
In 2016, we launched AlphaGo, the primary synthetic intelligence (AI) program to defeat people on the historical recreation of Go. Two years later, its successor – AlphaZero – realized from scratch to grasp Go, chess and shogi. Now, in a paper in the journal Nature, we describe MuZero, a major step ahead within the pursuit of general-purpose algorithms. MuZero masters Go, chess, shogi and Atari without having to be informed the principles, due to its potential to plan successful methods in unknown environments.
For a few years, researchers have sought strategies that may each study a mannequin that explains their atmosphere, and might then use that mannequin to plan the perfect plan of action. Till now, most approaches have struggled to plan successfully in domains, equivalent to Atari, the place the principles or dynamics are sometimes unknown and sophisticated.
MuZero, first launched in a preliminary paper in 2019, solves this drawback by studying a mannequin that focuses solely on a very powerful features of the atmosphere for planning. By combining this mannequin with AlphaZero’s highly effective lookahead tree search, MuZero set a brand new state-of-the-art end result on the Atari benchmark, whereas concurrently matching the efficiency of AlphaZero within the traditional planning challenges of Go, chess and shogi. In doing so, MuZero demonstrates a major leap ahead within the capabilities of reinforcement studying algorithms.

Generalising to unknown fashions
The flexibility to plan is a crucial a part of human intelligence, permitting us to unravel issues and make choices in regards to the future. For instance, if we see darkish clouds forming, we’d predict it’ll rain and resolve to take an umbrella with us earlier than we enterprise out. People study this potential shortly and might generalise to new situations, a trait we’d additionally like our algorithms to have.
Researchers have tried to sort out this main problem in AI by utilizing two primary approaches: lookahead search or model-based planning.
Programs that use lookahead search, equivalent to AlphaZero, have achieved outstanding success in traditional video games equivalent to checkers, chess and poker, however depend on being given data of their atmosphere’s dynamics, equivalent to the principles of the sport or an correct simulator. This makes it tough to use them to messy actual world issues, that are sometimes advanced and exhausting to distill into easy guidelines.
Mannequin-based methods goal to handle this challenge by studying an correct mannequin of an atmosphere’s dynamics, after which utilizing it to plan. Nevertheless, the complexity of modelling each facet of an atmosphere has meant these algorithms are unable to compete in visually wealthy domains, equivalent to Atari. Till now, the perfect outcomes on Atari are from model-free methods, equivalent to DQN, R2D2 and Agent57. Because the title suggests, model-free algorithms don’t use a realized mannequin and as a substitute estimate what’s the finest motion to take subsequent.
MuZero makes use of a unique method to beat the constraints of earlier approaches. As an alternative of making an attempt to mannequin your entire atmosphere, MuZero simply fashions features which might be vital to the agent’s decision-making course of. In any case, realizing an umbrella will preserve you dry is extra helpful to know than modelling the sample of raindrops within the air.
Particularly, MuZero fashions three parts of the atmosphere which might be important to planning:
- The worth: how good is the present place?
- The coverage: which motion is the perfect to take?
- The reward: how good was the final motion?
These are all realized utilizing a deep neural community and are all that’s wanted for MuZero to know what occurs when it takes a sure motion and to plan accordingly.



This method comes with one other main profit: MuZero can repeatedly use its realized mannequin to enhance its planning, reasonably than accumulating new information from the atmosphere. For instance, in checks on the Atari suite, this variant – generally known as MuZero Reanalyze – used the realized mannequin 90% of the time to re-plan what ought to have been finished in previous episodes.
MuZero efficiency
We selected 4 totally different domains to check MuZeros capabilities. Go, chess and shogi had been used to evaluate its efficiency on difficult planning issues, whereas we used the Atari suite as a benchmark for extra visually advanced issues. In all circumstances, MuZero set a brand new state-of-the-art for reinforcement studying algorithms, outperforming all prior algorithms on the Atari suite and matching the superhuman efficiency of AlphaZero on Go, chess and shogi.

