
Grounding language to imaginative and prescient is a elementary drawback for a lot of real-world AI methods reminiscent of retrieving photographs or producing descriptions for the visually impaired. Success on these duties requires fashions to narrate completely different facets of language reminiscent of objects and verbs to photographs. For instance, to differentiate between the 2 photographs within the center column under, fashions should differentiate between the verbs “catch” and “kick.” Verb understanding is especially tough because it requires not solely recognising objects, but in addition how completely different objects in a picture relate to one another. To beat this problem, we introduce the SVO-Probes dataset and use it to probe language and imaginative and prescient fashions for verb understanding.

Particularly, we contemplate multimodal transformer fashions (e.g., Lu et al., 2019; Chen et al., 2020; Tan and Bansal, 2019; Li et al., 2020), which have proven success on a wide range of language and imaginative and prescient duties. Nonetheless, regardless of sturdy efficiency on benchmarks, it isn’t clear if these fashions have fine-grained multimodal understanding. Particularly, prior work exhibits that language and imaginative and prescient fashions can succeed at benchmarks with out multimodal understanding: for instance, answering questions on photographs based mostly solely on language priors (Agrawal et al., 2018) or “hallucinating” objects that aren’t within the picture when captioning photographs (Rohrbach et al., 2018). To anticipate mannequin limitations, work like Shekhar et al. suggest specialised evaluations to probe fashions systematically for language understanding. Nonetheless, prior probe units are restricted within the variety of objects and verbs. We developed SVO-Probes to raised consider potential limitations in verb understanding in present fashions.
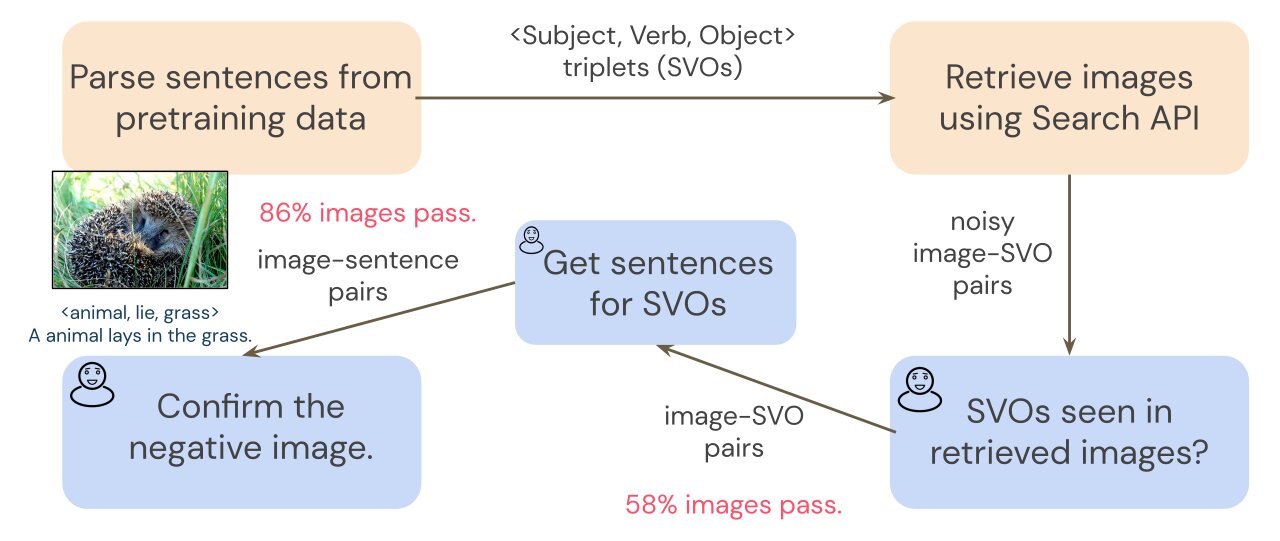
SVO-Probes contains 48,000 image-sentence pairs and exams understanding for greater than 400 verbs. Every sentence might be damaged right into a <Topic, Verb, Object> triplet (or SVO triplet) and paired with optimistic and damaging instance photographs. The damaging examples differ in just one manner: the Topic, Verb, or Object is modified. The determine above exhibits damaging examples by which the topic (left), verb (center), or object (proper) doesn’t match the picture. This job formulation makes it doable to isolate which elements of the sentence a mannequin has essentially the most hassle with. It additionally makes SVO-Probes more difficult than customary picture retrieval duties, the place damaging examples are sometimes utterly unrelated to the question sentence.
