
When deploying Deep Studying fashions at scale, it’s essential to successfully make the most of the underlying {hardware} to maximise efficiency and price advantages. For manufacturing workloads requiring excessive throughput and low latency, the collection of the Amazon Elastic Compute Cloud (EC2) occasion, mannequin serving stack, and deployment structure is essential. Inefficient structure can result in suboptimal utilization of the accelerators and unnecessarily excessive manufacturing value.
On this submit we stroll you thru the method of deploying FastAPI mannequin servers on AWS Inferentia units (discovered on Amazon EC2 Inf1 and Amazon EC Inf2 situations). We additionally show internet hosting a pattern mannequin that’s deployed in parallel throughout all NeuronCores for max {hardware} utilization.
Resolution overview
FastAPI is an open-source internet framework for serving Python functions that’s a lot quicker than conventional frameworks like Flask and Django. It makes use of an Asynchronous Server Gateway Interface (ASGI) as a substitute of the broadly used Web Server Gateway Interface (WSGI). ASGI processes incoming requests asynchronously versus WSGI which processes requests sequentially. This makes FastAPI the best option to deal with latency delicate requests. You should utilize FastAPI to deploy a server that hosts an endpoint on an Inferentia (Inf1/Inf2) situations that listens to consumer requests by way of a delegated port.
Our goal is to attain highest efficiency at lowest value by way of most utilization of the {hardware}. This enables us to deal with extra inference requests with fewer accelerators. Every AWS Inferentia1 machine comprises 4 NeuronCores-v1 and every AWS Inferentia2 machine comprises two NeuronCores-v2. The AWS Neuron SDK permits us to make the most of every of the NeuronCores in parallel, which provides us extra management in loading and inferring 4 or extra fashions in parallel with out sacrificing throughput.
With FastAPI, you have got your selection of Python internet server (Gunicorn, Uvicorn, Hypercorn, Daphne). These internet servers present and abstraction layer on prime of the underlying Machine Studying (ML) mannequin. The requesting consumer has the advantage of being oblivious to the hosted mannequin. A consumer doesn’t have to know the mannequin’s identify or model that has been deployed below the server; the endpoint identify is now only a proxy to a operate that hundreds and runs the mannequin. In distinction, in a framework-specific serving software, corresponding to TensorFlow Serving, the mannequin’s identify and model are a part of the endpoint identify. If the mannequin modifications on the server facet, the consumer has to know and alter its API name to the brand new endpoint accordingly. Subsequently, if you’re constantly evolving the model fashions, corresponding to within the case of A/B testing, then utilizing a generic Python internet server with FastAPI is a handy approach of serving fashions, as a result of the endpoint identify is static.