We additionally examined how effectively MuZero can plan with its realized mannequin in additional element. We began with the traditional precision planning problem in Go, the place a single transfer can imply the distinction between successful and shedding. To substantiate the instinct that planning extra ought to result in higher outcomes, we measured how a lot stronger a completely skilled model of MuZero can turn out to be when given extra time to plan for every transfer (see left hand graph beneath). The outcomes confirmed that enjoying energy will increase by greater than 1000 Elo (a measure of a participant’s relative ability) as we improve the time per transfer from one-tenth of a second to 50 seconds. That is much like the distinction between a robust newbie participant and the strongest skilled participant.
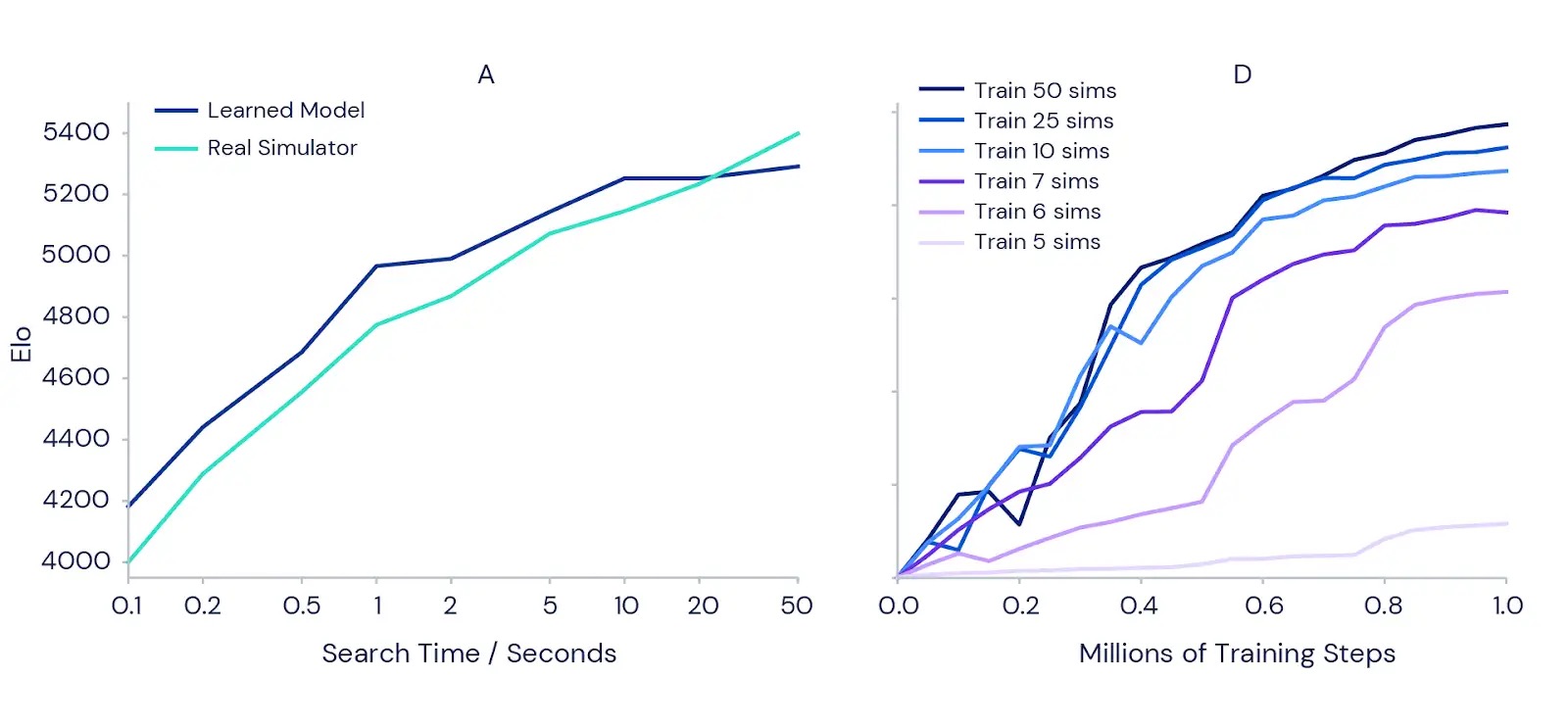
To check whether or not planning additionally brings advantages all through coaching, we ran a set of experiments on the Atari recreation Ms Pac-Man (proper hand graph above) utilizing separate skilled cases of MuZero. Each was allowed to think about a unique variety of planning simulations per transfer, starting from 5 to 50. The outcomes confirmed that rising the quantity of planning for every transfer permits MuZero to each study sooner and obtain higher ultimate efficiency.
Curiously, when MuZero was solely allowed to think about six or seven simulations per transfer – a quantity too small to cowl all of the out there actions in Ms Pac-Man – it nonetheless achieved good efficiency. This implies MuZero is ready to generalise between actions and conditions, and doesn’t have to exhaustively search all potentialities to study successfully.
New horizons
MuZero’s potential to each study a mannequin of its atmosphere and use it to efficiently plan demonstrates a major advance in reinforcement studying and the pursuit of basic function algorithms. Its predecessor, AlphaZero, has already been utilized to a spread of advanced issues in chemistry, quantum physics and past. The concepts behind MuZero’s highly effective studying and planning algorithms could pave the best way in direction of tackling new challenges in robotics, industrial methods and different messy real-world environments the place the “guidelines of the sport” aren’t recognized.
Associated hyperlinks:

