
Amazon SageMaker Data Wrangler is a single visible interface that reduces the time required to arrange information and carry out function engineering from weeks to minutes with the flexibility to pick and clear information, create options, and automate information preparation in machine studying (ML) workflows with out writing any code.
SageMaker Information Wrangler helps Snowflake, a preferred information supply for customers who wish to carry out ML. We launch the Snowflake direct connection from the SageMaker Information Wrangler in an effort to enhance the shopper expertise. Earlier than the launch of this function, directors have been required to arrange the preliminary storage integration to attach with Snowflake to create options for ML in Information Wrangler. This contains provisioning Amazon Simple Storage Service (Amazon S3) buckets, AWS Identity and Access Management (IAM) entry permissions, Snowflake storage integration for particular person customers, and an ongoing mechanism to handle or clear up information copies in Amazon S3. This course of isn’t scalable for patrons with strict information entry management and a lot of customers.
On this put up, we present how Snowflake’s direct connection in SageMaker Information Wrangler simplifies the administrator’s expertise and information scientist’s ML journey from information to enterprise insights.
Resolution overview
On this answer, we use SageMaker Information Wrangler to hurry up information preparation for ML and Amazon SageMaker Autopilot to mechanically construct, prepare, and fine-tune the ML fashions based mostly in your information. Each providers are designed particularly to extend productiveness and shorten time to worth for ML practitioners. We additionally display the simplified information entry from SageMaker Information Wrangler to Snowflake with direct connection to question and create options for ML.
Consult with the diagram beneath for an outline of the low-code ML course of with Snowflake, SageMaker Information Wrangler, and SageMaker Autopilot.
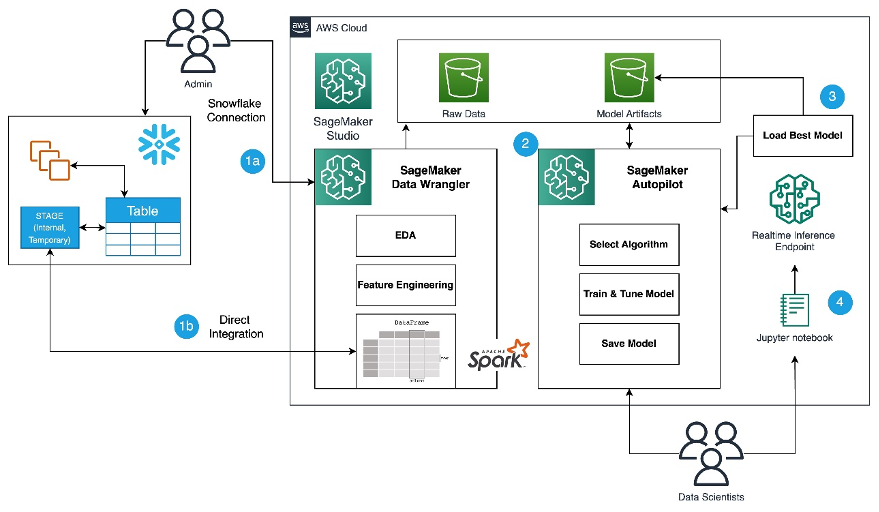
The workflow contains the next steps:
- Navigate to SageMaker Information Wrangler to your information preparation and have engineering duties.
- Arrange the Snowflake reference to SageMaker Information Wrangler.
- Discover your Snowflake tables in SageMaker Information Wrangler, create a ML dataset, and carry out function engineering.
- Practice and take a look at the fashions utilizing SageMaker Information Wrangler and SageMaker Autopilot.
- Load the very best mannequin to a real-time inference endpoint for predictions.
- Use a Python pocket book to invoke the launched real-time inference endpoint.
Stipulations
For this put up, the administrator wants the next stipulations:
Information scientists ought to have the next stipulations
Lastly, you need to put together your information for Snowflake
- We use bank card transaction information from Kaggle to construct ML fashions for detecting fraudulent bank card transactions, so clients will not be charged for gadgets that they didn’t buy. The dataset contains bank card transactions in September 2013 made by European cardholders.
- You must use the SnowSQL client and set up it in your native machine, so you should use it to add the dataset to a Snowflake desk.
The next steps present the best way to put together and cargo the dataset into the Snowflake database. It is a one-time setup.
Snowflake desk and information preparation
Full the next steps for this one-time setup:
- First, because the administrator, create a Snowflake digital warehouse, person, and position, and grant entry to different customers resembling the info scientists to create a database and stage information for his or her ML use circumstances:
- As the info scientist, let’s now create a database and import the bank card transactions into the Snowflake database to entry the info from SageMaker Information Wrangler. For illustration functions, we create a Snowflake database named
SF_FIN_TRANSACTION: - Obtain the dataset CSV file to your native machine and create a stage to load the info into the database desk. Replace the file path to level to the downloaded dataset location earlier than operating the PUT command for importing the info to the created stage:
- Create a desk named
credit_card_transactions: - Import the info into the created desk from the stage:
Arrange the SageMaker Information Wrangler and Snowflake connection
After we put together the dataset to make use of with SageMaker Information Wrangler, allow us to create a brand new Snowflake connection in SageMaker Information Wrangler to hook up with the sf_fin_transaction database in Snowflake and question the credit_card_transaction desk:
- Select Snowflake on the SageMaker Information Wrangler Connection web page.
- Present a reputation to determine your connection.
- Choose your authentication methodology to attach with the Snowflake database:
- If utilizing primary authentication, present the person identify and password shared by your Snowflake administrator. For this put up, we use primary authentication to hook up with Snowflake utilizing the person credentials we created within the earlier step.
- In case you are utilizing OAuth, present your id supplier credentials.
SageMaker Information Wrangler by default queries your information instantly from Snowflake with out creating any information copies in S3 buckets. SageMaker Information Wrangler’s new usability enhancement makes use of Apache Spark to combine with Snowflake to arrange and seamlessly create a dataset to your ML journey.
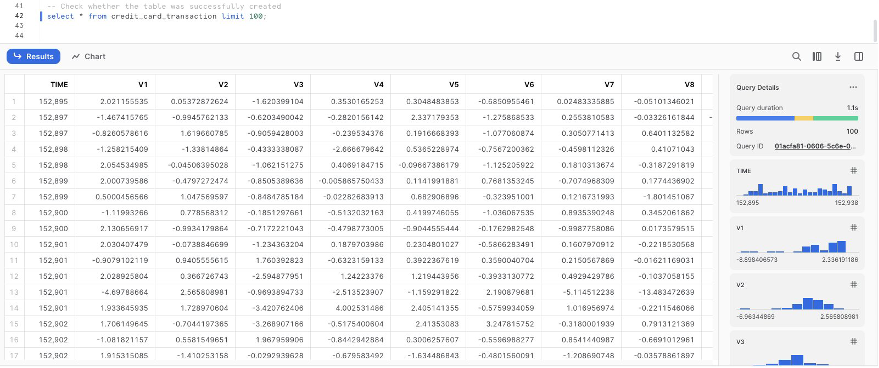
Thus far, we’ve created the database on Snowflake, imported the CSV file into the Snowflake desk, created Snowflake credentials, and created a connector on SageMaker Information Wrangler to hook up with Snowflake. To validate the configured Snowflake connection, run the next question on the created Snowflake desk:
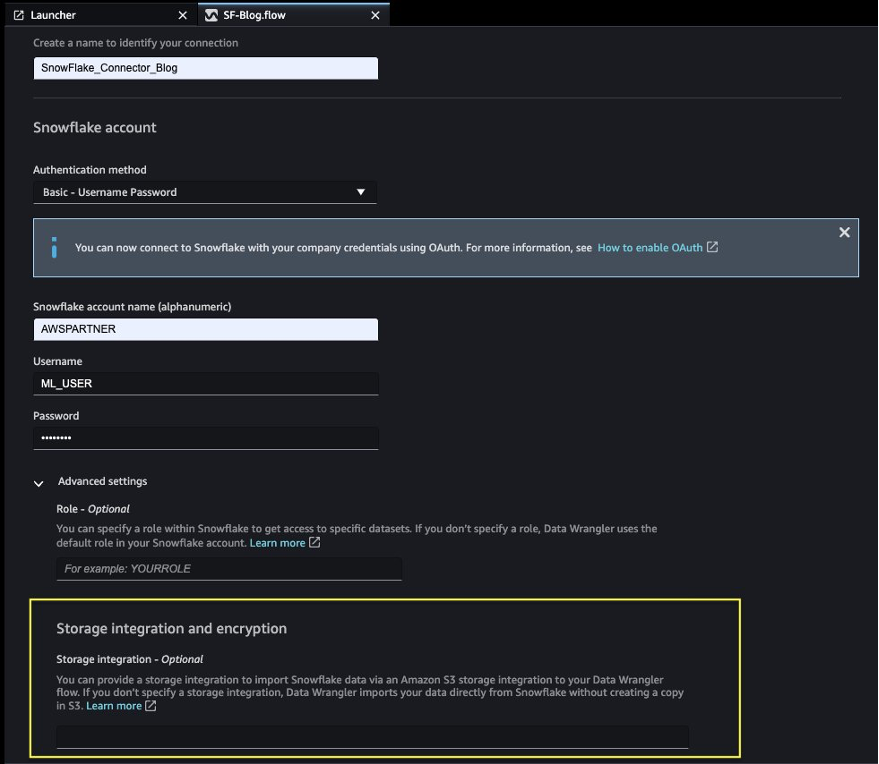
Be aware that the storage integration choice that was required earlier than is now non-compulsory within the superior settings.
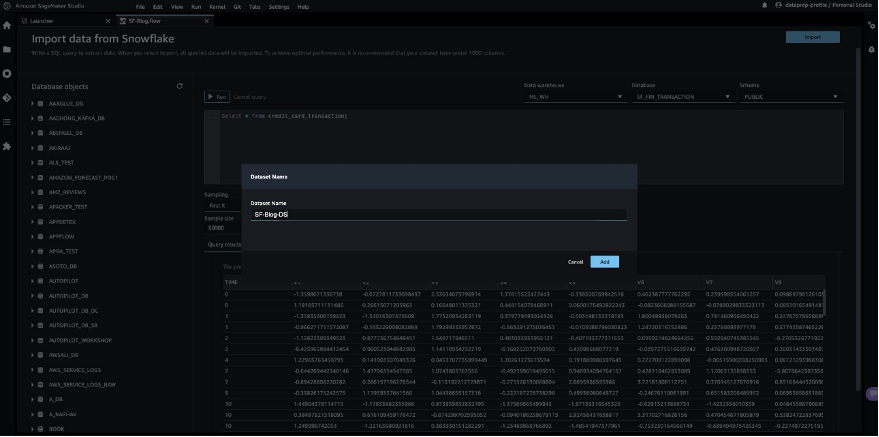
Discover Snowflake information
After you validate the question outcomes, select Import to avoid wasting the question outcomes because the dataset. We use this extracted dataset for exploratory information evaluation and have engineering.
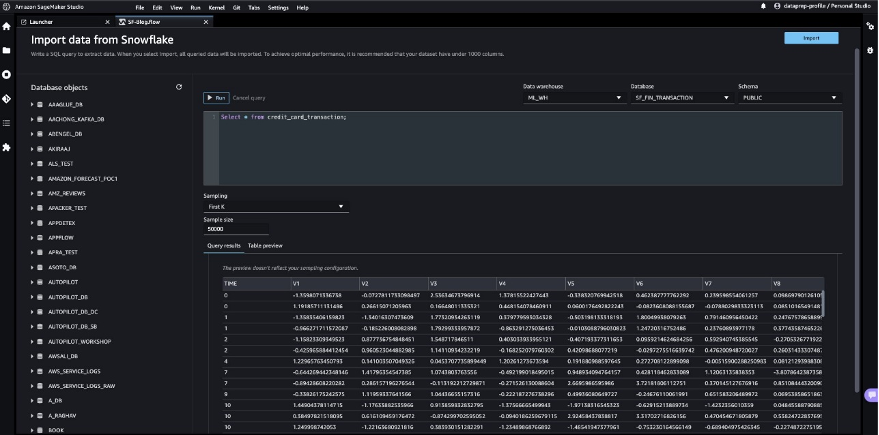
You’ll be able to select to pattern the info from Snowflake within the SageMaker Information Wrangler UI. Another choice is to obtain full information to your ML mannequin coaching use circumstances utilizing SageMaker Information Wrangler processing jobs.
Carry out exploratory information evaluation in SageMaker Information Wrangler
The information inside Information Wrangler must be engineered earlier than it may be educated. On this part, we display the best way to carry out function engineering on the info from Snowflake utilizing SageMaker Information Wrangler’s built-in capabilities.
First, let’s use the Information High quality and Insights Report function inside SageMaker Information Wrangler to generate stories to mechanically confirm the info high quality and detect abnormalities within the information from Snowflake.
You should utilize the report that can assist you clear and course of your information. It provides you info such because the variety of lacking values and the variety of outliers. In case you have points together with your information, resembling goal leakage or imbalance, the insights report can convey these points to your consideration. To grasp the report particulars, check with Accelerate data preparation with data quality and insights in Amazon SageMaker Data Wrangler.
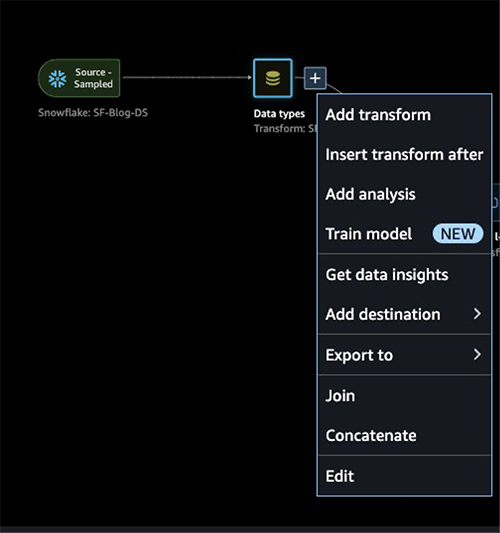
After you take a look at the info sort matching utilized by SageMaker Information Wrangler, full the next steps:
- Select the plus signal subsequent to Information sorts and select Add evaluation.

- For Evaluation sort, select Information High quality and Insights Report.
- Select Create.

- Consult with the Information High quality and Insights Report particulars to take a look at high-priority warnings.
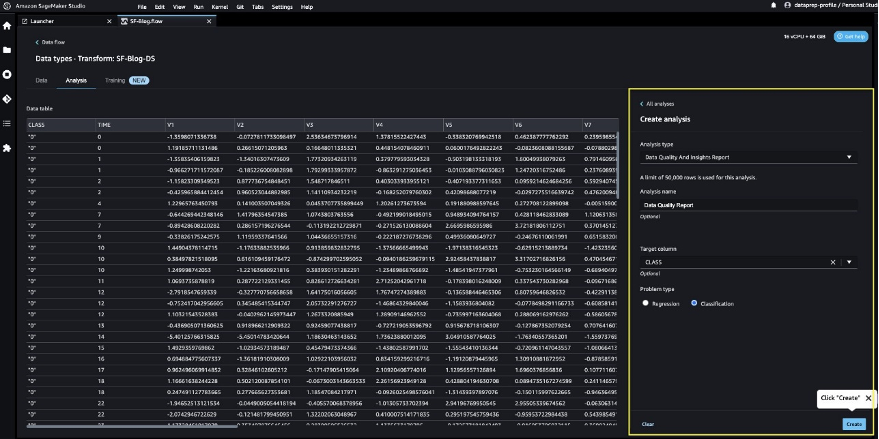
You’ll be able to select to resolve the warnings reported earlier than continuing together with your ML journey.