An ASGI server’s function is to spawn a specified variety of staff that hear for consumer requests and run the inference code. An vital functionality of the server is to verify the requested variety of staff can be found and lively. In case a employee is killed, the server should launch a brand new employee. On this context, the server and staff could also be recognized by their Unix course of ID (PID). For this submit, we use a Hypercorn server, which is a well-liked selection for Python internet servers.
On this submit, we share finest practices to deploy deep studying fashions with FastAPI on AWS Inferentia NeuronCores. We present which you could deploy a number of fashions on separate NeuronCores that may be referred to as concurrently. This setup will increase throughput as a result of a number of fashions may be inferred concurrently and NeuronCore utilization is absolutely optimized. The code may be discovered on the GitHub repo. The next determine reveals the structure of how you can arrange the answer on an EC2 Inf2 occasion.
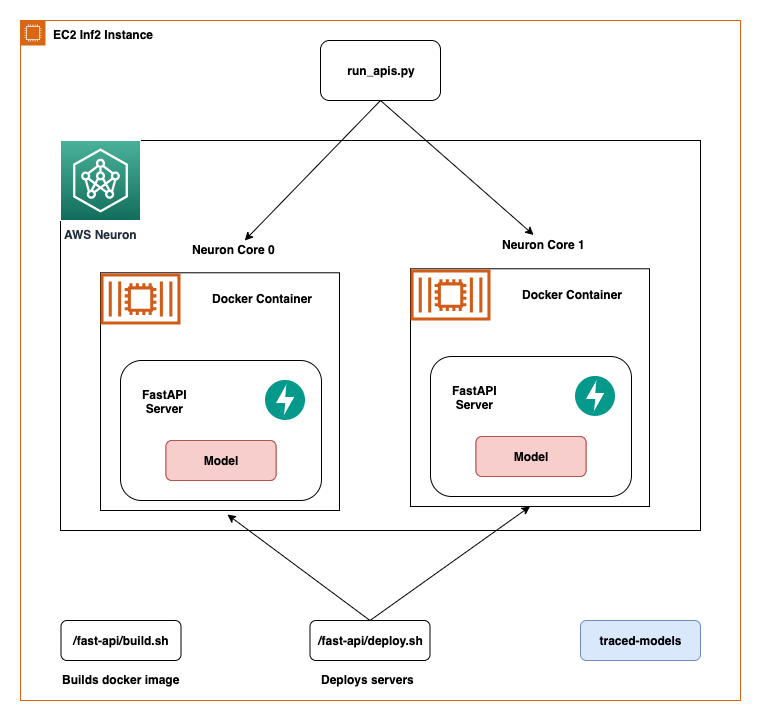
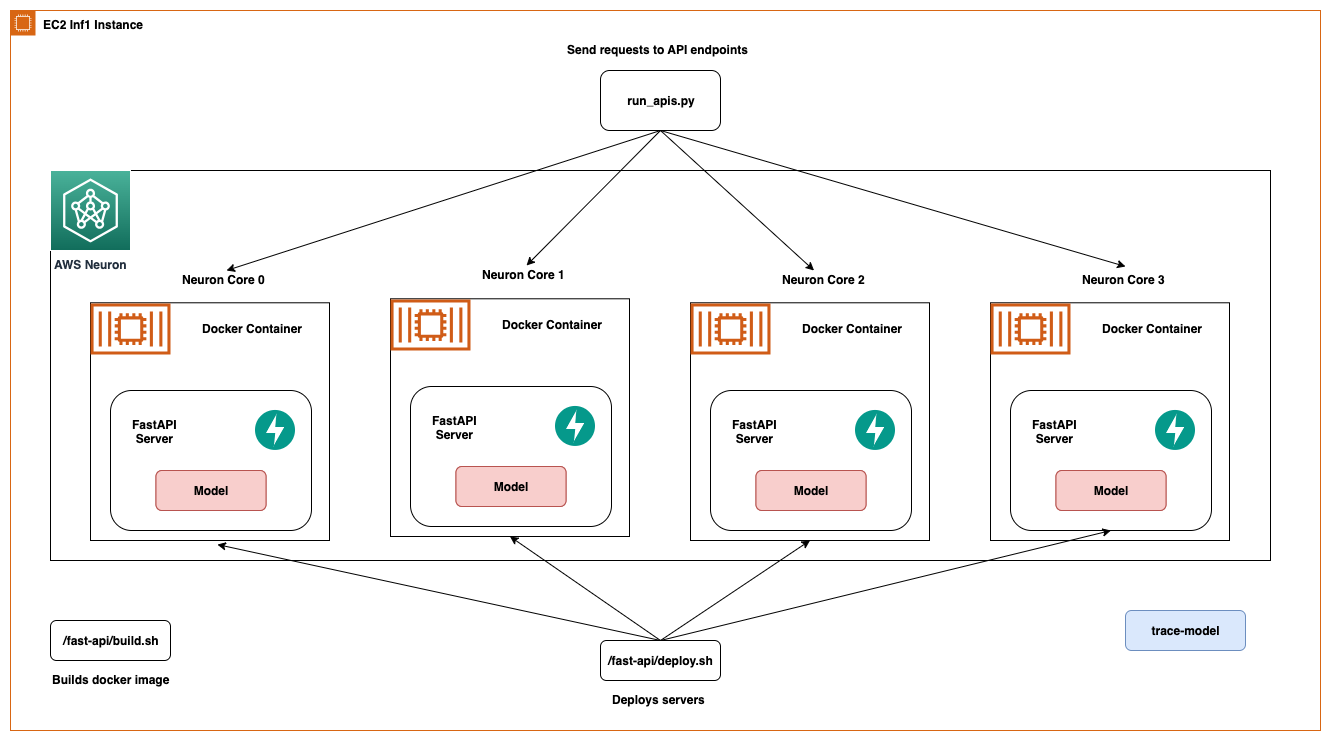
The identical structure applies to an EC2 Inf1 occasion sort besides it has 4 cores. In order that modifications the structure diagram slightly bit.
AWS Inferentia NeuronCores
Let’s dig slightly deeper into instruments offered by AWS Neuron to interact with the NeuronCores. The next tables reveals the variety of NeuronCores in every Inf1 and Inf2 occasion sort. The host vCPUs and the system reminiscence are shared throughout all out there NeuronCores.
| Occasion Measurement | # Inferentia Accelerators | # NeuronCores-v1 | vCPUs | Reminiscence (GiB) |
| Inf1.xlarge | 1 | 4 | 4 | 8 |
| Inf1.2xlarge | 1 | 4 | 8 | 16 |
| Inf1.6xlarge | 4 | 16 | 24 | 48 |
| Inf1.24xlarge | 16 | 64 | 96 | 192 |
| Occasion Measurement | # Inferentia Accelerators | # NeuronCores-v2 | vCPUs | Reminiscence (GiB) |
| Inf2.xlarge | 1 | 2 | 4 | 32 |
| Inf2.8xlarge | 1 | 2 | 32 | 32 |
| Inf2.24xlarge | 6 | 12 | 96 | 192 |
| Inf2.48xlarge | 12 | 24 | 192 | 384 |
Inf2 situations include the brand new NeuronCores-v2 compared to the NeuronCore-v1 within the Inf1 situations. Regardless of fewer cores, they can supply 4x greater throughput and 10x decrease latency than Inf1 situations. Inf2 situations are perfect for Deep Studying workloads like Generative AI, Massive Language Fashions (LLM) in OPT/GPT household and imaginative and prescient transformers like Secure Diffusion.
The Neuron Runtime is chargeable for operating fashions on Neuron units. Neuron Runtime determines which NeuronCore will run which mannequin and how you can run it. Configuration of Neuron Runtime is managed by way of the usage of environment variables on the course of stage. By default, Neuron framework extensions will maintain Neuron Runtime configuration on the person’s behalf; nevertheless, specific configurations are additionally attainable to attain extra optimized conduct.
Two fashionable surroundings variables are NEURON_RT_NUM_CORES and NEURON_RT_VISIBLE_CORES. With these surroundings variables, Python processes may be tied to a NeuronCore. With NEURON_RT_NUM_CORES, a specified variety of cores may be reserved for a course of, and with NEURON_RT_VISIBLE_CORES, a variety of NeuronCores may be reserved. For instance, NEURON_RT_NUM_CORES=2 myapp.py will reserve two cores and NEURON_RT_VISIBLE_CORES=’0-2’ myapp.py will reserve zero, one, and two cores for myapp.py. You possibly can reserve NeuronCores throughout units (AWS Inferentia chips) as properly. So, NEURON_RT_VISIBLE_CORES=’0-5’ myapp.py will reserve the primary 4 cores on device1 and one core on device2 in an Ec2 Inf1 occasion sort. Equally, on an EC2 Inf2 occasion sort, this configuration will reserve two cores throughout device1 and device2 and one core on device3. The next desk summarizes the configuration of those variables.
| Identify | Description | Sort | Anticipated Values | Default Worth | RT Model |
NEURON_RT_VISIBLE_CORES |
Vary of particular NeuronCores wanted by the method | Integer vary (like 1-3) | Any worth or vary between 0 to Max NeuronCore within the system | None | 2.0+ |
NEURON_RT_NUM_CORES |
Variety of NeuronCores required by the method | Integer | A worth from 1 to Max NeuronCore within the system | 0, which is interpreted as “all” | 2.0+ |
For an inventory of all surroundings variables, consult with Neuron Runtime Configuration.
By default, when loading fashions, fashions get loaded onto NeuronCore 0 after which NeuronCore 1 except explicitly acknowledged by the previous surroundings variables. As specified earlier, the NeuronCores share the out there host vCPUs and system reminiscence. Subsequently, fashions deployed on every NeuronCore will compete for the out there sources. This gained’t be a problem if the mannequin is using the NeuronCores to a big extent. But when a mannequin is operating solely partly on the NeuronCores and the remainder on host vCPUs then contemplating CPU availability per NeuronCore turn out to be vital. This impacts the selection of the occasion as properly.
The next desk reveals variety of host vCPUs and system reminiscence out there per mannequin if one mannequin was deployed to every NeuronCore. Relying in your utility’s NeuronCore utilization, vCPU, and reminiscence utilization, it is suggested to run checks to seek out out which configuration is most performant on your utility. The Neuron Top tool might help in visualizing core utilization and machine and host reminiscence utilization. Based mostly on these metrics an knowledgeable choice may be made. We show the usage of Neuron Prime on the finish of this weblog.
| Occasion Measurement | # Inferentia Accelerators | # Fashions | vCPUs/Mannequin | Reminiscence/Mannequin (GiB) |
| Inf1.xlarge | 1 | 4 | 1 | 2 |
| Inf1.2xlarge | 1 | 4 | 2 | 4 |
| Inf1.6xlarge | 4 | 16 | 1.5 | 3 |
| Inf1.24xlarge | 16 | 64 | 1.5 | 3 |
| Occasion Measurement | # Inferentia Accelerators | # Fashions | vCPUs/Mannequin | Reminiscence/Mannequin (GiB) |
| Inf2.xlarge | 1 | 2 | 2 | 8 |
| Inf2.8xlarge | 1 | 2 | 16 | 64 |
| Inf2.24xlarge | 6 | 12 | 8 | 32 |
| Inf2.48xlarge | 12 | 24 | 8 | 32 |
To check out the Neuron SDK options your self, take a look at the newest Neuron capabilities for PyTorch.
System setup
The next is the system setup used for this answer:
Arrange the answer
There are a few issues we have to do to setup the answer. Begin by creating an IAM function that your EC2 occasion goes to imagine that can permit it to push and pull from Amazon Elastic Container Registry.
Step 1: Setup the IAM function
- Begin by logging into the console and accessing IAM > Roles > Create Position
- Choose Trusted entity sort
AWS Service - Choose EC2 because the service below use-case
- Click on Subsequent and also you’ll be capable to see all insurance policies out there
- For the aim of this answer, we’re going to provide our EC2 occasion full entry to ECR. Filter for AmazonEC2ContainerRegistryFullAccess and choose it.
- Press subsequent and identify the function
inf-ecr-access
Word: the coverage we connected offers the EC2 occasion full entry to Amazon ECR. We strongly suggest following the principal of least-privilege for manufacturing workloads.
