
Empowering end-users to interactively train robots to carry out novel duties is a vital functionality for his or her profitable integration into real-world functions. For instance, a person could need to train a robotic canine to carry out a brand new trick, or train a manipulator robotic set up a lunch field primarily based on person preferences. The current developments in large language models (LLMs) pre-trained on intensive web information have proven a promising path in direction of reaching this objective. Certainly, researchers have explored numerous methods of leveraging LLMs for robotics, from step-by-step planning and goal-oriented dialogue to robot-code-writing agents.
Whereas these strategies impart new modes of compositional generalization, they concentrate on utilizing language to hyperlink collectively new behaviors from an existing library of control primitives which can be both manually engineered or realized a priori. Regardless of having inner data about robotic motions, LLMs wrestle to straight output low-level robotic instructions because of the restricted availability of related coaching information. In consequence, the expression of those strategies are bottlenecked by the breadth of the out there primitives, the design of which regularly requires intensive skilled data or huge information assortment.
In “Language to Rewards for Robotic Skill Synthesis”, we suggest an method to allow customers to show robots novel actions by way of pure language enter. To take action, we leverage reward capabilities as an interface that bridges the hole between language and low-level robotic actions. We posit that reward capabilities present a really perfect interface for such duties given their richness in semantics, modularity, and interpretability. In addition they present a direct connection to low-level insurance policies by way of black-box optimization or reinforcement studying (RL). We developed a language-to-reward system that leverages LLMs to translate pure language person directions into reward-specifying code after which applies MuJoCo MPC to search out optimum low-level robotic actions that maximize the generated reward operate. We display our language-to-reward system on quite a lot of robotic management duties in simulation utilizing a quadruped robotic and a dexterous manipulator robotic. We additional validate our technique on a bodily robotic manipulator.
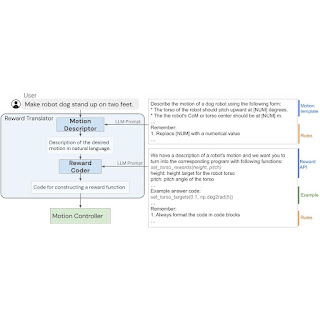
The language-to-reward system consists of two core elements: (1) a Reward Translator, and (2) a Movement Controller. The Reward Translator maps pure language instruction from customers to reward capabilities represented as python code. The Movement Controller optimizes the given reward operate utilizing receding horizon optimization to search out the optimum low-level robotic actions, comparable to the quantity of torque that ought to be utilized to every robotic motor.
 |
| LLMs can’t straight generate low-level robotic actions resulting from lack of information in pre-training dataset. We suggest to make use of reward capabilities to bridge the hole between language and low-level robotic actions, and allow novel complicated robotic motions from pure language directions. |
Reward Translator: Translating person directions to reward capabilities
The Reward Translator module was constructed with the objective of mapping pure language person directions to reward capabilities. Reward tuning is very domain-specific and requires skilled data, so it was not stunning to us after we discovered that LLMs skilled on generic language datasets are unable to straight generate a reward operate for a particular {hardware}. To deal with this, we apply the in-context learning capability of LLMs. Moreover, we cut up the Reward Translator into two sub-modules: Movement Descriptor and Reward Coder.
Movement Descriptor
First, we design a Movement Descriptor that interprets enter from a person and expands it right into a pure language description of the specified robotic movement following a predefined template. This Movement Descriptor turns doubtlessly ambiguous or obscure person directions into extra particular and descriptive robotic motions, making the reward coding activity extra secure. Furthermore, customers work together with the system by way of the movement description discipline, so this additionally supplies a extra interpretable interface for customers in comparison with straight displaying the reward operate.
To create the Movement Descriptor, we use an LLM to translate the person enter into an in depth description of the specified robotic movement. We design prompts that information the LLMs to output the movement description with the correct quantity of particulars and format. By translating a obscure person instruction right into a extra detailed description, we’re capable of extra reliably generate the reward operate with our system. This concept will also be doubtlessly utilized extra typically past robotics duties, and is related to Inner-Monologue and chain-of-thought prompting.