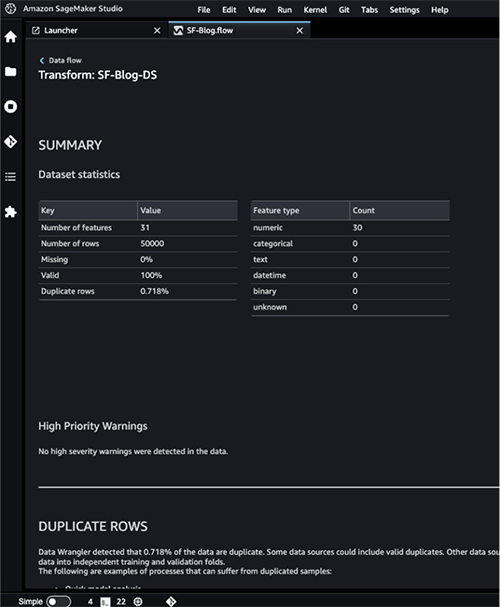
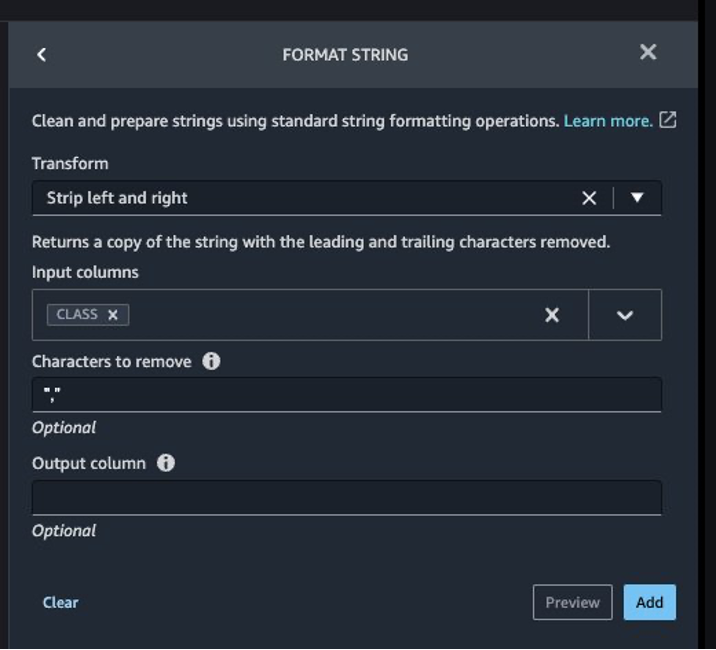
The goal column Class to be predicted is classed as a string. First, let’s apply a metamorphosis to take away the stale empty characters.
- Select Add step and select Format string.
- Within the checklist of transforms, select Strip left and proper.
- Enter the characters to take away and select Add.
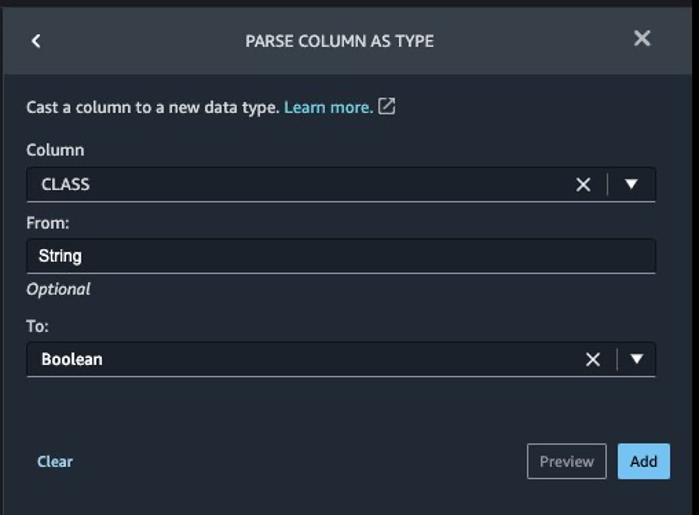
Subsequent, we convert the goal column Class from the string information sort to Boolean as a result of the transaction is both legit or fraudulent.
- Select Add step.
- Select Parse column as sort.
- For Column, select
Class. - For From, select String.
- For To, select Boolean.
- Select Add.
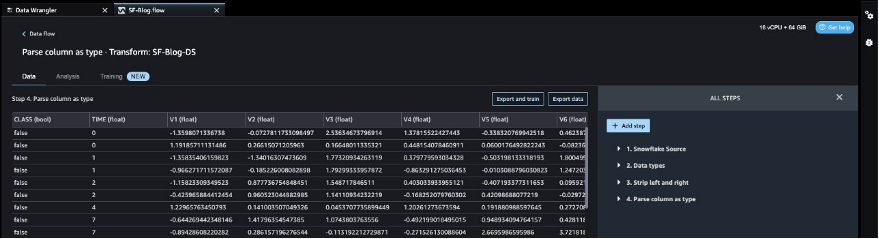
After the goal column transformation, we scale back the variety of function columns, as a result of there are over 30 options within the authentic dataset. We use Principal Element Evaluation (PCA) to cut back the scale based mostly on function significance. To grasp extra about PCA and dimensionality discount, check with Principal Component Analysis (PCA) Algorithm.