Step 2: Setup AWS CLI
In the event you’re utilizing the prescribed Deep Studying AMI listed above, it comes with AWS CLI put in. In the event you’re utilizing a special AMI (Amazon Linux 2023, Base Ubuntu and so on.), set up the CLI instruments by following this guide.
After getting the CLI instruments put in, configure the CLI utilizing the command aws configure. When you’ve got entry keys, you possibly can add them right here however don’t essentially want them to work together with AWS providers. We’re counting on IAM roles to try this.
Word: We have to enter at-least one worth (default area or default format) to create the default profile. For this instance, we’re going with us-east-2 because the area and json because the default output.
Clone the Github repository
The GitHub repo supplies all of the scripts essential to deploy fashions utilizing FastAPI on NeuronCores on AWS Inferentia situations. This instance makes use of Docker containers to make sure we will create reusable options. Included on this instance is the next config.properties file for customers to offer inputs.
The configuration file wants user-defined identify prefixes for the Docker picture and Docker containers. The construct.sh script within the fastapi and trace-model folders use this to create Docker photographs.
Compile a mannequin on AWS Inferentia
We’ll begin with tracing the mannequin and producing a PyTorch Torchscript .pt file. Begin by accessing trace-model listing and modifying the .env file. Relying upon the kind of occasion you selected, modify the CHIP_TYPE throughout the .env file. For instance, we are going to select Inf2 because the information. The identical steps apply to the deployment course of for Inf1.
Subsequent set the default area in the identical file. This area shall be used to create an ECR repository and Docker photographs shall be pushed to this repository. Additionally on this folder, we offer all of the scripts essential to hint a bert-base-uncased mannequin on AWS Inferentia. This script may very well be used for many fashions out there on Hugging Face. The Dockerfile has all of the dependencies to run fashions with Neuron and runs the trace-model.py code because the entry level.
Neuron compilation defined
The Neuron SDK’s API carefully resembles the PyTorch Python API. The torch.jit.hint() from PyTorch takes the mannequin and pattern enter tensor as arguments. The pattern inputs are fed to the mannequin and the operations which can be invoked as that enter makes its approach by way of the mannequin’s layers are recorded as TorchScript. To study extra about JIT Tracing in PyTorch, consult with the next documentation.
Identical to torch.jit.hint(), you possibly can examine to see in case your mannequin may be compiled on AWS Inferentia with the next code for inf1 situations.
For inf2, the library is known as torch_neuronx. Right here’s how one can take a look at your mannequin compilation in opposition to inf2 situations.
After creating the hint occasion, we will go the instance tensor enter like so:
And eventually save the ensuing TorchScript output on native disk
As proven within the previous code, you should use compiler_args and optimizations to optimize the deployment. For an in depth listing of arguments for the torch.neuron.hint API, consult with PyTorch-Neuron trace python API.
Hold the next vital factors in thoughts:
- The Neuron SDK doesn’t assist dynamic tensor shapes as of this writing. Subsequently, a mannequin should be compiled individually for various enter shapes. For extra info on operating inference on variable enter shapes with bucketing, consult with Running inference on variable input shapes with bucketing.
- In the event you face out of reminiscence points when compiling a mannequin, attempt compiling the mannequin on an AWS Inferentia occasion with extra vCPUs or reminiscence, and even a big c6i or r6i occasion as compilation solely makes use of CPUs. As soon as compiled, the traced mannequin can most likely be run on smaller AWS Inferentia occasion sizes.
Construct course of clarification
Now we are going to construct this container by operating build.sh. The construct script file merely creates the Docker picture by pulling a base Deep Studying Container Picture and putting in the HuggingFace transformers bundle. Based mostly on the CHIP_TYPE specified within the .env file, the docker.properties file decides the suitable BASE_IMAGE. This BASE_IMAGE factors to a Deep Studying Container Picture for Neuron Runtime offered by AWS.
It’s out there by way of a non-public ECR repository. Earlier than we will pull the picture, we have to login and get short-term AWS credentials.
Word: we have to exchange the area listed within the command specified by the area flag and throughout the repository URI with the area we put within the .env file.
For the aim of constructing this course of simpler, we will use the fetch-credentials.sh file. The area shall be taken from the .env file mechanically.
Subsequent, we’ll push the picture utilizing the script push.sh. The push script creates a repository in Amazon ECR for you and pushes the container picture.
Lastly, when the picture is constructed and pushed, we will run it as a container by operating run.sh and tail operating logs with logs.sh. Within the compiler logs (see the next screenshot), you will note the proportion of arithmetic operators compiled on Neuron and share of mannequin sub-graphs efficiently compiled on Neuron. The screenshot reveals the compiler logs for the bert-base-uncased-squad2 mannequin. The logs present that 95.64% of the arithmetic operators have been compiled, and it additionally offers an inventory of operators that have been compiled on Neuron and those who aren’t supported.
