
Implementing a contemporary information structure gives a scalable technique to combine information from disparate sources. By organizing information by enterprise domains as a substitute of infrastructure, every area can select instruments that swimsuit their wants. Organizations can maximize the worth of their fashionable information structure with generative AI options whereas innovating constantly.
The pure language capabilities enable non-technical customers to question information by way of conversational English fairly than complicated SQL. Nonetheless, realizing the total advantages requires overcoming some challenges. The AI and language fashions should establish the suitable information sources, generate efficient SQL queries, and produce coherent responses with embedded outcomes at scale. Additionally they want a person interface for pure language questions.
General, implementing a contemporary information structure and generative AI methods with AWS is a promising method for gleaning and disseminating key insights from various, expansive information at an enterprise scale. The most recent providing for generative AI from AWS is Amazon Bedrock, which is a totally managed service and the best approach to construct and scale generative AI functions with basis fashions. AWS additionally gives basis fashions by way of Amazon SageMaker JumpStart as Amazon SageMaker endpoints. The mixture of enormous language fashions (LLMs), together with the benefit of integration that Amazon Bedrock gives, and a scalable, domain-oriented information infrastructure positions this as an clever technique of tapping into the ample data held in numerous analytics databases and information lakes.
Within the put up, we showcase a state of affairs the place an organization has deployed a contemporary information structure with information residing on a number of databases and APIs resembling authorized information on Amazon Simple Storage Service (Amazon S3), human assets on Amazon Relational Database Service (Amazon RDS), gross sales and advertising on Amazon Redshift, monetary market information on a third-party information warehouse resolution on Snowflake, and product information as an API. This implementation goals to reinforce the productiveness of the enterprise’s enterprise analytics, product house owners, and enterprise area specialists. All this achieved by way of using generative AI on this area mesh structure, which permits the corporate to realize its enterprise aims extra effectively. This resolution has the choice to incorporate LLMs from JumpStart as a SageMaker endpoint in addition to third-party fashions. We offer the enterprise customers with a medium of asking fact-based questions with out having an underlying information of knowledge channels, thereby abstracting the complexities of writing easy to complicated SQL queries.
Resolution overview
A contemporary information structure on AWS applies synthetic intelligence and pure language processing to question a number of analytics databases. Through the use of providers resembling Amazon Redshift, Amazon RDS, Snowflake, Amazon Athena, and AWS Glue, it creates a scalable resolution to combine information from numerous sources. Utilizing LangChain, a robust library for working with LLMs, together with basis fashions from Amazon Bedrock and JumpStart in Amazon SageMaker Studio notebooks, a system is constructed the place customers can ask enterprise questions in pure English and obtain solutions with information drawn from the related databases.
The next diagram illustrates the structure.
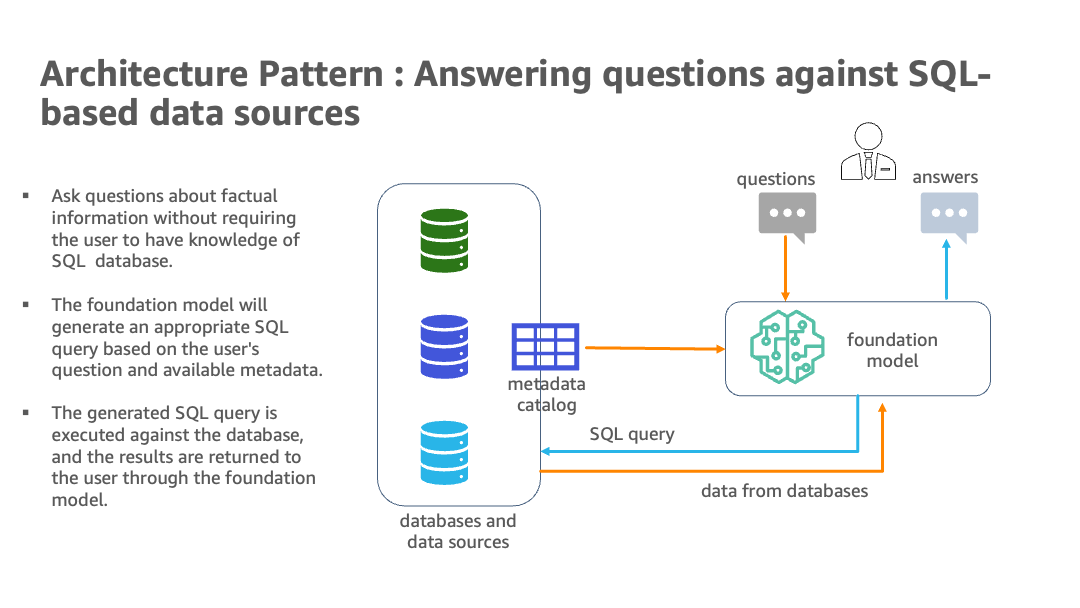
The hybrid structure makes use of a number of databases and LLMs, with basis fashions from Amazon Bedrock and JumpStart for information supply identification, SQL era, and textual content era with outcomes.