- Select Add step.

- Select Dimensionality Discount.

- For Rework, select Principal element evaluation.
- For Enter columns, select all of the columns besides the goal column
Class.
- Select the plus signal subsequent to Information circulation and select Add evaluation.
- For Evaluation sort, select Fast Mannequin.
- For Evaluation identify, enter a reputation.
- For Label, select
Class.
- Select Run.
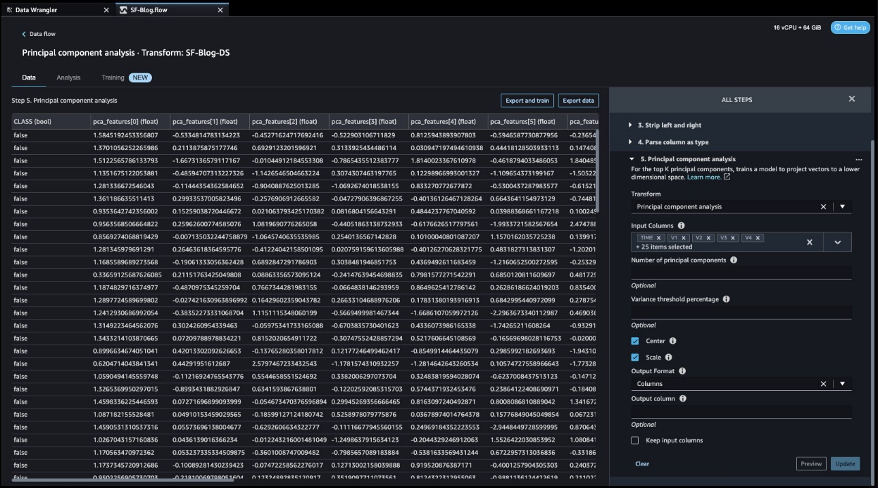
Based mostly on the PCA outcomes, you possibly can determine which options to make use of for constructing the mannequin. Within the following screenshot, the graph reveals the options (or dimensions) ordered based mostly on highest to lowest significance to foretell the goal class, which on this dataset is whether or not the transaction is fraudulent or legitimate.
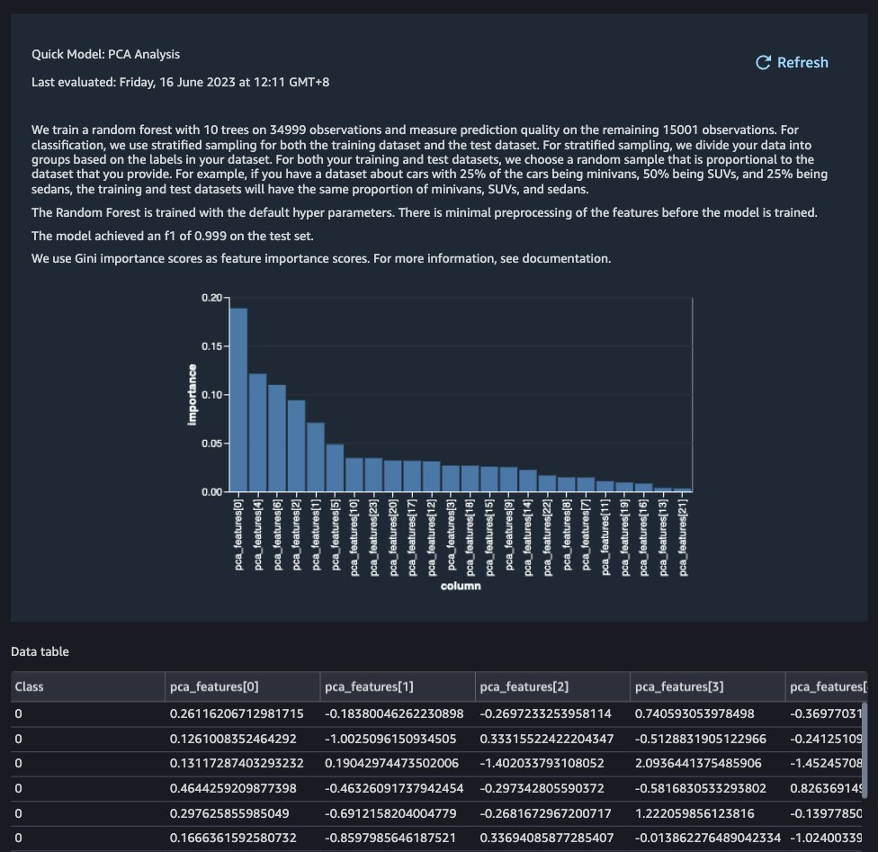
You’ll be able to select to cut back the variety of options based mostly on this evaluation, however for this put up, we depart the defaults as is.
This concludes our function engineering course of, though you might select to run the short mannequin and create a Information High quality and Insights Report once more to grasp the info earlier than performing additional optimizations.
Export information and prepare the mannequin
Within the subsequent step, we use SageMaker Autopilot to mechanically construct, prepare, and tune the very best ML fashions based mostly in your information. With SageMaker Autopilot, you continue to preserve full management and visibility of your information and mannequin.
