
Introduction to SharePoint
SharePoint, developed by Microsoft, is a web-based platform providing a flexible suite of instruments designed to optimize and streamline doc and file sharing, collaboration, and administration inside companies and organizations. It allows a centralized, safe, and simply accessible repository for info.
Historically used as an intranet and content material administration system, SharePoint additionally gives a strong framework for creating custom-made purposes. It boasts spectacular integration with different Microsoft merchandise like Groups and Workplace 365, enhancing the seamless workflow of information and communication.
One in all its key strengths is the power to create collaborative environments or workspaces for groups. Group members can co-author paperwork in real-time, share knowledge, and handle duties, fostering efficient collaboration and boosting productiveness. SharePoint’s model management and approval workflows additionally scale back the chance of information loss or unapproved adjustments.
On the safety entrance, SharePoint presents highly effective knowledge safety options, together with encryption, entry management, and compliance settings, making certain delicate info stays confidential.
Nonetheless, SharePoint requires meticulous planning for profitable implementation and will pose a studying curve for some customers, making correct coaching important. Regardless of this, its strong options make SharePoint a invaluable device for any enterprise within the digital age.
Automated OCR and Doc Information Extraction workflows in SharePoint
The world is more and more transferring in the direction of digitization. On this context, Optical Character Recognition (OCR) and Doc Information Extraction play a vital position, particularly in platforms like SharePoint, which is extensively utilized by companies for collaboration and doc administration.
OCR is a expertise that converts various kinds of paperwork, similar to scanned paper paperwork, PDF recordsdata or pictures captured by a digital digicam, into editable and searchable knowledge. That is notably helpful when coping with massive volumes of information, the place handbook knowledge entry is time-consuming and vulnerable to errors.
As an example, a regulation agency might have 1000’s of contracts of their SharePoint repository. With OCR, they will shortly convert these scanned contracts into searchable textual content, enabling them to search out related info swiftly. Equally, an accounting division may make the most of OCR to digitize receipts and invoices saved in SharePoint, making it simpler to extract vital monetary knowledge for evaluation and auditing.
Doc knowledge extraction goes hand-in-hand with OCR. Whereas OCR makes a doc searchable, knowledge extraction retrieves particular info from these paperwork. As an example, extracting dates, names, quantities, addresses, or particular clauses from contracts, invoices, or varieties.
An AI-based device like Nanonets can be utilized along side SharePoint for this function. Nanonets’ OCR and knowledge extraction capabilities will help automate routine duties, enhancing productiveness, and decreasing errors. With the fitting setup, end-to-end workflows could be created which might be sensible and related to varied real-life situations. Under are just a few examples:
Whereas making a workflow on https://app.nanonets.com, you possibly can select to import from a SharePoint listing to extract knowledge from incoming paperwork, after which export the extracted knowledge utilizing our export integrations with varied software program / ERPs and databases.