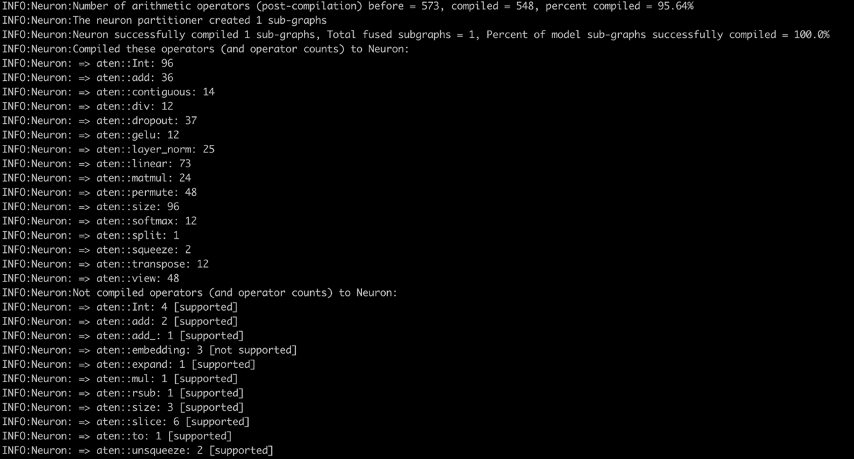
Here is a list of all supported operators within the newest PyTorch Neuron bundle. Equally, here is the list of all supported operators within the newest PyTorch Neuronx bundle.
Deploy fashions with FastAPI
After the fashions are compiled, the traced mannequin shall be current within the trace-model folder. On this instance, we’ve positioned the traced mannequin for a batch measurement of 1. We contemplate a batch measurement of 1 right here to account for these use instances the place a better batch measurement just isn’t possible or required. To be used instances the place greater batch sizes are wanted, the torch.neuron.DataParallel (for Inf1) or torch.neuronx.DataParallel (for Inf2) API might also be helpful.
The fast-api folder supplies all the mandatory scripts to deploy fashions with FastAPI. To deploy the fashions with none modifications, merely run the deploy.sh script and it’ll construct a FastAPI container picture, run containers on the required variety of cores, and deploy the required variety of fashions per server in every FastAPI mannequin server. This folder additionally comprises a .env file, modify it to mirror the right CHIP_TYPE and AWS_DEFAULT_REGION.
Word: FastAPI scripts depend on the identical surroundings variables used to construct, push and run the photographs as containers. FastAPI deployment scripts will use the final recognized values from these variables. So, should you traced the mannequin for Inf1 occasion sort final, that mannequin shall be deployed by way of these scripts.
The fastapi-server.py file which is chargeable for internet hosting the server and sending the requests to the mannequin does the next:
- Reads the variety of fashions per server and the situation of the compiled mannequin from the properties file
- Units seen NeuronCores as surroundings variables to the Docker container and reads the surroundings variables to specify which NeuronCores to make use of
- Supplies an inference API for the
bert-base-uncased-squad2mannequin - With
jit.load(), hundreds the variety of fashions per server as specified within the config and shops the fashions and the required tokenizers in international dictionaries
With this setup, it might be comparatively simple to arrange APIs that listing which fashions and what number of fashions are saved in every NeuronCore. Equally, APIs may very well be written to delete fashions from particular NeuronCores.
The Dockerfile for constructing FastAPI containers is constructed on the Docker picture we constructed for tracing the fashions. Because of this the docker.properties file specifies the ECR path to the Docker picture for tracing the fashions. In our setup, the Docker containers throughout all NeuronCores are related, so we will construct one picture and run a number of containers from one picture. To keep away from any entry level errors, we specify ENTRYPOINT ["/usr/bin/env"] within the Dockerfile earlier than operating the startup.sh script, which appears like hypercorn fastapi-server:app -b 0.0.0.0:8080. This startup script is identical for all containers. In the event you’re utilizing the identical base picture as for tracing fashions, you possibly can construct this container by merely operating the construct.sh script. The push.sh script stays the identical as earlier than for tracing fashions. The modified Docker picture and container identify are offered by the docker.properties file.
