
Reward is the driving drive for reinforcement studying (RL) brokers. Given its central position in RL, reward is commonly assumed to be suitably basic in its expressivity, as summarized by Sutton and Littman’s reward speculation:
“…all of what we imply by objectives and functions could be nicely considered maximization of the anticipated worth of the cumulative sum of a obtained scalar sign (reward).”
– SUTTON (2004), LITTMAN (2017)
In our work, we take first steps towards a scientific examine of this speculation. To take action, we take into account the next thought experiment involving Alice, a designer, and Bob, a studying agent:
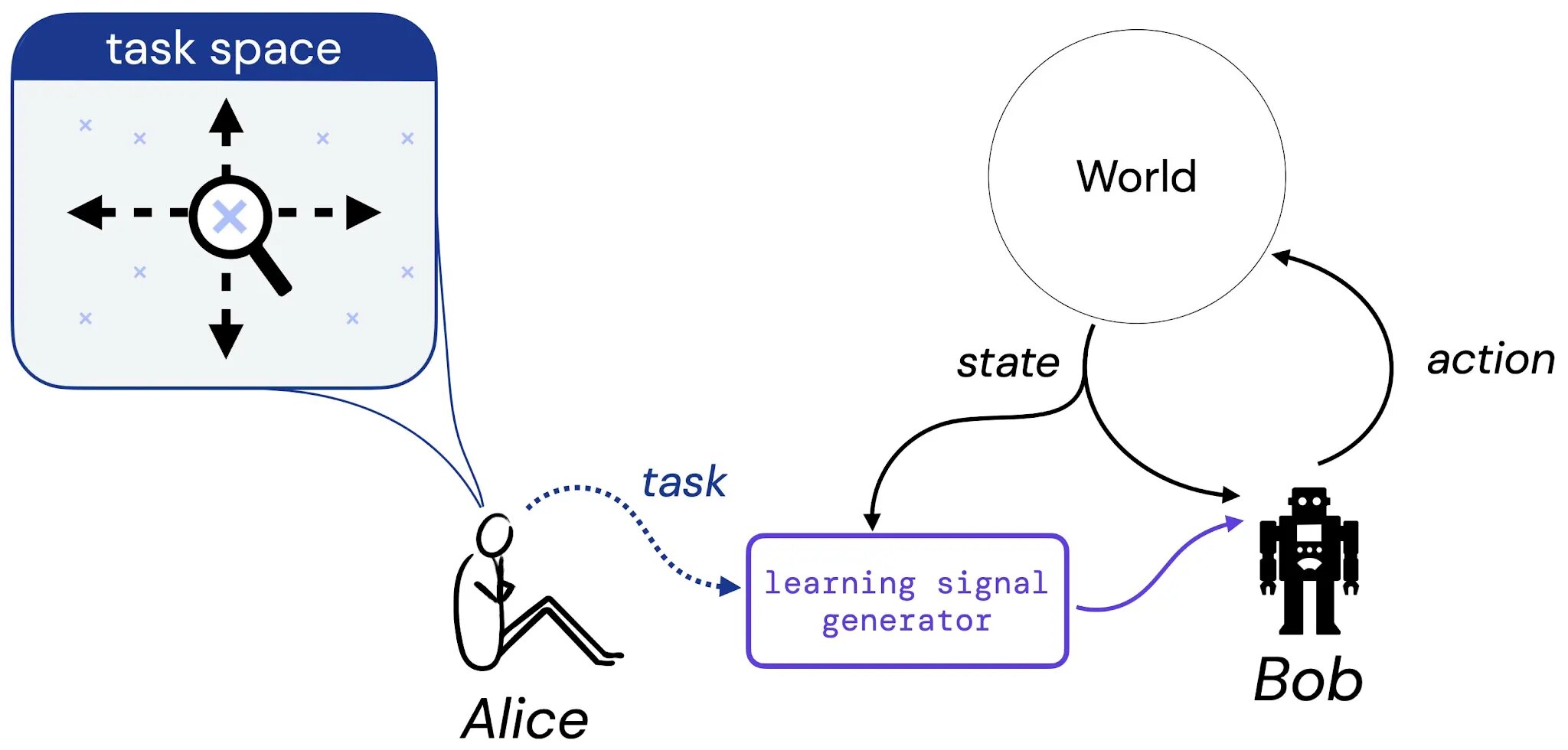
We suppose that Alice thinks of a job she may like Bob to study to unravel – this job might be within the kind a a pure language description (“steadiness this pole”), an imagined state of affairs (“attain any of the successful configurations of a chess board”), or one thing extra conventional like a reward or worth operate. Then, we think about Alice interprets her selection of job into some generator that can present studying sign (resembling reward) to Bob (a studying agent), who will study from this sign all through his lifetime. We then floor our examine of the reward speculation by addressing the next query: given Alice’s selection of job, is there all the time a reward operate that may convey this job to Bob?
What’s a job?
To make our examine of this query concrete, we first limit focus to a few sorts of job. Specifically, we introduce three job sorts that we imagine seize smart sorts of duties: 1) A set of acceptable insurance policies (SOAP), 2) A coverage order (PO), and three) A trajectory order (TO). These three types of duties signify concrete situations of the sorts of job we would need an agent to study to unravel.
.jpg)
We then examine whether or not reward is able to capturing every of those job sorts in finite environments. Crucially, we solely focus consideration on Markov reward capabilities; as an illustration, given a state area that’s ample to kind a job resembling (x,y) pairs in a grid world, is there a reward operate that solely relies on this similar state area that may seize the duty?
First Foremost Consequence
Our first important end result reveals that for every of the three job sorts, there are environment-task pairs for which there isn’t a Markov reward operate that may seize the duty. One instance of such a pair is the “go all the best way across the grid clockwise or counterclockwise” job in a typical grid world:
.jpg)
This job is of course captured by a SOAP that consists of two acceptable insurance policies: the “clockwise” coverage (in blue) and the “counterclockwise” coverage (in purple). For a Markov reward operate to specific this job, it will must make these two insurance policies strictly larger in worth than all different deterministic insurance policies. Nevertheless, there isn’t a such Markov reward operate: the optimality of a single “transfer clockwise” motion will rely upon whether or not the agent was already transferring in that route up to now. For the reason that reward operate have to be Markov, it can not convey this sort of info. Comparable examples show that Markov reward can not seize each coverage order and trajectory order, too.
Second Foremost Consequence
On condition that some duties could be captured and a few can not, we subsequent discover whether or not there’s an environment friendly process for figuring out whether or not a given job could be captured by reward in a given atmosphere. Additional, if there’s a reward operate that captures the given job, we’d ideally like to have the ability to output such a reward operate. Our second result’s a constructive end result which says that for any finite environment-task pair, there’s a process that may 1) determine whether or not the duty could be captured by Markov reward within the given atmosphere, and a couple of) outputs the specified reward operate that precisely conveys the duty, when such a operate exists.
This work establishes preliminary pathways towards understanding the scope of the reward speculation, however there’s a lot nonetheless to be finished to generalize these outcomes past finite environments, Markov rewards, and easy notions of “job” and “expressivity”. We hope this work offers new conceptual views on reward and its place in reinforcement studying.