The next diagram illustrates the precise workflow steps for our resolution.
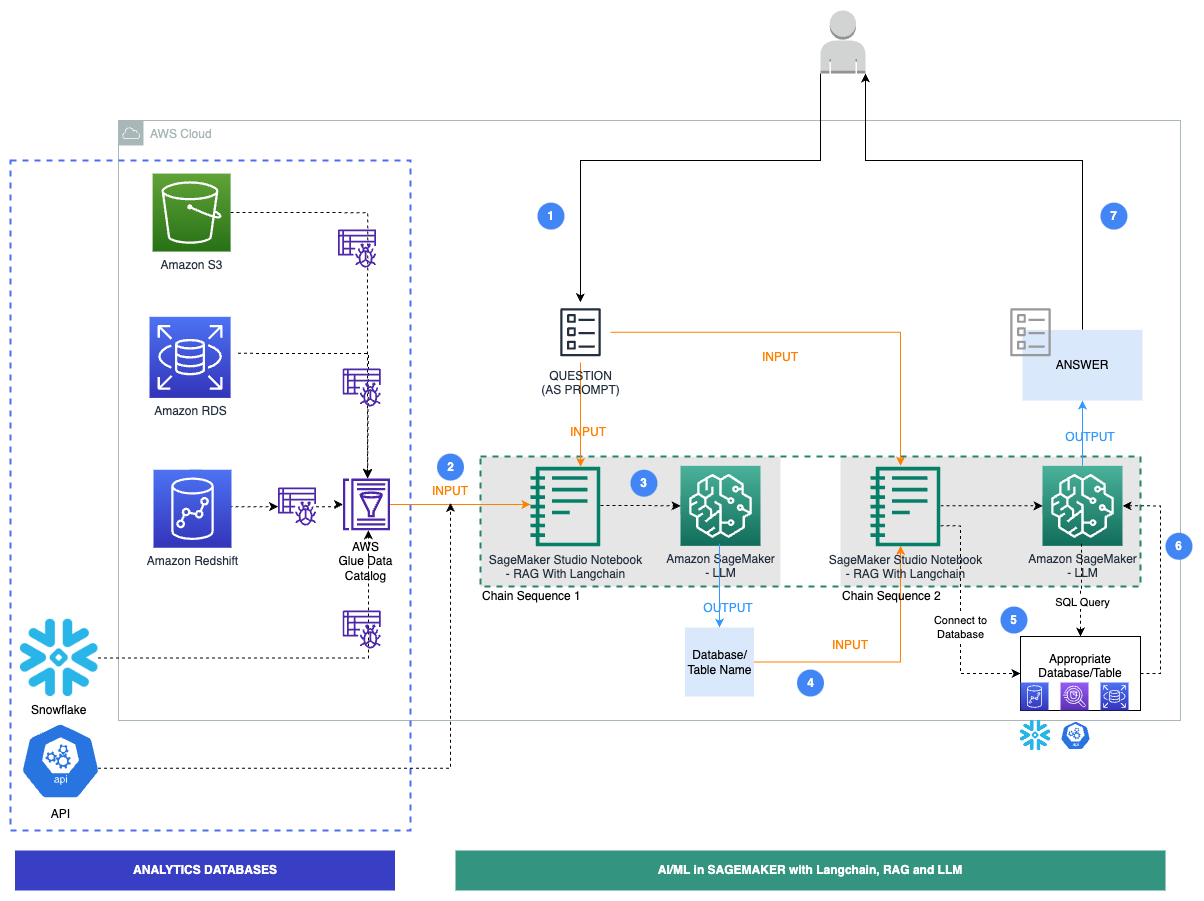
The steps are follows:
- A enterprise person gives an English query immediate.
- An AWS Glue crawler is scheduled to run at frequent intervals to extract metadata from databases and create desk definitions within the AWS Glue Data Catalog. The Information Catalog is enter to Chain Sequence 1 (see the previous diagram).