The run.sh file does the next:
- Reads the Docker picture and container identify from the properties file, which in flip reads the
config.propertiesfile, which has anum_coresperson setting - Begins a loop from 0 to
num_coresand for every core:- Units the port quantity and machine quantity
- Units the
NEURON_RT_VISIBLE_CORESsurroundings variable - Specifies the quantity mount
- Runs a Docker container
For readability, the Docker run command for deploying in NeuronCore 0 for Inf1 would seem like the next code:
The run command for deploying in NeuronCore 5 would seem like the next code:
After the containers are deployed, we use the run_apis.py script, which calls the APIs in parallel threads. The code is ready as much as name six fashions deployed, one on every NeuronCore, however may be simply modified to a special setting. We name the APIs from the consumer facet as follows:
Monitor NeuronCore
After the mannequin servers are deployed, to watch NeuronCore utilization, we could use neuron-top to look at in actual time the utilization share of every NeuronCore. neuron-top is a CLI software within the Neuron SDK to offer info corresponding to NeuronCore, vCPU, and reminiscence utilization. In a separate terminal, enter the next command:
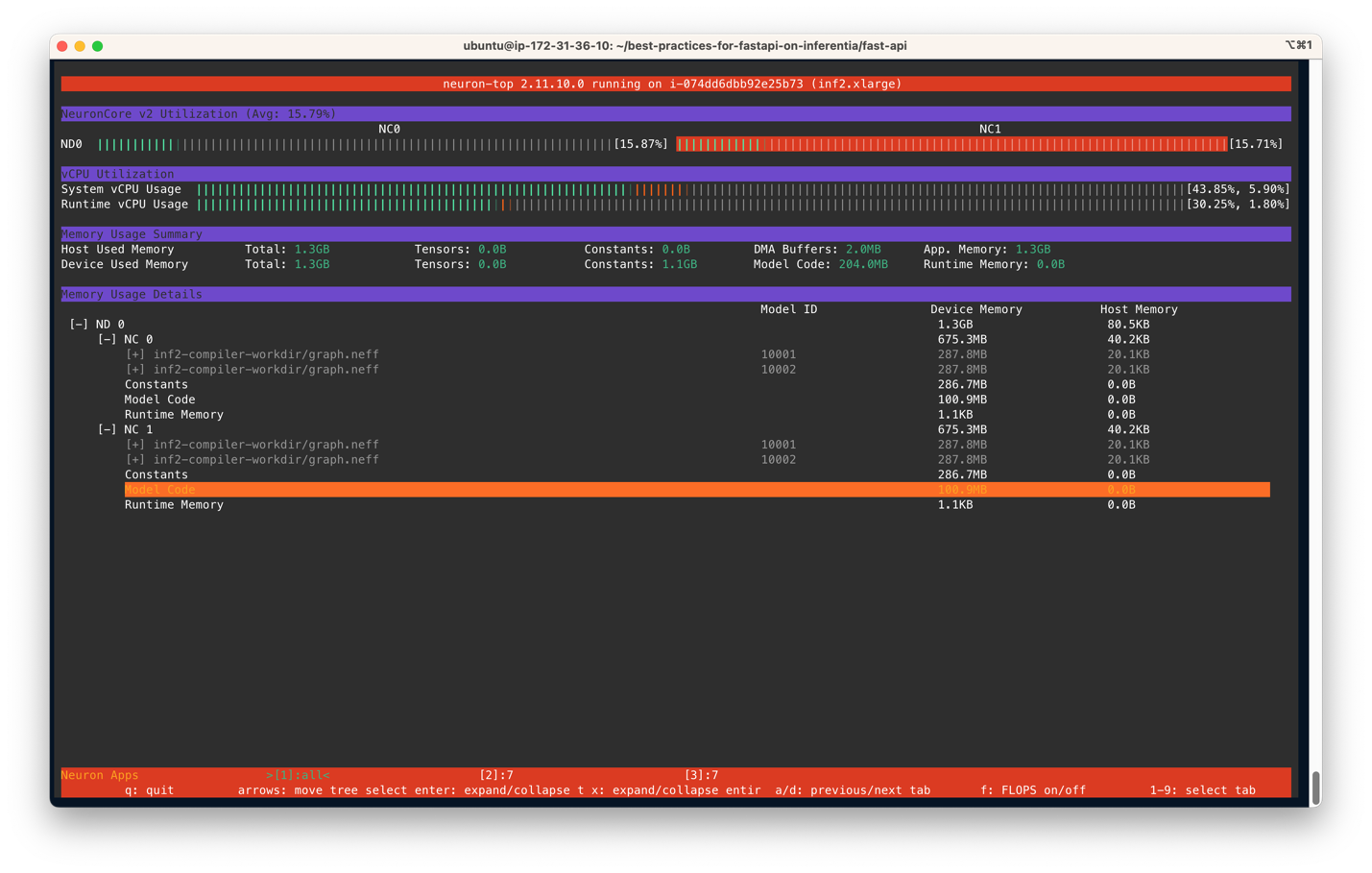
You output ought to be just like the next determine. On this state of affairs, we’ve specified to make use of two NeuronCores and two fashions per server on an Inf2.xlarge occasion. The next screenshot reveals that two fashions of measurement 287.8MB every are loaded on two NeuronCores. With a complete of 4 fashions loaded, you possibly can see the machine reminiscence used is 1.3 GB. Use the arrow keys to maneuver between the NeuronCores on completely different units
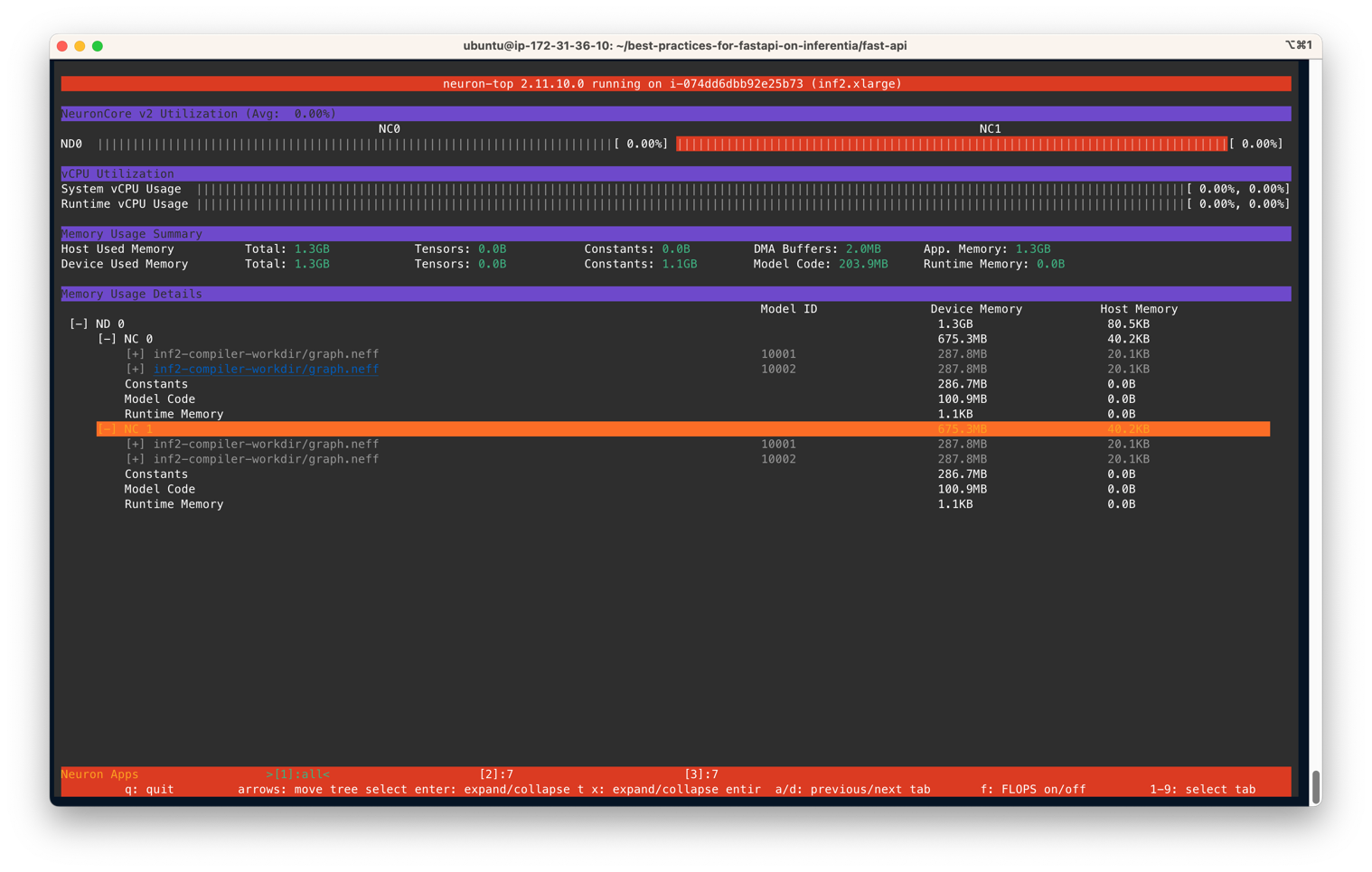
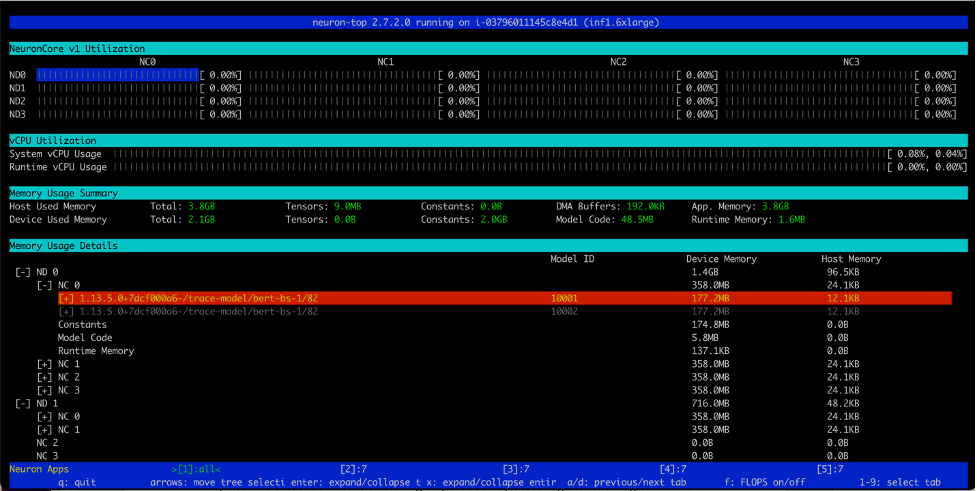
Equally, on an Inf1.16xlarge occasion sort we see a complete of 12 fashions (2 fashions per core over 6 cores) loaded. A complete reminiscence of two.1GB is consumed and each mannequin is 177.2MB in measurement.
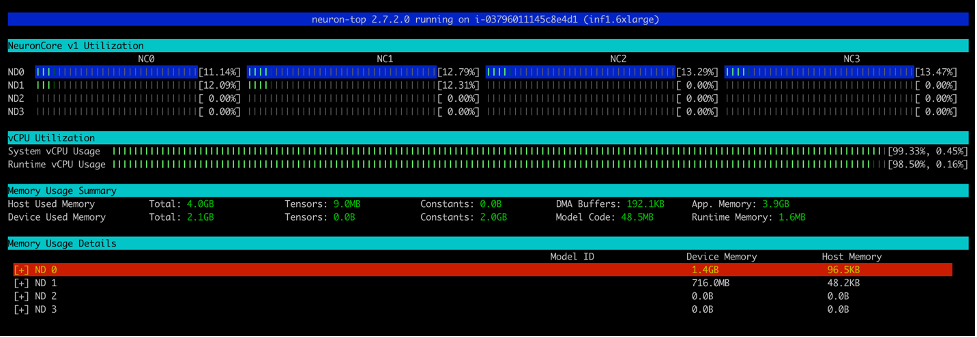
After you run the run_apis.py script, you possibly can see the proportion of utilization of every of the six NeuronCores (see the next screenshot). You can too see the system vCPU utilization and runtime vCPU utilization.
The next screenshot reveals the Inf2 occasion core utilization share.
Equally, this screenshot reveals core utilization in an inf1.6xlarge occasion sort.
Clear up
To wash up all of the Docker containers you created, we offer a cleanup.sh script that removes all operating and stopped containers. This script will take away all containers, so don’t use it if you wish to hold some containers operating.
Conclusion
Manufacturing workloads usually have excessive throughput, low latency, and price necessities. Inefficient architectures that sub-optimally make the most of accelerators might result in unnecessarily excessive manufacturing prices. On this submit, we confirmed how you can optimally make the most of NeuronCores with FastAPI to maximise throughput at minimal latency. We’ve printed the directions on our GitHub repo. With this answer structure, you possibly can deploy a number of fashions in every NeuronCore and function a number of fashions in parallel on completely different NeuronCores with out shedding efficiency. For extra info on how you can deploy fashions at scale with providers like Amazon Elastic Kubernetes Service (Amazon EKS), consult with Serve 3,000 deep learning models on Amazon EKS with AWS Inferentia for under $50 an hour.
In regards to the authors
 Ankur Srivastava is a Sr. Options Architect within the ML Frameworks Group. He focuses on serving to clients with self-managed distributed coaching and inference at scale on AWS. His expertise consists of industrial predictive upkeep, digital twins, probabilistic design optimization and has accomplished his doctoral research from Mechanical Engineering at Rice College and post-doctoral analysis from Massachusetts Institute of Expertise.
Ankur Srivastava is a Sr. Options Architect within the ML Frameworks Group. He focuses on serving to clients with self-managed distributed coaching and inference at scale on AWS. His expertise consists of industrial predictive upkeep, digital twins, probabilistic design optimization and has accomplished his doctoral research from Mechanical Engineering at Rice College and post-doctoral analysis from Massachusetts Institute of Expertise.
 Okay.C. Tung is a Senior Resolution Architect in AWS Annapurna Labs. He makes a speciality of giant deep studying mannequin coaching and deployment at scale in cloud. He has a Ph.D. in molecular biophysics from the College of Texas Southwestern Medical Heart in Dallas. He has spoken at AWS Summits and AWS Reinvent. Right this moment he helps clients to coach and deploy giant PyTorch and TensorFlow fashions in AWS cloud. He’s the creator of two books: Learn TensorFlow Enterprise and TensorFlow 2 Pocket Reference.
Okay.C. Tung is a Senior Resolution Architect in AWS Annapurna Labs. He makes a speciality of giant deep studying mannequin coaching and deployment at scale in cloud. He has a Ph.D. in molecular biophysics from the College of Texas Southwestern Medical Heart in Dallas. He has spoken at AWS Summits and AWS Reinvent. Right this moment he helps clients to coach and deploy giant PyTorch and TensorFlow fashions in AWS cloud. He’s the creator of two books: Learn TensorFlow Enterprise and TensorFlow 2 Pocket Reference.
 Pronoy Chopra is a Senior Options Architect with the Startups Generative AI crew at AWS. He makes a speciality of architecting and creating IoT and Machine Studying options. He has co-founded two startups prior to now and enjoys being hands-on with tasks within the IoT, AI/ML and Serverless area.
Pronoy Chopra is a Senior Options Architect with the Startups Generative AI crew at AWS. He makes a speciality of architecting and creating IoT and Machine Studying options. He has co-founded two startups prior to now and enjoys being hands-on with tasks within the IoT, AI/ML and Serverless area.

