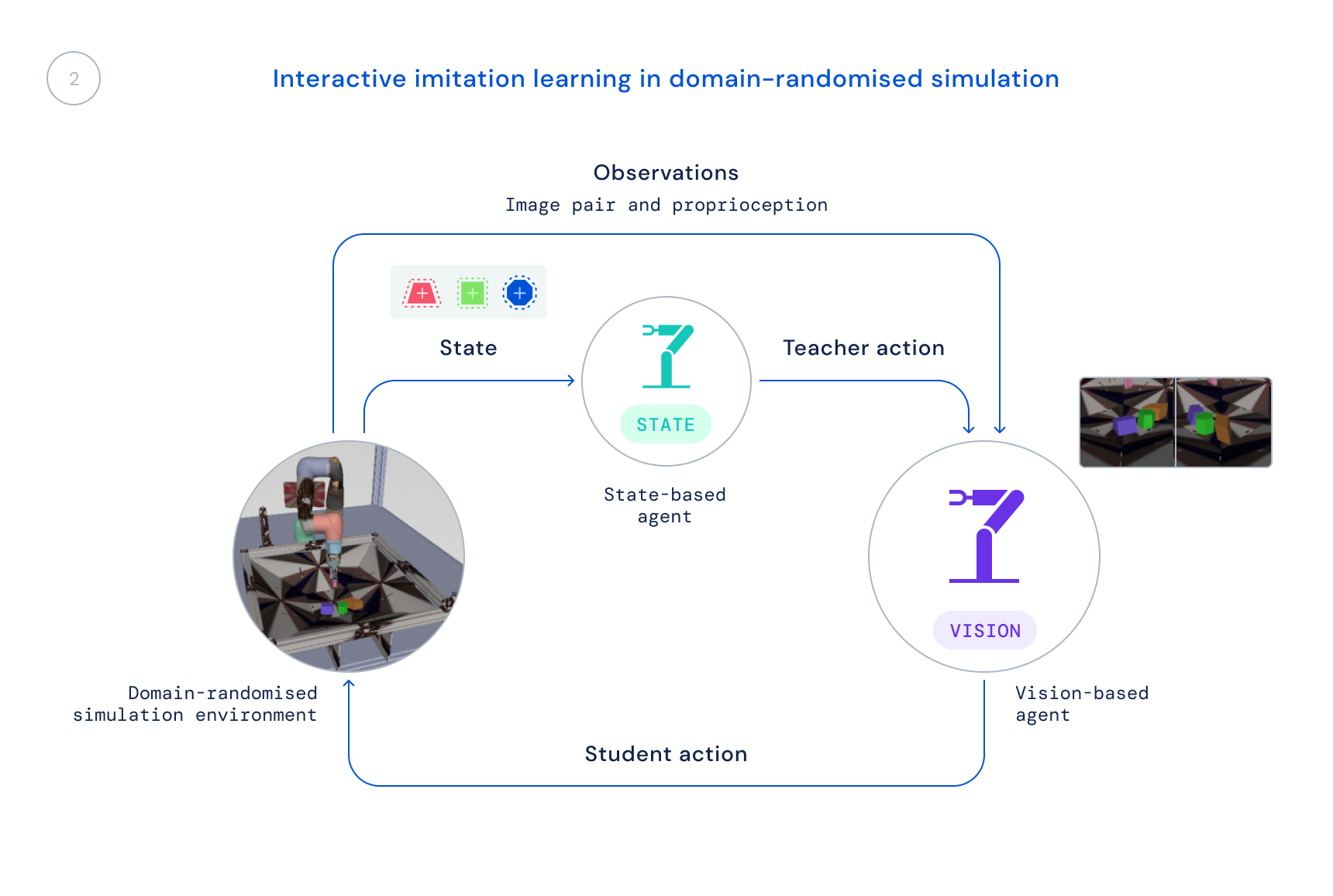
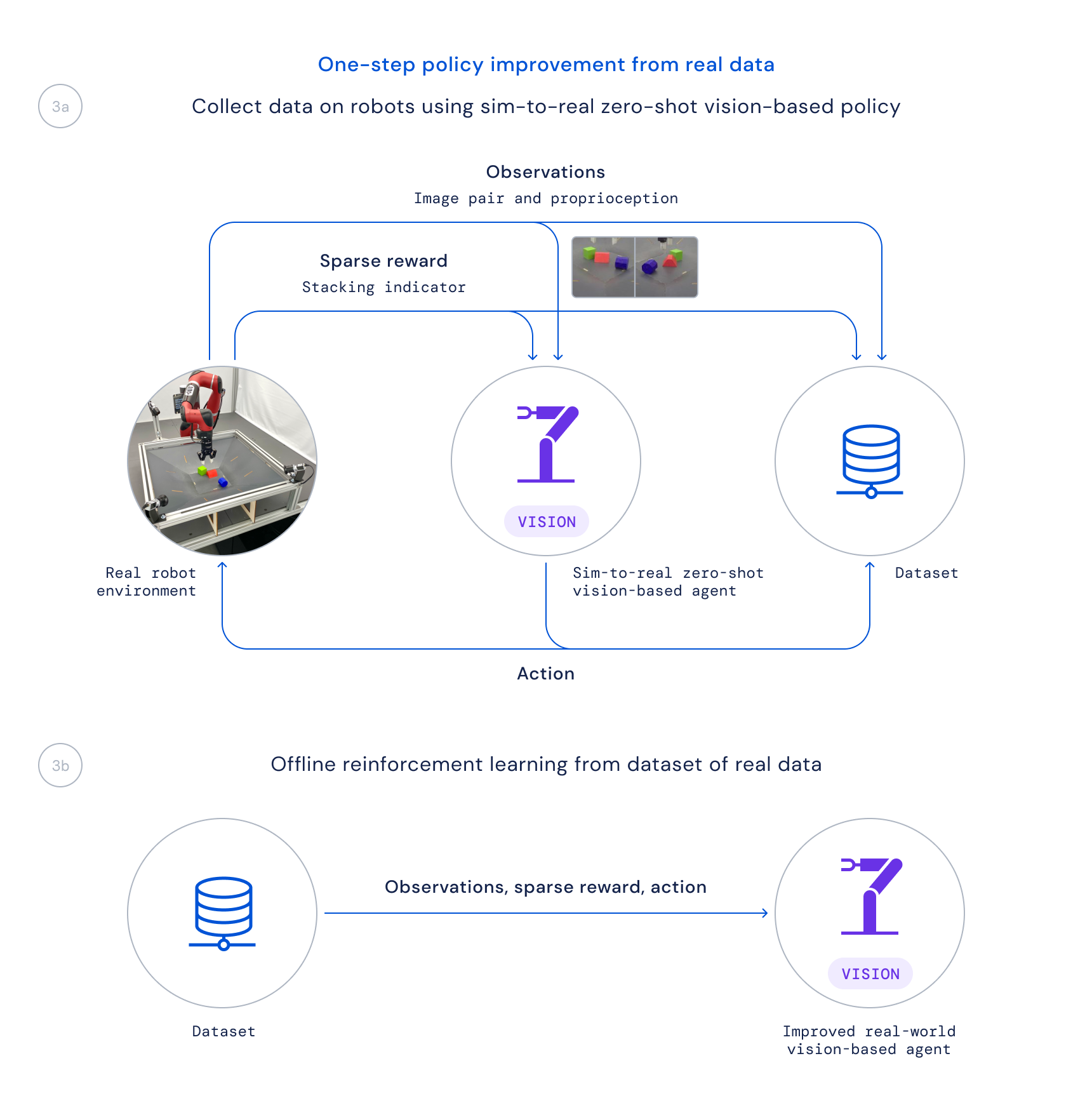

Lately, there was a lot work on making use of studying algorithms to fixing tough real-robot manipulation issues at scale, however the focus of such work has largely been on duties resembling greedy, pushing, or different types of manipulating single objects. The strategy to RGB-Stacking we describe in our paper, accompanied by our robotics resources now available on GitHub, leads to stunning stacking methods and mastery of stacking a subset of those objects. Nonetheless, this step solely scratches the floor of what’s potential – and the generalisation problem stays not absolutely solved. As researchers hold working to resolve the open problem of true generalisation in robotics, we hope this new benchmark, together with the atmosphere, designs, and instruments we now have launched, contribute to new concepts and strategies that may make manipulation even simpler and robots extra succesful.