To create SVO-Probes, we query an image search with SVO triplets from a standard coaching dataset, Conceptual Captions (Sharma et al. 2018). As a result of picture search might be noisy, a preliminary annotation step filters the retrieved photographs to make sure we have now a clear set of image-SVO pairs. Since transformers are skilled on image-sentence pairs, not image-SVO pairs, we’d like image-sentence pairs to probe our mannequin. To gather sentences which describe every picture, annotators write a brief sentence for every picture that features the SVO triplet. For instance, given the SVO triplet <animal, lie, grass>, an annotator might write the sentence “An animal lays within the grass.” We then use the SVO annotations to pair every sentence with a damaging picture, and ask annotators to confirm negatives in a ultimate annotation step. See the determine under for particulars.
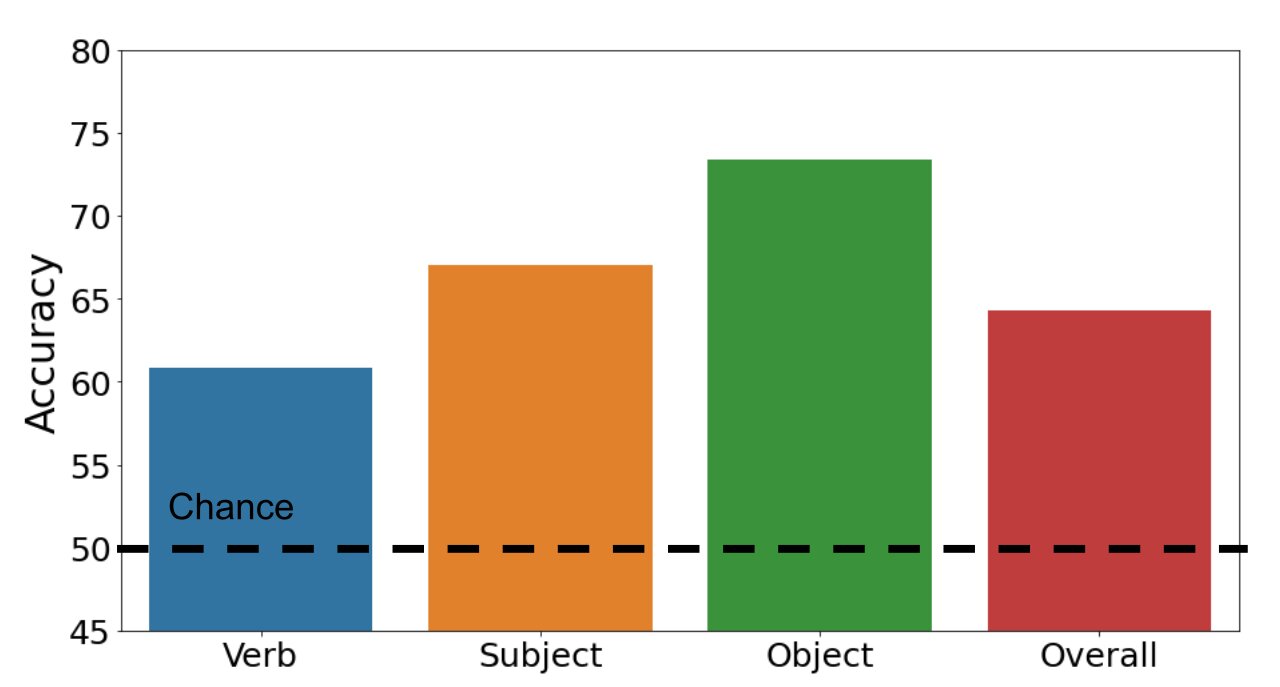
We study whether or not multimodal transformers can precisely classify examples as optimistic or damaging. The bar chart under illustrates our outcomes. Our dataset is difficult: our customary multimodal transformer mannequin achieves 64.3% accuracy total (likelihood is 50%). Whereas accuracy is 67.0% and 73.4% on topics and objects respectively, efficiency falls to 60.8% on verbs. This consequence exhibits that verb recognition is certainly difficult for imaginative and prescient and language fashions.
We additionally discover which mannequin architectures carry out greatest on our dataset. Surprisingly, fashions with weaker picture modeling carry out higher than the usual transformer mannequin. One speculation is that our customary mannequin (with stronger picture modeling skill) overfits the practice set. As each these fashions carry out worse on different language and imaginative and prescient duties, our focused probe job illuminates mannequin weaknesses that aren’t noticed on different benchmarks.
General, we discover that regardless of spectacular efficiency on benchmarks, multimodal transformers nonetheless battle with fine-grained understanding, particularly fine-grained verb understanding. We hope SVO-Probes will help drive exploration of verb understanding in language and imaginative and prescient fashions and encourage extra focused probe datasets.
Go to our SVO-Probes benchmark and models on GitHub: benchmark and fashions.

