
Today, personally identifiable information (PII) is everywhere. PII is in emails, slack messages, videos, PDFs, and so on. It refers to any data or information that can be used to identify a specific individual. PII is sensitive in nature and includes various types of personal data, such as name, contact information, identification numbers, financial information, medical information, biometric data, date of birth, and so on.
Finding and redacting PII is essential to safeguarding privacy, ensuring data security, complying with laws and regulations, and maintaining trust with customers and stakeholders. It’s a critical component of modern data management and cybersecurity practices. But finding PII among the morass of electronic data can present challenges for an organization. These challenges arise due to the vast volume and variety of data, data fragmentation, encryption, data sharing, dynamic content, false positives and negatives, contextual understanding, legal complexities, resource constraints, evolving data, user-generated content, and adaptive threats. However, failure to accurately detect and redact PII can lead to severe consequences for organizations. Consequences might encompass legal penalties, lawsuits, reputation damage, data breach costs, regulatory probes, operational disruption, trust erosion, and sanctions.
In the legal system, discovery is the legal process governing the right to obtain and the obligation to produce non-privileged matter relevant to any party’s claims or defenses in litigation. Electronic discovery also known as eDiscovery is the electronic aspect of identifying, collecting, and producing electronically stored information (ESI) in response to a request for production in a lawsuit or investigation. In the legal domain, it’s often required to identify, collect, and produce ESI during a lawsuit or investigation. If organizations are dealing with eDiscovery for litigations on subpoena responses, they’re probably concerned about accidentally sharing PII. Many organizations including government agencies, school districts, and legal professionals face the challenge of detecting and redacting PII accurately at scale. Especially if they’re part of a government group, redacting PII through the Freedom of Information Act and Digital Services Act is crucial for protecting individual privacy, ensuring compliance with data protection laws, preventing identity theft, and maintaining trust and transparency in government and digital services. It strikes a balance between transparency and privacy while mitigating legal and security risks.
Organizations can search for PII using methods such as keyword searches, pattern matching, data loss prevention tools, machine learning (ML), metadata analysis, data classification software, optical character recognition (OCR), document fingerprinting, and encryption.
Now a part of Reveal’s AI-powered eDiscovery platform, Logikcull is a self-service solution that allows legal professionals to process, review, tag, and produce electronic documents as part of a lawsuit or investigation. This unique offering helps attorneys discover valuable information related to the matter in hand while reducing costs, speeding up resolutions, and mitigating risks.
In this post, Reveal experts showcase how they used Amazon Comprehend in their document processing pipeline to detect and redact individual pieces of PII. Amazon Comprehend is a fully managed and continuously trained natural language processing (NLP) service that can extract insight about the content of a document or text. You can use Amazon Comprehend ML capabilities to detect and redact PII in customer emails, support tickets, product reviews, social media, and more.
Overview of solution
The overarching goal for the engineering team is to detect and redact PII from millions of legal documents for their customers. Using Reveal’s Logikcull solution, the engineering team implemented two processes, namely first pass PII detection and second pass PII detection and redaction. This two pass solution was made possible by using the ContainsPiiEntities and DetectPiiEntities APIs.
First pass PII detection
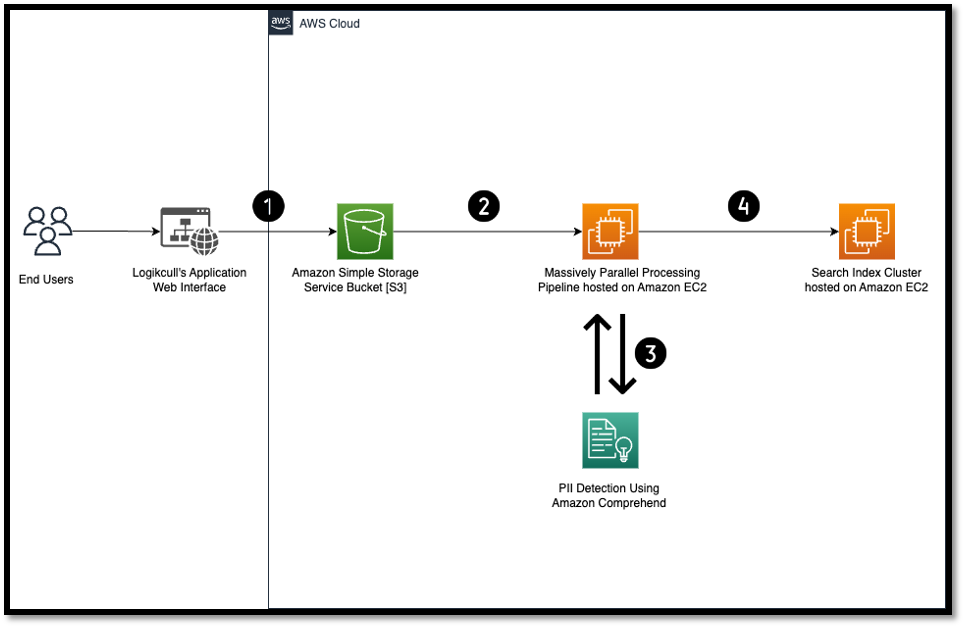
The goal of first pass PII detection is to find the documents that might contain PII.