Now that we’ve accomplished the exploration and have engineering, let’s prepare a mannequin on the dataset and export the info to coach the ML mannequin utilizing SageMaker Autopilot.
- On the Coaching tab, select Export and prepare.

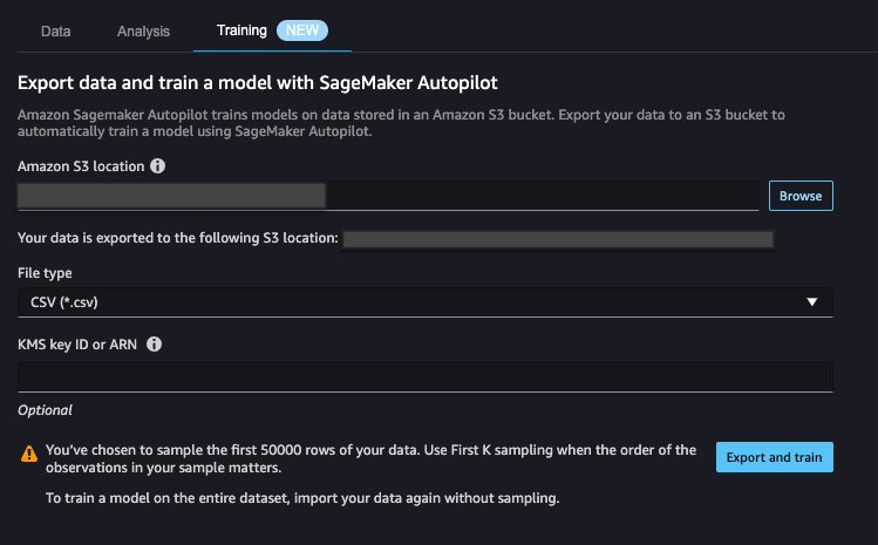
We will monitor the export progress whereas we watch for it to finish.
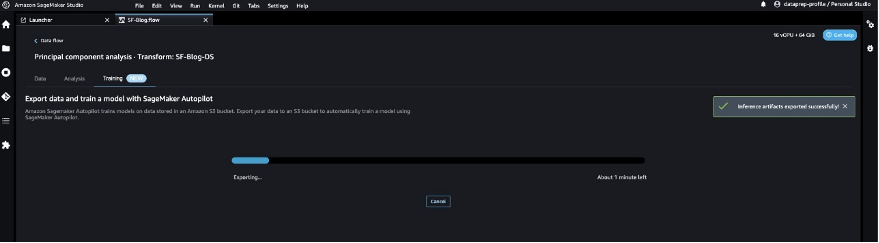
Let’s configure SageMaker Autopilot to run an automatic coaching job by specifying the goal we wish to predict and the kind of drawback. On this case, as a result of we’re coaching the dataset to foretell whether or not the transaction is fraudulent or legitimate, we use binary classification.
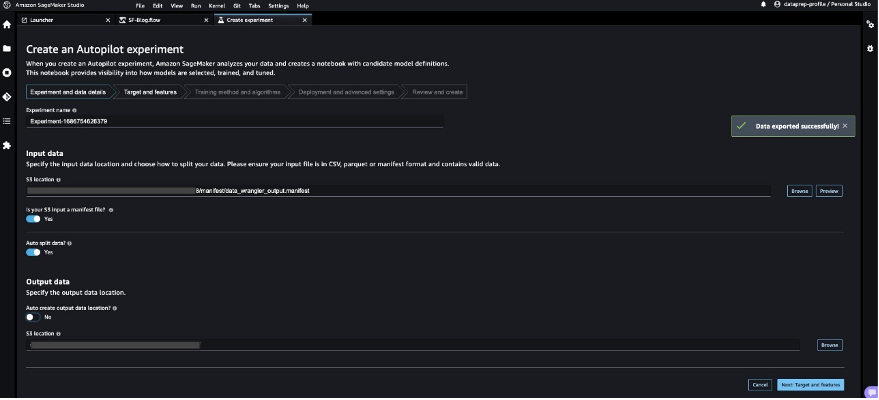
- Enter a reputation to your experiment, present the S3 location information, and select Subsequent: Goal and options.

- For Goal, select
Classbecause the column to foretell. - Select Subsequent: Coaching methodology.

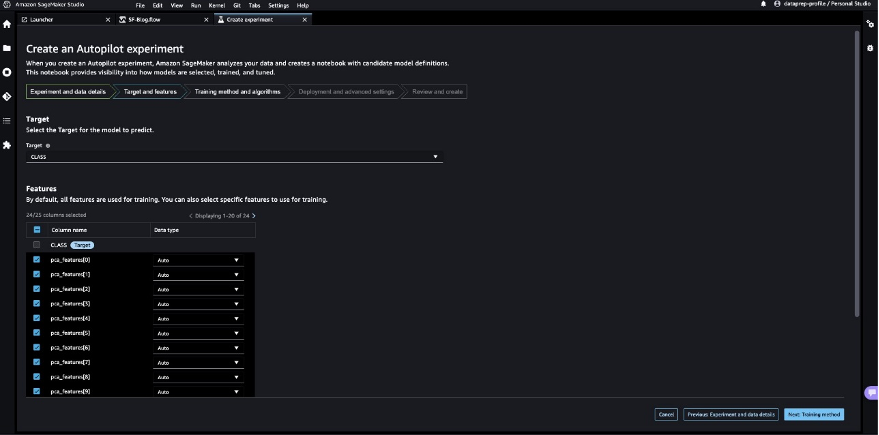
Let’s permit SageMaker Autopilot to determine the coaching methodology based mostly on the dataset.