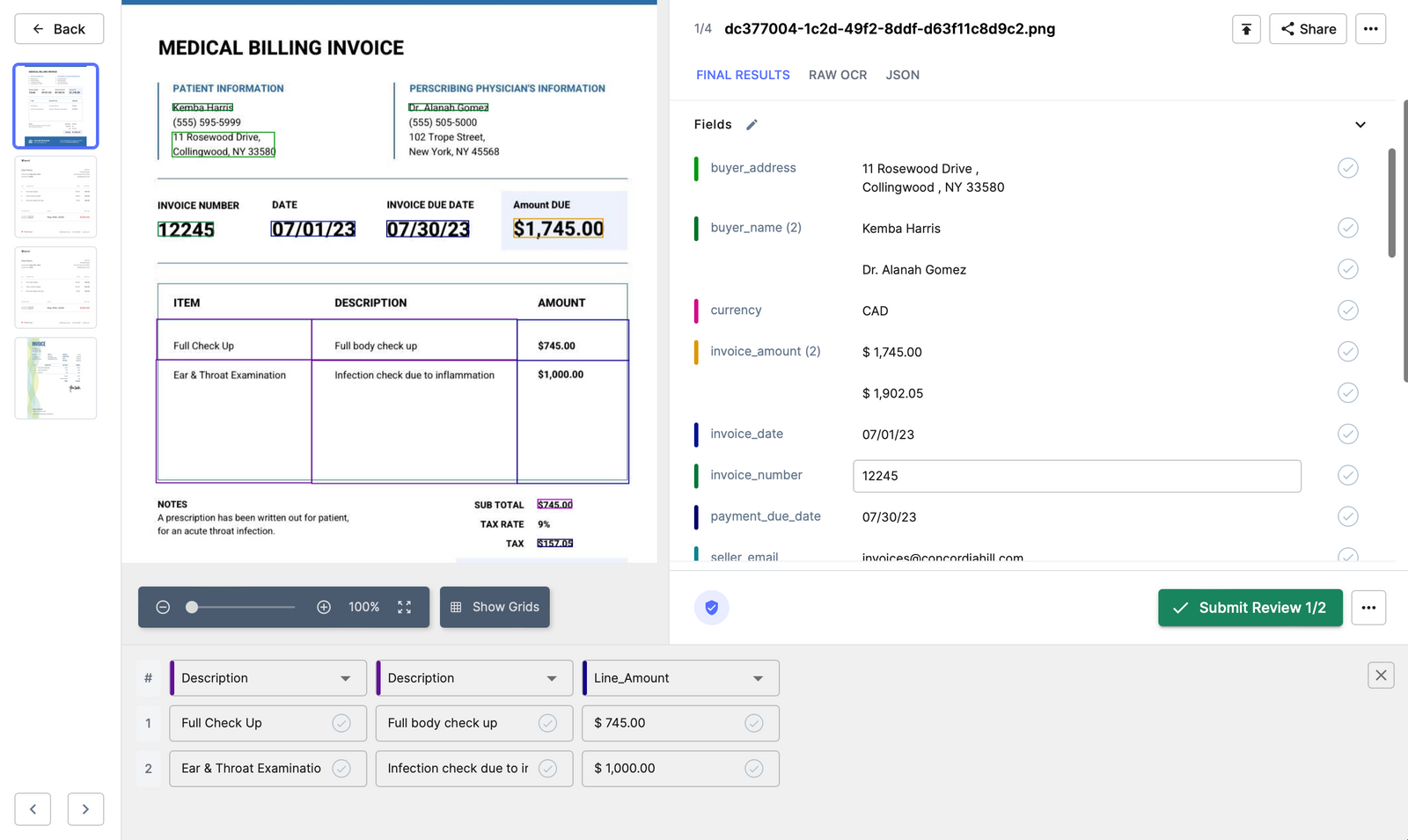
Bill Processing: Firms obtain quite a few invoices every day. By integrating Nanonets with SharePoint, these invoices could be mechanically scanned, knowledge like bill quantity, date, complete quantity, and many others., could be extracted, verified, after which uploaded to an accounting software program, say Quickbooks, for additional processing.
Resume Screening: HR departments typically should sift by way of tons of of resumes. With SharePoint and Nanonets, resumes could be mechanically parsed and vital info like title, contact info, work historical past, and abilities could be extracted and analyzed to shortlist potential candidates.