- Users upload the files on which they would like to perform PII detection and redaction through Logikcull’s public website into a project folder. These files can be in the form of office documents, .pdf files, emails, or a .zip file containing all the supported file types.
- Logikcull stores these project folders securely inside an Amazon Simple Storage Service (Amazon S3) bucket. The files then pass through Logikcull’s massively parallel processing pipeline hosted on Amazon Elastic Compute Cloud (Amazon EC2), which processes the files, extracts the metadata, and generates artifacts in text format for data review. Logikcull’s processing pipeline supports text extraction for a wide variety of forms and files, including audio and video files.
- After the files are available in text format, Logikcull passes the input text along with the language model, which is English, through Amazon Comprehend by making the ContainsPiiEntities API call. The processing pipeline servers hosted on Amazon EC2 make the Amazon Comprehend
ContainsPiiEntitiesAPI call by passing the request parameters as text and language code. TheContainsPiiEntitiesAPI call analyzes input text for the presence of PII and returns the labels of identified PII entity types, such as name, address, bank account number, or phone number. The API response also includes a confidence score which indicates the level of confidence that Amazon Comprehend has assigned to the detection accuracy. The confidence score has a value between 0 and 1, with 1 signifying 100 percent confidence. Logikcull uses this confidence score to assign the tag PII Detected to the documents. Logikcull only assigns this tag to documents that have a confidence score of over 0.75. - PII Detected tagged documents are fed into Logikcull’s search index cluster for their users to quickly identify documents that contain PII entities.
Second pass PII detection and redaction
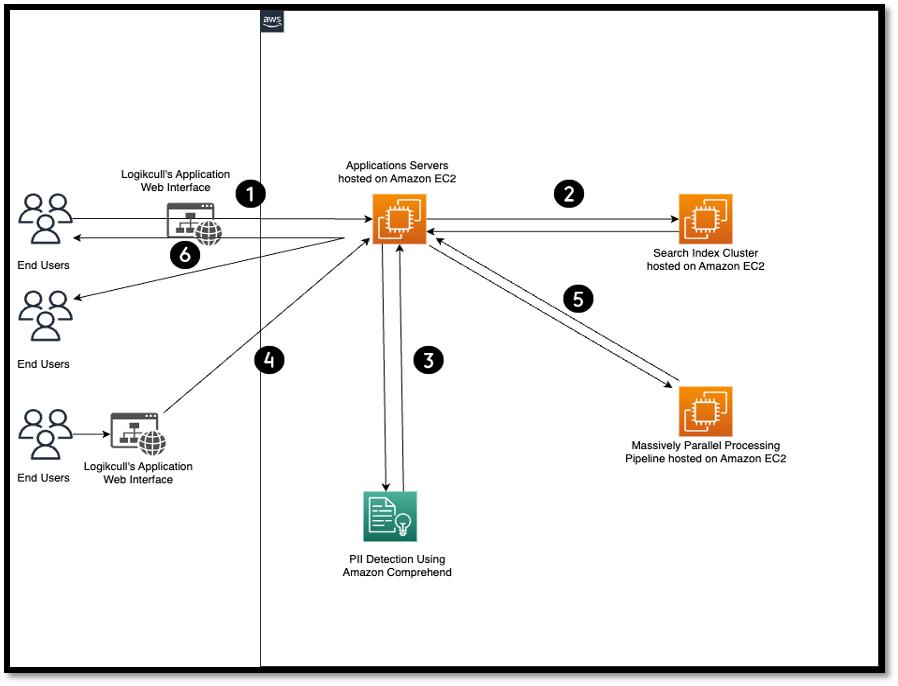
The first pass PII detection process narrows down the scope of the dataset by identifying which documents contain PII information. This speeds up the PII detection process and also reduces the overall cost. The goal of the second pass PII detection is to identify the individual instances of PII and redact them from the tagged documents in the first pass.