- LangChain, a instrument to work with LLMs and prompts, is utilized in Studio notebooks. LangChain requires an LLM to be outlined. As a part of Chain Sequence 1, the immediate and Information Catalog metadata are handed to an LLM, hosted on a SageMaker endpoint, to establish the related database and desk utilizing LangChain.
- The immediate and recognized database and desk are handed to Chain Sequence 2.
- LangChain establishes a connection to the database and runs the SQL question to get the outcomes.
- The outcomes are handed to the LLM to generate an English reply with the info.
- The person receives an English reply to their immediate, querying information from completely different databases.
This following sections clarify among the key steps with related code. To dive deeper into the answer and code for all steps proven right here, discuss with the GitHub repo. The next diagram reveals the sequence of steps adopted:

Conditions
You need to use any databases which might be suitable with SQLAlchemy to generate responses from LLMs and LangChain. Nonetheless, these databases will need to have their metadata registered with the AWS Glue Information Catalog. Moreover, you will want to have entry to LLMs by way of both JumpStart or API keys.
Connect with databases utilizing SQLAlchemy
LangChain makes use of SQLAlchemy to connect with SQL databases. We initialize LangChain’s SQLDatabase perform by creating an engine and establishing a connection for every information supply. The next is a pattern of how to connect with an Amazon Aurora MySQL-Compatible Edition serverless database and embody solely the staff desk:
Subsequent, we construct prompts utilized by Chain Sequence 1 to establish the database and the desk identify primarily based on the person query.
Generate dynamic immediate templates
We use the AWS Glue Information Catalog, which is designed to retailer and handle metadata data, to establish the supply of knowledge for a person question and construct prompts for Chain Sequence 1, as detailed within the following steps:
- We construct a Information Catalog by crawling by way of the metadata of a number of information sources utilizing the JDBC connection used within the demonstration.
- With the Boto3 library, we construct a consolidated view of the Information Catalog from a number of information sources. The next is a pattern on tips on how to get the metadata of the staff desk from the Information Catalog for the Aurora MySQL database:
A consolidated Information Catalog has particulars on the info supply, resembling schema, desk names, and column names. The next is a pattern of the output of the consolidated Information Catalog:
- We move the consolidated Information Catalog to the immediate template and outline the prompts utilized by LangChain:
Chain Sequence 1: Detect supply metadata for the person question utilizing LangChain and an LLM
We move the immediate template generated within the earlier step to the immediate, together with the person question to the LangChain mannequin, to seek out the most effective information supply to reply the query. LangChain makes use of the LLM mannequin of our option to detect supply metadata.
Use the next code to make use of an LLM from JumpStart or third-party fashions:
The generated textual content incorporates data such because the database and desk names in opposition to which the person question is run. For instance, for the person question “Title all staff with beginning date this month,” generated_text has the data database == rdsmysql and database.desk == rdsmysql.staff.
Subsequent, we move the main points of the human assets area, Aurora MySQL database, and staff desk to Chain Sequence 2.
Chain Sequence 2: Retrieve responses from the info sources to reply the person question
Subsequent, we run LangChain’s SQL database chain to transform textual content to SQL and implicitly run the generated SQL in opposition to the database to retrieve the database leads to a easy readable language.
We begin with defining a immediate template that instructs the LLM to generate SQL in a syntactically right dialect after which run it in opposition to the database:
Lastly, we move the LLM, database connection, and immediate to the SQL database chain and run the SQL question:
For instance, for the person question “Title all staff with beginning date this month,” the reply is as follows:
Clear up
After you run the trendy information structure with generative AI, ensure that to wash up any assets that gained’t be utilized. Shut down and delete the databases used (Amazon Redshift, Amazon RDS, Snowflake). As well as, delete the info in Amazon S3 and cease any Studio pocket book situations to not incur any additional expenses. If you happen to used JumpStart to deploy an LLM as a SageMaker real-time endpoint, delete endpoint by way of both the SageMaker console or Studio.
Conclusion
On this put up, we built-in a contemporary information structure with generative AI and LLMs inside SageMaker. This resolution makes use of numerous text-to-text basis fashions from JumpStart in addition to third-party fashions. This hybrid method identifies information sources, writes SQL queries, and generates responses with question outcomes. It makes use of Amazon Redshift, Amazon RDS, Snowflake, and LLMs. To enhance the answer, you could possibly add extra databases, a UI for English queries, immediate engineering, and information instruments. This might turn out to be an clever, unified approach to get insights from a number of information shops. To dive deeper into the answer and the code proven on this put up, take a look at the GitHub repo . Additionally, discuss with Amazon Bedrock to be used circumstances on generative AI, basis fashions, and enormous language fashions.