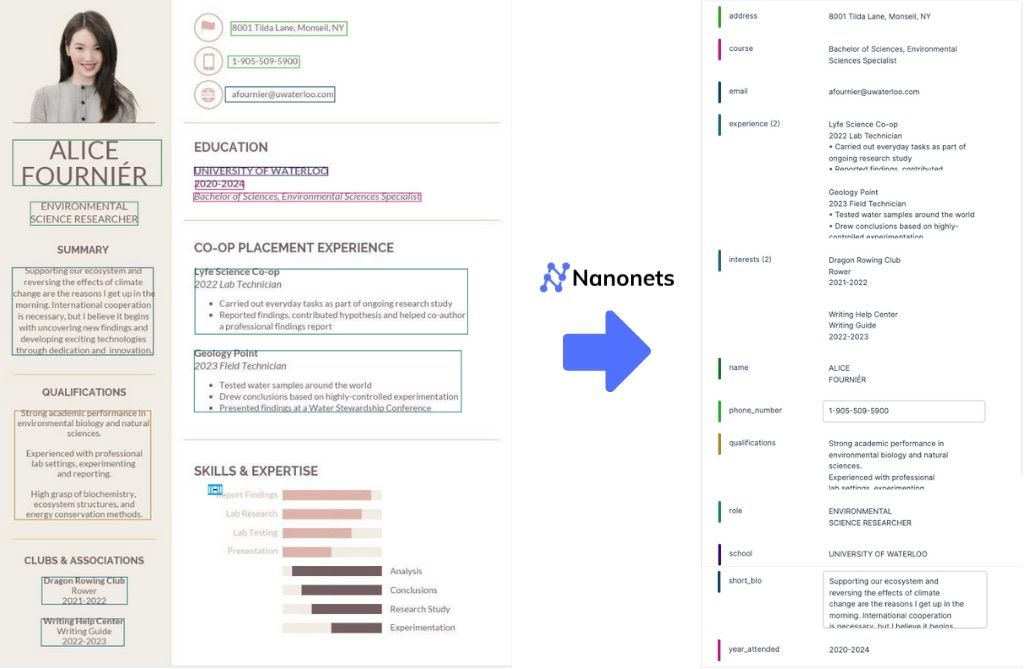
Contract Administration: Companies typically have to handle and assessment a number of contracts. Nanonets can extract key contract phrases, dates, and obligations, which might then be saved in SharePoint and linked to a calendar for reminders on key dates.
Medical Report Evaluation: Hospitals and healthcare establishments typically want to research affected person data. SharePoint can retailer these paperwork, whereas Nanonets can extract affected person info, analysis, prescriptions, and many others. This will help in trending evaluation, predicting affected person outcomes, and providing higher healthcare companies.
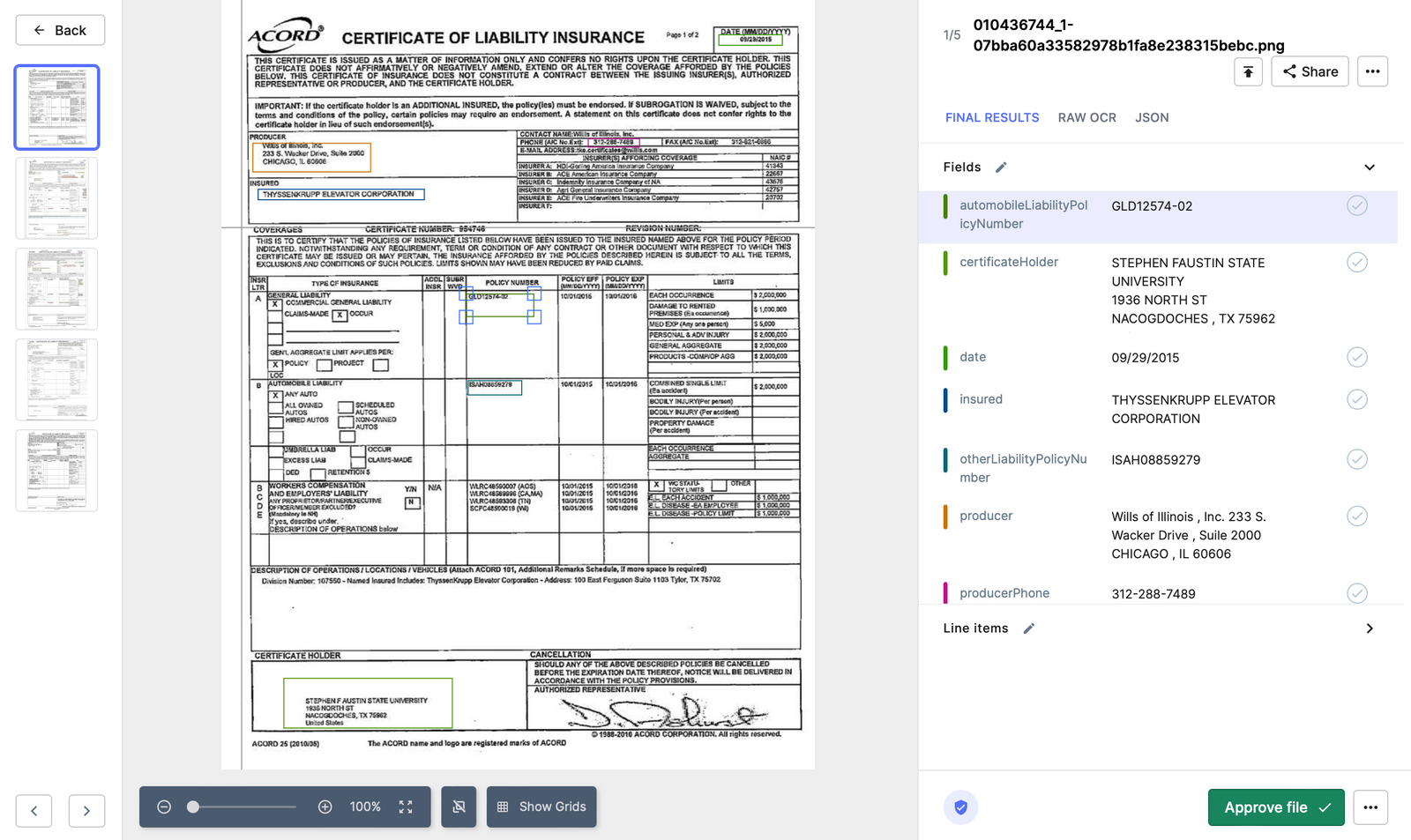
Claims Processing: Insurance coverage corporations typically obtain numerous claims in varied codecs. Utilizing OCR and knowledge extraction, the related knowledge could be pulled from these paperwork and fed right into a case administration system for additional processing.
These are just some examples. The mix of SharePoint and Nanonets, utilizing OCR and Doc Information Extraction, can create highly effective workflows that save time, scale back errors, and enhance operational effectivity throughout quite a few sectors. This expertise partnership is greater than a luxurious; it is quick changing into a necessity for companies that wish to keep aggressive within the digital age.
Learn how to Arrange Nanonets OCR in SharePoint

- Select a pretrained mannequin primarily based in your doc sort / create your personal doc extractor inside minutes.

- Upon getting created the mannequin, navigate to the Workflow part within the left navigation pane.