- Users search for documents through the Logikcull’s website that contains PII using Logikcull’s advanced search filters feature.
- The request is handled by Logikcull’s application servers hosted on Amazon EC2 and the servers communicates with the search index cluster to find the documents.
- The Logikcull applications servers are able to identify the individual instances of PII by making the DetectPiiEntities API call. The servers make the API call by passing the text and language of input documents. The
DetectPiiEntitiesAPI action inspects the input text for entities that contain PII. For each entity, the response provides the entity type, where the entity text begins and ends, and the level of confidence that Amazon Comprehend has in its detection. - The users then select the specific entities that they want to redact using Logikcull’s web interface. The applications server sends these requests to Logikcull’s processing pipeline. The following is a screenshot of a PDF that was uploaded to Logikcull’s application. From the below screenshot, you can see that different PII entities such as name, address, phone number, email address, and so on, have been highlighted.

- The PII redaction is safely applied inside the Logikcull’s processing pipeline using custom business logic. From the screenshot that follows, you can see that users can select either specific PII entity types or all PII entity types that they want to redact and then, with a click of a single button, redact all the PII information.

Results
Logikcull, a Reveal technology, is currently processing over 20 million documents each week and was able to narrow down the scope of detection using the ContainsPiiEntities API and display individual instances of PII entities to their customers by using the DetectPiiEntities API.
“With Amazon Comprehend, Logikcull has been able to rapidly deploy powerful NLP capabilities in a fraction of the time a custom-built solution would have required.”
– Steve Newhouse, VP of Product for Logikcull.
Conclusion
Amazon Comprehend allows Reveal’s Logikcull technology to run PII detection at large scale for relatively low cost using Amazon Comprehend. The ContainsPiiEntities API is used to do an initial scan of millions of documents. The DetectPiiEntities API is used to run a detailed analysis of thousands of documents and identify individual pieces of PII in their documents.
Take a look at all the Amazon Comprehend features. Give the features a try and send us feedback either through the AWS forum for Amazon Comprehend or through your usual AWS support contacts.
About the Authors
 Aman Tiwari is a General Solutions Architect working with Worldwide Commercial Sales at AWS. He works with customers in the Digital Native Business segment and helps them design innovative, resilient, and cost-effective solutions using AWS services. He holds a master’s degree in Telecommunications Networks from Northeastern University. Outside of work, he enjoys playing lawn tennis and reading books.
Aman Tiwari is a General Solutions Architect working with Worldwide Commercial Sales at AWS. He works with customers in the Digital Native Business segment and helps them design innovative, resilient, and cost-effective solutions using AWS services. He holds a master’s degree in Telecommunications Networks from Northeastern University. Outside of work, he enjoys playing lawn tennis and reading books.
 Jeff Newburn is a Senior Software Engineering Manager leading the Data Engineering team at Logikcull – A Reveal Technology. He oversees the company’s data initiatives, including data warehouses, visualizations, analytics, and machine learning. With experience spanning development and management in areas from ride sharing to data systems, he enjoys leading teams of brilliant engineers to exciting products.
Jeff Newburn is a Senior Software Engineering Manager leading the Data Engineering team at Logikcull – A Reveal Technology. He oversees the company’s data initiatives, including data warehouses, visualizations, analytics, and machine learning. With experience spanning development and management in areas from ride sharing to data systems, he enjoys leading teams of brilliant engineers to exciting products.
 Søren Blond Daugaard is a Staff Engineer in the Data Engineering team at Logikcull – A Reveal Technology. He implements highly scalable AI and ML solutions into the Logikcull product, enabling our customers to do their work more efficiently and with higher precision. His expertise spans data pipelines, web-based systems, and machine learning systems.
Søren Blond Daugaard is a Staff Engineer in the Data Engineering team at Logikcull – A Reveal Technology. He implements highly scalable AI and ML solutions into the Logikcull product, enabling our customers to do their work more efficiently and with higher precision. His expertise spans data pipelines, web-based systems, and machine learning systems.
 Kevin Lufkin is a Senior Software Engineer on the Search Engineering team at Logikcull – A Reveal Technology, where he focuses on developing customer facing and search-related features. His extensive expertise in UI/UX is complemented by a background in full-stack web development, with a strong focus on bringing product visions to life.
Kevin Lufkin is a Senior Software Engineer on the Search Engineering team at Logikcull – A Reveal Technology, where he focuses on developing customer facing and search-related features. His extensive expertise in UI/UX is complemented by a background in full-stack web development, with a strong focus on bringing product visions to life.