Appendix
Instance prompts
| Area | Database/API | Immediate | SQL (Generated by LLM) | Output |
| Gross sales & Advertising and marketing | Amazon RedShift | What number of ticket gross sales are there? | SELECT COUNT(*) AS total_salesFROM tickit.gross sales; |
There are 172,456 ticket gross sales. |
| Gross sales & Advertising and marketing | Amazon RedShift | What was the entire fee for the ticket gross sales within the yr 2008? | SELECT SUM(fee) AS total_commissionFROM tickit.gross salesWHERE EXTRACT(YEAR FROM saletime) = 2008 |
The whole fee for ticket gross sales within the yr 2008 was $16,614,814.65. |
| Authorized | S3 | What number of frauds occurred within the yr 2023? | SELECT depend(*)FROM claimsWHERE extract(yr from write_time) = 2023 AND fraud = 1; |
There have been 164 fraud claims in 2023. |
| Authorized | S3 | What number of insurance policies have been claimed this yr? | SELECT depend(*)FROM claims; |
There have been 5000 claims made this yr. |
| Human Sources | Amazon Aurora MySQL | Title all staff with beginning date this month | SELECT * FROM staffWHERE MONTH(birth_date) = MONTH(CURRENT_DATE()); |
The staff with birthdays this month are:Christian KoblickTzvetan ZielinskiKazuhito CappellettiYinghua Dredge |
| Human Sources | Amazon Aurora MySQL | What number of staff have been employed earlier than 1990? | SELECT COUNT(*) AS 'Variety of staff employed earlier than 1990'FROM staffWHERE hire_date < '1990-01-01' |
29 staff have been employed earlier than 1990. |
| Finance and Investments | Snowflake | Which inventory carried out the most effective and the worst in Could of 2013? | SELECT identify, MAX(shut) AS max_close, MIN(shut) AS min_closeFROM all_stocks_5yrWHERE date BETWEEN '2013-05-01' AND '2013-05-31'GROUP BY identifyORDER BY max_close DESC, min_close ASC |
The inventory that carried out the most effective in Could 2013 was AnySock1 (ASTOCK1) with a most closing worth of $842.50. The inventory that carried out the worst was AnySock2 (ASTOCK2) with a minimal closing worth of $3.22. |
| Finance and Investments | Snowflake | What’s the common quantity shares traded in July of 2013? | SELECT AVG(quantity) AS average_volumeFROM all_stocks_5yrWHERE date BETWEEN '2013-07-01' AND '2013-07-31' |
The common quantity of shares traded in July 2013 was 4,374,177 |
| Product – Climate | API | What’s the climate like proper now in New York Metropolis in levels Fahrenheit? |
Concerning the Authors
 Navneet Tuteja is a Information Specialist at Amazon Net Providers. Earlier than becoming a member of AWS, Navneet labored as a facilitator for organizations in search of to modernize their information architectures and implement complete AI/ML options. She holds an engineering diploma from Thapar College, in addition to a grasp’s diploma in statistics from Texas A&M College.
Navneet Tuteja is a Information Specialist at Amazon Net Providers. Earlier than becoming a member of AWS, Navneet labored as a facilitator for organizations in search of to modernize their information architectures and implement complete AI/ML options. She holds an engineering diploma from Thapar College, in addition to a grasp’s diploma in statistics from Texas A&M College.
 Sovik Kumar Nath is an AI/ML resolution architect with AWS. He has intensive expertise designing end-to-end machine studying and enterprise analytics options in finance, operations, advertising, healthcare, provide chain administration, and IoT. Sovik has revealed articles and holds a patent in ML mannequin monitoring. He has double masters levels from the College of South Florida, College of Fribourg, Switzerland, and a bachelors diploma from the Indian Institute of Expertise, Kharagpur. Exterior of labor, Sovik enjoys touring, taking ferry rides, and watching films.
Sovik Kumar Nath is an AI/ML resolution architect with AWS. He has intensive expertise designing end-to-end machine studying and enterprise analytics options in finance, operations, advertising, healthcare, provide chain administration, and IoT. Sovik has revealed articles and holds a patent in ML mannequin monitoring. He has double masters levels from the College of South Florida, College of Fribourg, Switzerland, and a bachelors diploma from the Indian Institute of Expertise, Kharagpur. Exterior of labor, Sovik enjoys touring, taking ferry rides, and watching films.