- For Coaching methodology and algorithms, choose Auto.
To grasp extra in regards to the coaching modes supported by SageMaker Autopilot, check with Training modes and algorithm assist.
- Select Subsequent: Deployment and superior settings.

- For Deployment choice, select Auto deploy the very best mannequin with transforms from Information Wrangler, which masses the very best mannequin for inference after the experimentation is full.
- Enter a reputation to your endpoint.
- For Choose the machine studying drawback sort, select Binary classification.
- For Objection metric, select F1.
- Select Subsequent: Overview and create.
- Select Create experiment.
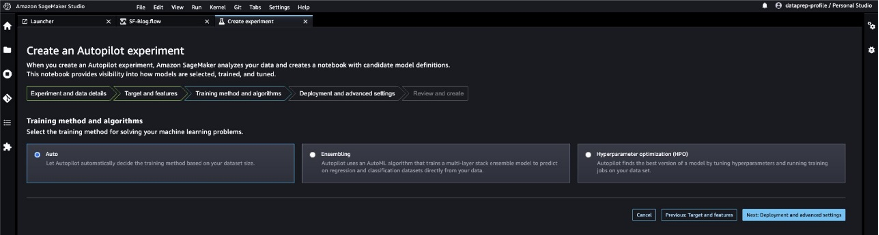
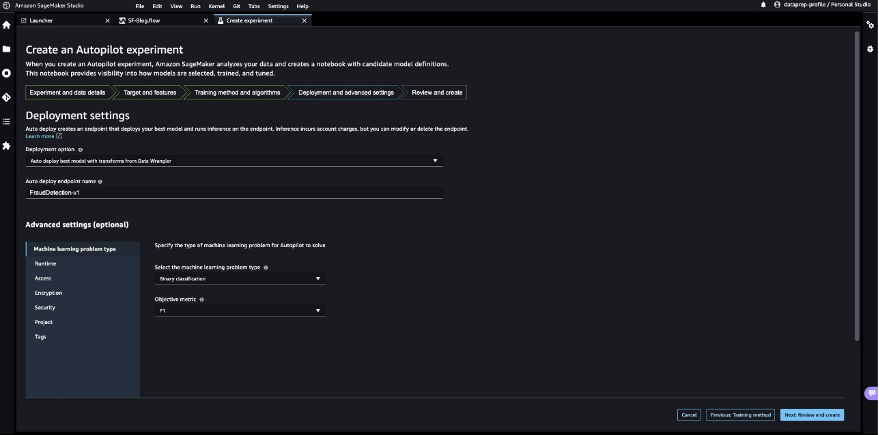
This begins an SageMaker Autopilot job that creates a set of coaching jobs that makes use of combos of hyperparameters to optimize the target metric.
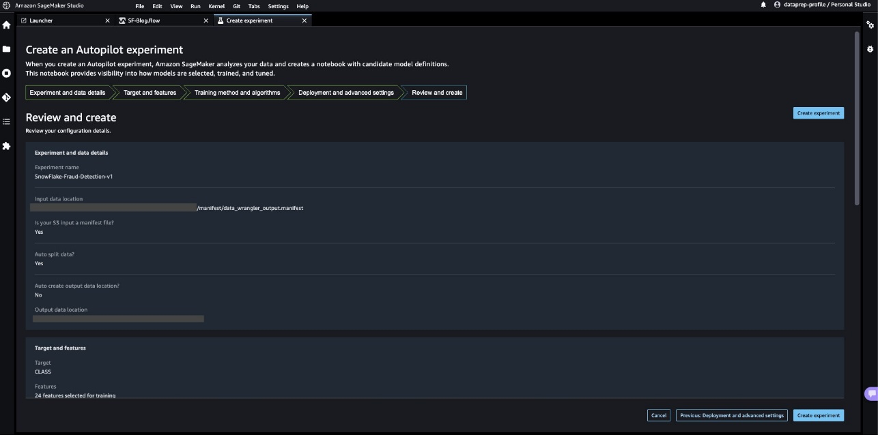
Look forward to SageMaker Autopilot to complete constructing the fashions and analysis of the very best ML mannequin.
Launch a real-time inference endpoint to check the very best mannequin
SageMaker Autopilot runs experiments to find out the very best mannequin that may classify bank card transactions as legit or fraudulent.
When SageMaker Autopilot completes the experiment, we are able to view the coaching outcomes with the analysis metrics and discover the very best mannequin from the SageMaker Autopilot job description web page.
- Choose the very best mannequin and select Deploy mannequin.