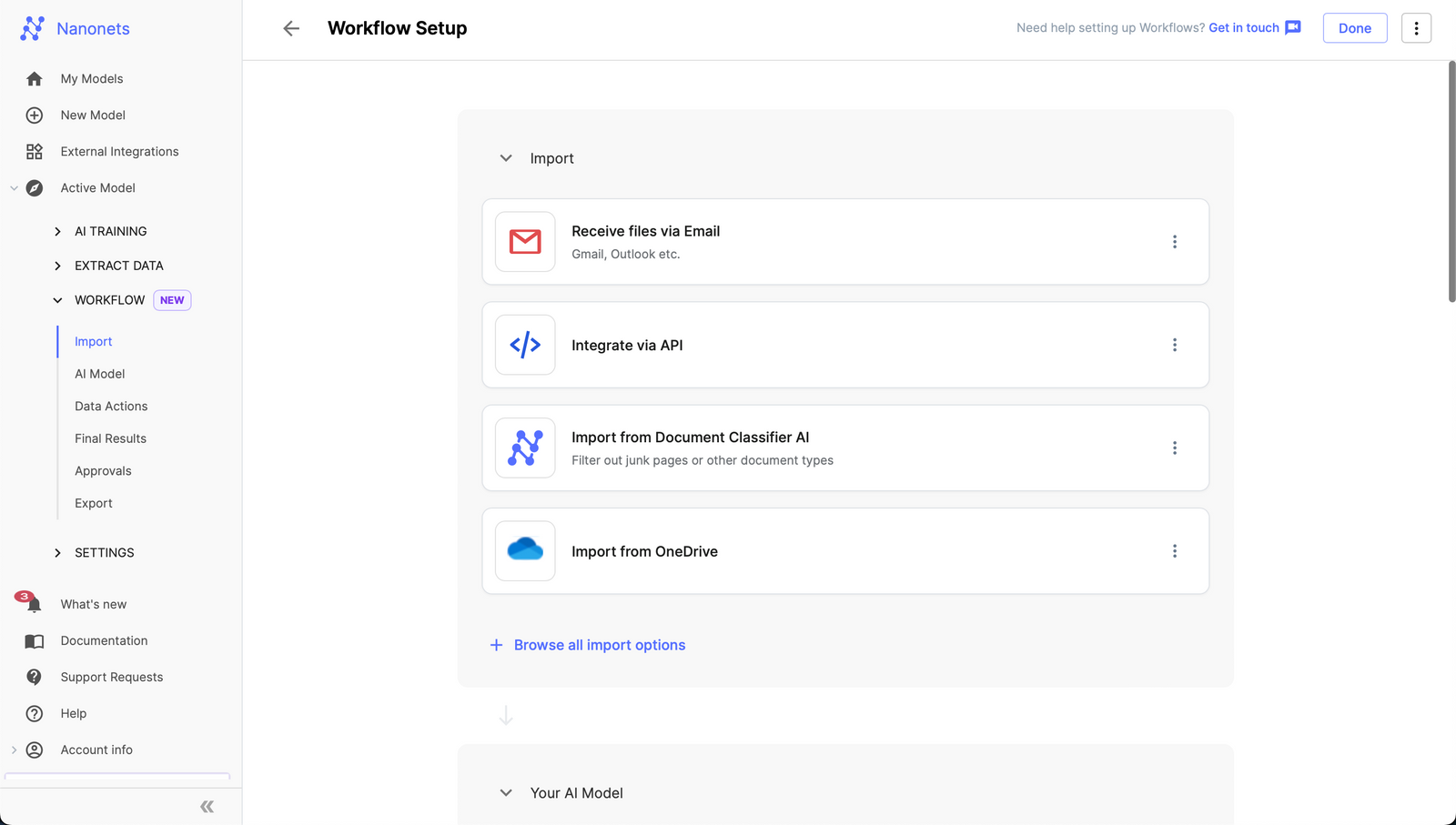
- Go to the import tab.
- Choose SharePoint from the “Browse all import choices” modal.