Reward Coder
Within the second stage, we use the identical LLM from Movement Descriptor for Reward Coder, which interprets generated movement description into the reward operate. Reward capabilities are represented utilizing python code to profit from the LLMs’ data of reward, coding, and code construction.
Ideally, we want to use an LLM to straight generate a reward operate R (s, t) that maps the robotic state s and time t right into a scalar reward worth. Nevertheless, producing the proper reward operate from scratch continues to be a difficult drawback for LLMs and correcting the errors requires the person to grasp the generated code to supply the correct suggestions. As such, we pre-define a set of reward phrases which can be generally used for the robotic of curiosity and permit LLMs to composite completely different reward phrases to formulate the ultimate reward operate. To realize this, we design a prompt that specifies the reward phrases and information the LLM to generate the proper reward operate for the duty.
 |
| The inner construction of the Reward Translator, which is tasked to map person inputs to reward capabilities. |
Movement Controller: Translating reward capabilities to robotic actions
The Movement Controller takes the reward operate generated by the Reward Translator and synthesizes a controller that maps robotic remark to low-level robotic actions. To do that, we formulate the controller synthesis drawback as a Markov decision process (MDP), which might be solved utilizing completely different methods, together with RL, offline trajectory optimization, or model predictive control (MPC). Particularly, we use an open-source implementation primarily based on the MuJoCo MPC (MJPC).
MJPC has demonstrated the interactive creation of numerous behaviors, comparable to legged locomotion, greedy, and finger-gaiting, whereas supporting a number of planning algorithms, comparable to iterative linear–quadratic–Gaussian (iLQG) and predictive sampling. Extra importantly, the frequent re-planning in MJPC empowers its robustness to uncertainties within the system and allows an interactive movement synthesis and correction system when mixed with LLMs.
Examples
Robotic canine
Within the first instance, we apply the language-to-reward system to a simulated quadruped robotic and train it to carry out varied abilities. For every ability, the person will present a concise instruction to the system, which can then synthesize the robotic movement by utilizing reward capabilities as an intermediate interface.
Dexterous manipulator
We then apply the language-to-reward system to a dexterous manipulator robotic to carry out quite a lot of manipulation duties. The dexterous manipulator has 27 levels of freedom, which may be very difficult to manage. Many of those duties require manipulation abilities past greedy, making it troublesome for pre-designed primitives to work. We additionally embody an instance the place the person can interactively instruct the robotic to position an apple inside a drawer.
Validation on actual robots
We additionally validate the language-to-reward technique utilizing a real-world manipulation robotic to carry out duties comparable to choosing up objects and opening a drawer. To carry out the optimization in Movement Controller, we use AprilTag, a fiducial marker system, and F-VLM, an open-vocabulary object detection device, to establish the place of the desk and objects being manipulated.
Conclusion
On this work, we describe a brand new paradigm for interfacing an LLM with a robotic by way of reward capabilities, powered by a low-level mannequin predictive management device, MuJoCo MPC. Utilizing reward capabilities because the interface allows LLMs to work in a semantic-rich area that performs to the strengths of LLMs, whereas making certain the expressiveness of the ensuing controller. To additional enhance the efficiency of the system, we suggest to make use of a structured movement description template to higher extract inner data about robotic motions from LLMs. We display our proposed system on two simulated robotic platforms and one actual robotic for each locomotion and manipulation duties.
Acknowledgements
We want to thank our co-authors Nimrod Gileadi, Chuyuan Fu, Sean Kirmani, Kuang-Huei Lee, Montse Gonzalez Arenas, Hao-Tien Lewis Chiang, Tom Erez, Leonard Hasenclever, Brian Ichter, Ted Xiao, Peng Xu, Andy Zeng, Tingnan Zhang, Nicolas Heess, Dorsa Sadigh, Jie Tan, and Yuval Tassa for his or her assist and help in varied features of the mission. We might additionally wish to acknowledge Ken Caluwaerts, Kristian Hartikainen, Steven Bohez, Carolina Parada, Marc Toussaint, and the larger groups at Google DeepMind for his or her suggestions and contributions.