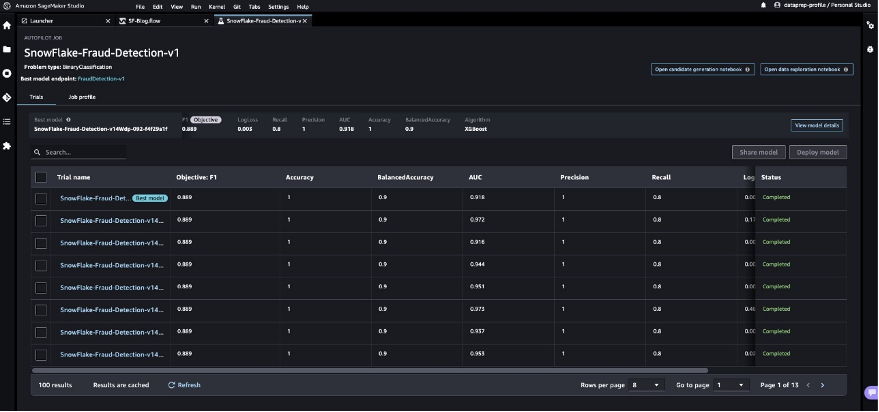
We use a real-time inference endpoint to check the very best mannequin created by means of SageMaker Autopilot.
- Choose Make real-time predictions.

When the endpoint is accessible, we are able to cross the payload and get inference outcomes.
Let’s launch a Python pocket book to make use of the inference endpoint.
- On the SageMaker Studio console, select the folder icon within the navigation pane and select Create pocket book.

- Use the next Python code to invoke the deployed real-time inference endpoint:
The output reveals the outcome as false, which means the pattern function information isn’t fraudulent.

Clear up
To be sure to don’t incur costs after finishing this tutorial, shut down the SageMaker Data Wrangler application and shut down the notebook instance used to carry out inference. You also needs to delete the inference endpoint you created utilizing SageMaker Autopilot to stop further costs.
Conclusion
On this put up, we demonstrated the best way to convey your information from Snowflake instantly with out creating any intermediate copies within the course of. You’ll be able to both pattern or load your full dataset to SageMaker Information Wrangler instantly from Snowflake. You’ll be able to then discover the info, clear the info, and carry out that includes engineering utilizing SageMaker Information Wrangler’s visible interface.
We additionally highlighted how one can simply prepare and tune a mannequin with SageMaker Autopilot instantly from the SageMaker Information Wrangler person interface. With SageMaker Information Wrangler and SageMaker Autopilot integration, we are able to shortly construct a mannequin after finishing function engineering, with out writing any code. Then we referenced SageMaker Autopilot’s finest mannequin to run inferences utilizing a real-time endpoint.
Check out the brand new Snowflake direct integration with SageMaker Information Wrangler immediately to simply construct ML fashions together with your information utilizing SageMaker.
In regards to the authors
 Hariharan Suresh is a Senior Options Architect at AWS. He’s enthusiastic about databases, machine studying, and designing progressive options. Previous to becoming a member of AWS, Hariharan was a product architect, core banking implementation specialist, and developer, and labored with BFSI organizations for over 11 years. Outdoors of know-how, he enjoys paragliding and biking.
Hariharan Suresh is a Senior Options Architect at AWS. He’s enthusiastic about databases, machine studying, and designing progressive options. Previous to becoming a member of AWS, Hariharan was a product architect, core banking implementation specialist, and developer, and labored with BFSI organizations for over 11 years. Outdoors of know-how, he enjoys paragliding and biking.
 Aparajithan Vaidyanathan is a Principal Enterprise Options Architect at AWS. He helps enterprise clients migrate and modernize their workloads on AWS cloud. He’s a Cloud Architect with 23+ years of expertise designing and growing enterprise, large-scale and distributed software program programs. He focuses on Machine Studying & Information Analytics with give attention to Information and Function Engineering area. He’s an aspiring marathon runner and his hobbies embody mountaineering, bike using and spending time together with his spouse and two boys.
Aparajithan Vaidyanathan is a Principal Enterprise Options Architect at AWS. He helps enterprise clients migrate and modernize their workloads on AWS cloud. He’s a Cloud Architect with 23+ years of expertise designing and growing enterprise, large-scale and distributed software program programs. He focuses on Machine Studying & Information Analytics with give attention to Information and Function Engineering area. He’s an aspiring marathon runner and his hobbies embody mountaineering, bike using and spending time together with his spouse and two boys.
 Tim Track is a Software program Growth Engineer at AWS SageMaker, with 10+ years of expertise as software program developer, marketing consultant and tech chief he has demonstrated potential to ship scalable and dependable merchandise and resolve complicated issues. In his spare time, he enjoys the character, out of doors operating, mountaineering and and many others.
Tim Track is a Software program Growth Engineer at AWS SageMaker, with 10+ years of expertise as software program developer, marketing consultant and tech chief he has demonstrated potential to ship scalable and dependable merchandise and resolve complicated issues. In his spare time, he enjoys the character, out of doors operating, mountaineering and and many others.
 Bosco Albuquerque is a Sr. Associate Options Architect at AWS and has over 20 years of expertise in working with database and analytics merchandise from enterprise database distributors and cloud suppliers. He has helped giant know-how corporations design information analytics options and has led engineering groups in designing and implementing information analytics platforms and information merchandise.
Bosco Albuquerque is a Sr. Associate Options Architect at AWS and has over 20 years of expertise in working with database and analytics merchandise from enterprise database distributors and cloud suppliers. He has helped giant know-how corporations design information analytics options and has led engineering groups in designing and implementing information analytics platforms and information merchandise.