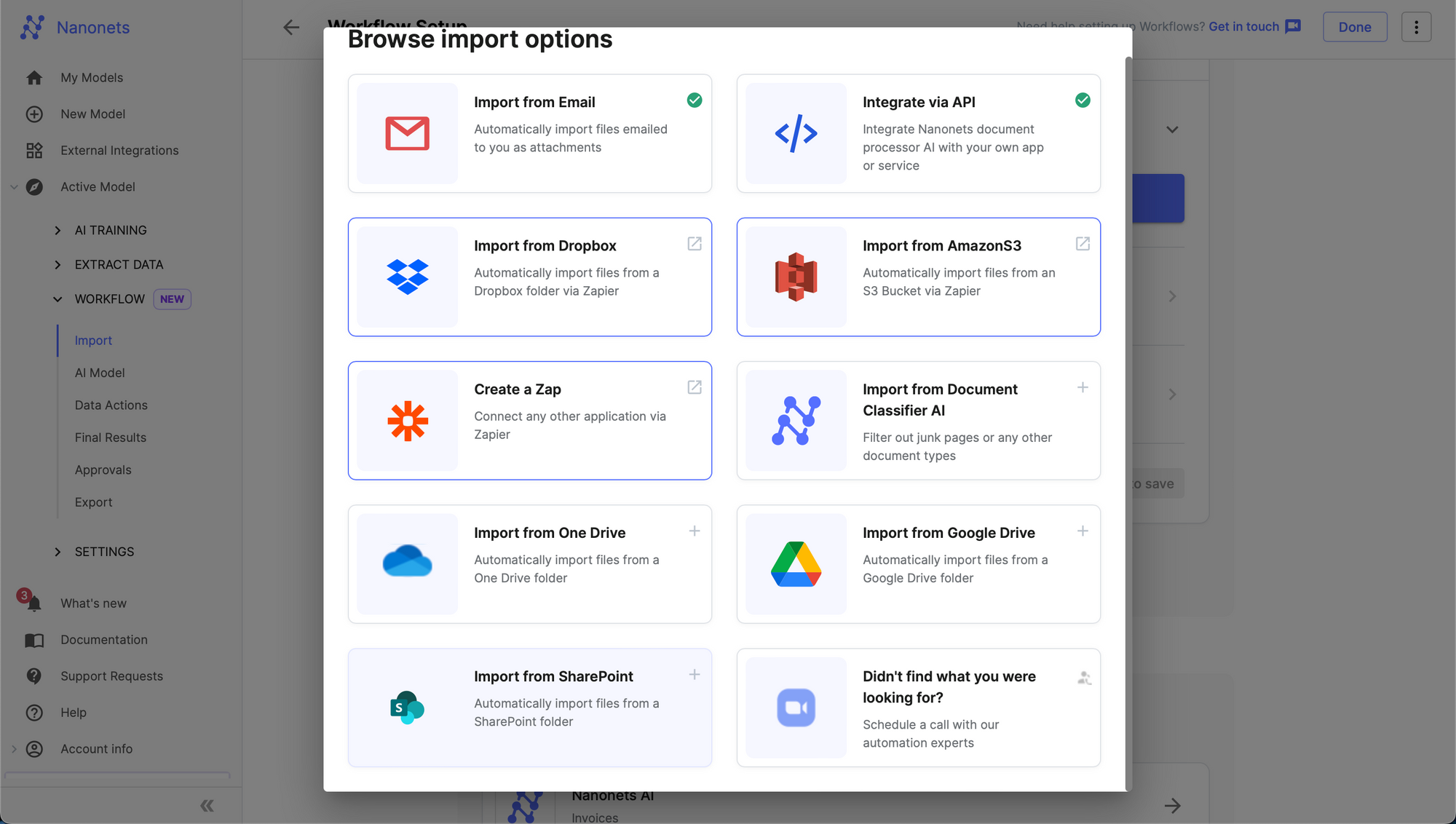
6. Authenticate your Microsoft SharePoint Account.
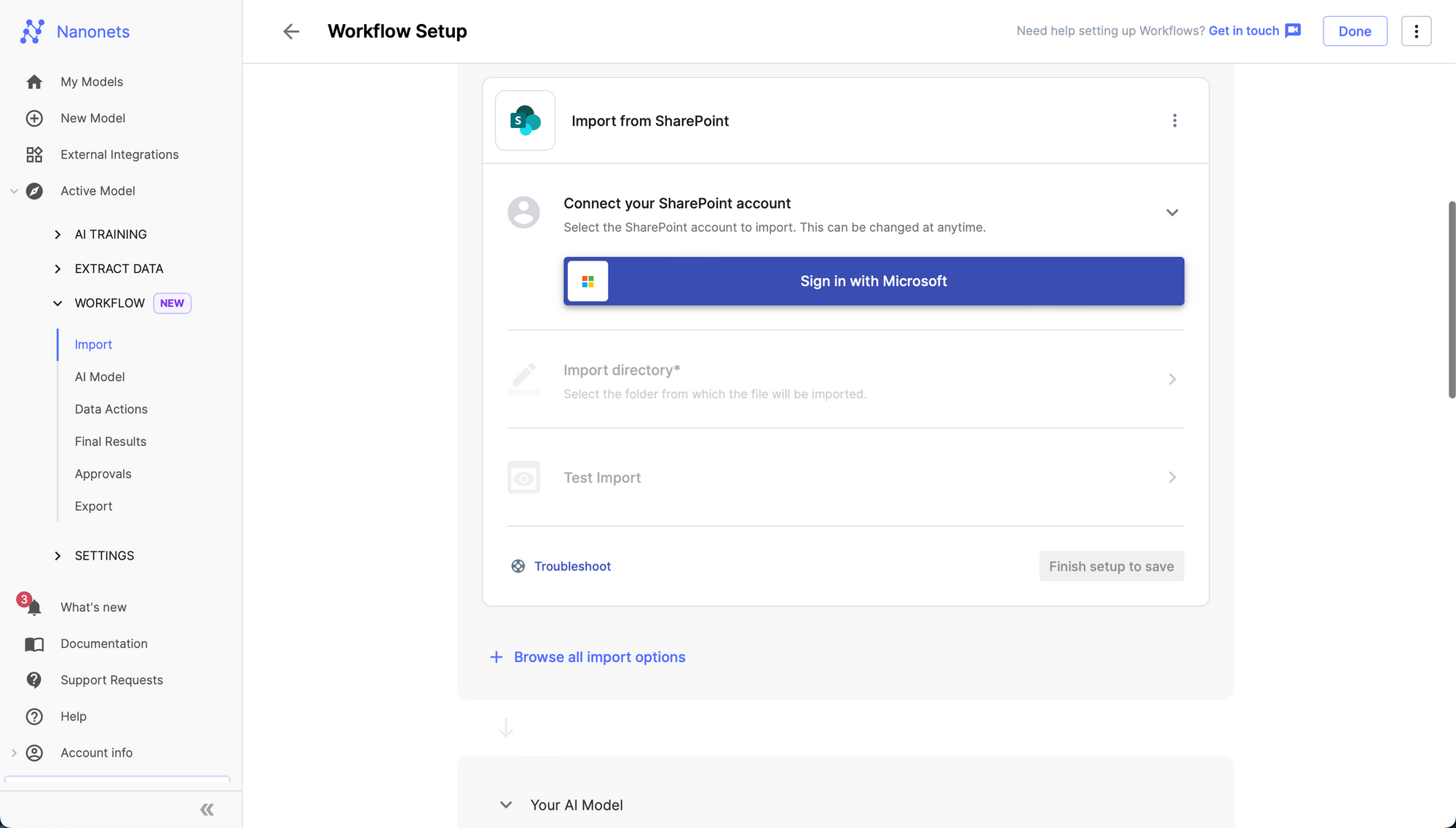
7. Select the listing you wish to import from.
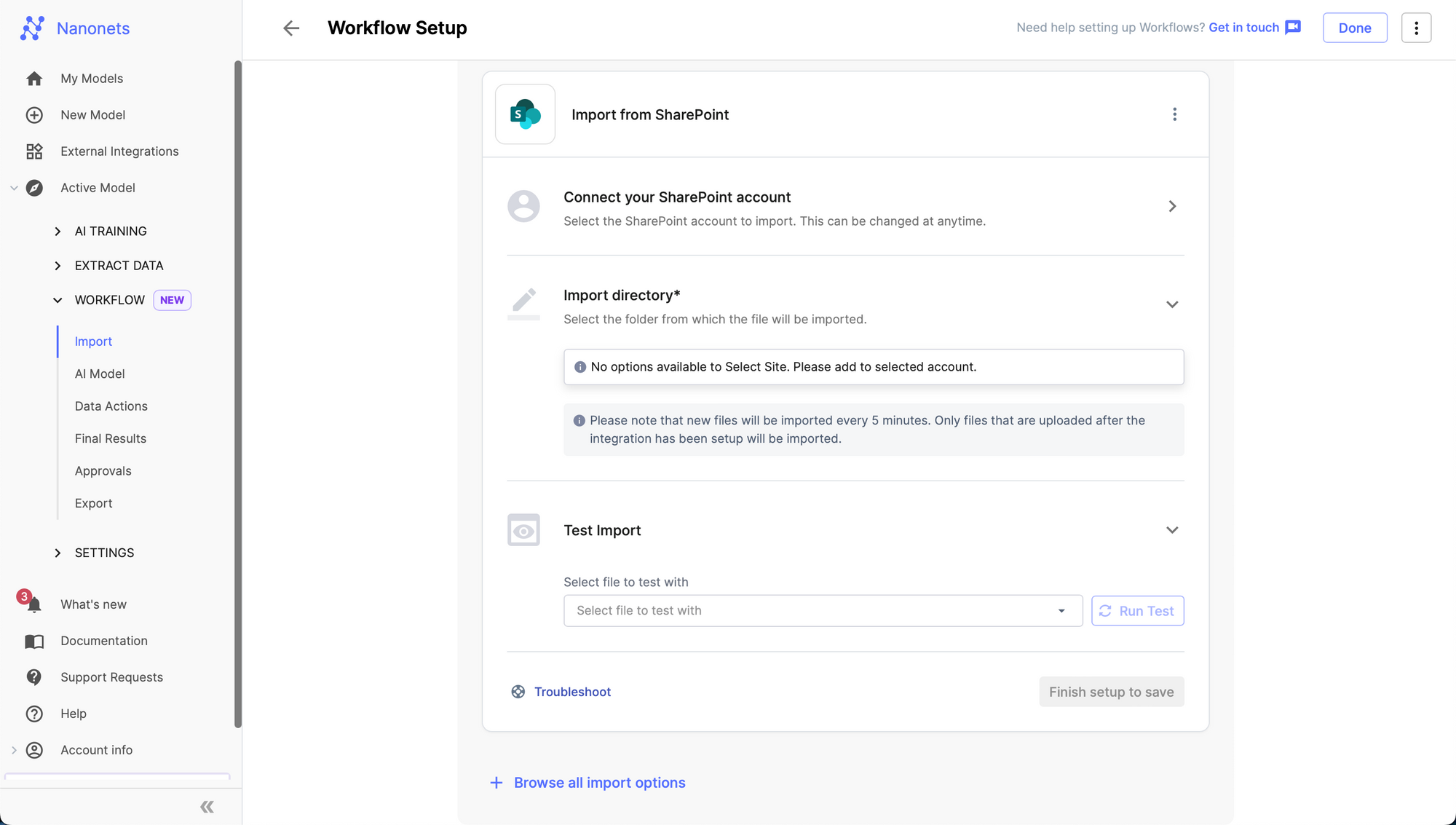
8. Click on on Add integration.
The mixing shall be added to your SharePoint account. Primarily based on the folder you chose, all new and incoming recordsdata in that folder shall be imported into Nanonets and shall be processed by your mannequin which can extract structured knowledge from it. You can even prolong the workflow by including postprocessing, validation / approval guidelines, exports to software program / database of your alternative.
Nanonets’ SharePoint Integration for Automated Doc Workflows
In conclusion, the Nanonets’ SharePoint integration is a neat technique to arrange automated doc workflows. The mixing enhances doc administration by automating classification, extraction, and routing of information, thereby eliminating handbook errors and boosting productiveness. It presents unequalled compatibility with SharePoint’s intensive doc administration capabilities, permitting companies to leverage superior knowledge processing inside a well-recognized platform. Moreover, the intuitive design and user-friendly interface of Nanonets imply that companies, no matter their dimension or tech-savviness, can seamlessly adapt and profit from the service. By including a layer of intelligence to the SharePoint ecosystem, Nanonets propels companies into a brand new period of effectivity and accuracy.
