
This submit is co-written with Aruna Abeyakoon and Denisse Colin from Mild and Surprise (L&W).
Headquartered in Las Vegas, Light & Wonder, Inc. is the main cross-platform world recreation firm that gives playing services and products. Working with AWS, Mild & Surprise lately developed an industry-first safe answer, Mild & Surprise Join (LnW Join), to stream telemetry and machine well being information from roughly half one million digital gaming machines distributed throughout its on line casino buyer base globally when LnW Join reaches its full potential. Over 500 machine occasions are monitored in near-real time to present a full image of machine circumstances and their working environments. Using information streamed by LnW Join, L&W goals to create higher gaming expertise for his or her end-users in addition to convey extra worth to their on line casino clients.
Mild & Surprise teamed up with the Amazon ML Solutions Lab to make use of occasions information streamed from LnW Connect with allow machine studying (ML)-powered predictive upkeep for slot machines. Predictive upkeep is a standard ML use case for companies with bodily tools or equipment belongings. With predictive upkeep, L&W can get superior warning of machine breakdowns and proactively dispatch a service group to examine the problem. It will cut back machine downtime and keep away from vital income loss for casinos. With no distant diagnostic system in place, difficulty decision by the Mild & Surprise service group on the on line casino flooring could be pricey and inefficient, whereas severely degrading the shopper gaming expertise.
The character of the challenge is very exploratory—that is the primary try at predictive upkeep within the gaming {industry}. The Amazon ML Options Lab and L&W group launched into an end-to-end journey from formulating the ML downside and defining the analysis metrics, to delivering a high-quality answer. The ultimate ML mannequin combines CNN and Transformer, that are the state-of-the-art neural community architectures for modeling sequential machine log information. The submit presents an in depth description of this journey, and we hope you’ll take pleasure in it as a lot as we do!
On this submit, we talk about the next:
- How we formulated the predictive upkeep downside as an ML downside with a set of applicable metrics for analysis
- How we ready information for coaching and testing
- Information preprocessing and have engineering methods we employed to acquire performant fashions
- Performing a hyperparameter tuning step with Amazon SageMaker Automatic Model Tuning
- Comparisons between the baseline mannequin and the ultimate CNN+Transformer mannequin
- Extra methods we used to enhance mannequin efficiency, similar to ensembling
Background
On this part, we talk about the problems that necessitated this answer.
Dataset
Slot machine environments are extremely regulated and are deployed in an air-gapped setting. In LnW Join, an encryption course of was designed to supply a safe and dependable mechanism for the info to be introduced into an AWS information lake for predictive modeling. The aggregated recordsdata are encrypted and the decryption key’s solely out there in AWS Key Management Service (AWS KMS). A cellular-based personal community into AWS is about up by which the recordsdata have been uploaded into Amazon Simple Storage Service (Amazon S3).
LnW Join streams a variety of machine occasions, similar to begin of recreation, finish of recreation, and extra. The system collects over 500 several types of occasions. As proven within the following
, every occasion is recorded together with a timestamp of when it occurred and the ID of the machine recording the occasion. LnW Join additionally information when a machine enters a non-playable state, and it is going to be marked as a machine failure or breakdown if it doesn’t recuperate to a playable state inside a sufficiently quick time span.
| Machine ID | Occasion Sort ID | Timestamp |
|---|---|---|
| 0 | E1 | 2022-01-01 00:17:24 |
| 0 | E3 | 2022-01-01 00:17:29 |
| 1000 | E4 | 2022-01-01 00:17:33 |
| 114 | E234 | 2022-01-01 00:17:34 |
| 222 | E100 | 2022-01-01 00:17:37 |
Along with dynamic machine occasions, static metadata about every machine can also be out there. This contains info similar to machine distinctive identifier, cupboard sort, location, working system, software program model, recreation theme, and extra, as proven within the following desk. (All of the names within the desk are anonymized to guard buyer info.)
| Machine ID | Cupboard Sort | OS | Location | Recreation Theme |
|---|---|---|---|---|
| 276 | A | OS_Ver0 | AA Resort & On line casino | StormMaiden |
| 167 | B | OS_Ver1 | BB On line casino, Resort & Spa | UHMLIndia |
| 13 | C | OS_Ver0 | CC On line casino & Resort | TerrificTiger |
| 307 | D | OS_Ver0 | DD On line casino Resort | NeptunesRealm |
| 70 | E | OS_Ver0 | EE Resort & On line casino | RLPMealTicket |
Drawback definition
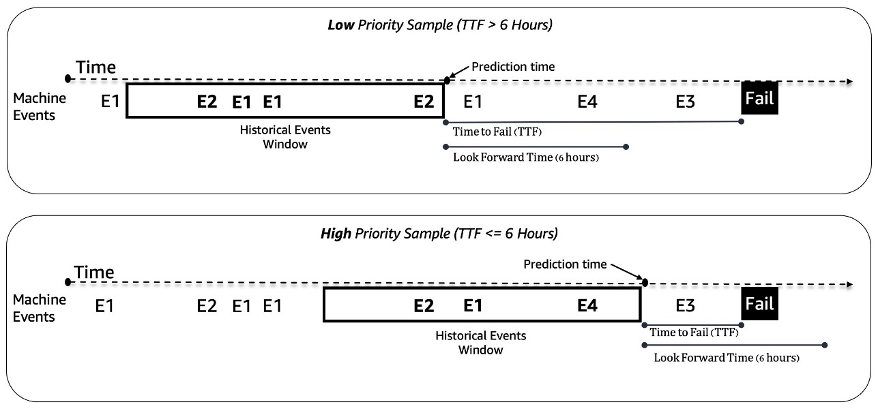
We deal with the predictive upkeep downside for slot machines as a binary classification downside. The ML mannequin takes within the historic sequence of machine occasions and different metadata and predicts whether or not a machine will encounter a failure in a 6-hour future time window. If a machine will break down inside 6 hours, it’s deemed a high-priority machine for upkeep. In any other case, it’s low precedence. The next determine offers examples of low-priority (high) and high-priority (backside) samples. We use a fixed-length look-back time window to gather historic machine occasion information for prediction. Experiments present that longer look-back time home windows enhance mannequin efficiency considerably (extra particulars later on this submit).
Modeling challenges
We confronted a few challenges fixing this downside:
- We have now an enormous quantity occasion logs that include round 50 million occasions a month (from roughly 1,000 recreation samples). Cautious optimization is required within the information extraction and preprocessing stage.
- Occasion sequence modeling was difficult as a result of extraordinarily uneven distribution of occasions over time. A 3-hour window can include wherever from tens to 1000’s of occasions.
- Machines are in an excellent state more often than not and the high-priority upkeep is a uncommon class, which launched a category imbalance difficulty.
- New machines are added constantly to the system, so we had to verify our mannequin can deal with prediction on new machines which have by no means been seen in coaching.
Information preprocessing and have engineering
On this part, we talk about our strategies for information preparation and have engineering.
Characteristic engineering
Slot machine feeds are streams of unequally spaced time collection occasions; for instance, the variety of occasions in a 3-hour window can vary from tens to 1000’s. To deal with this imbalance, we used occasion frequencies as an alternative of the uncooked sequence information. An easy strategy is aggregating the occasion frequency for all the look-back window and feeding it into the mannequin. Nevertheless, when utilizing this illustration, the temporal info is misplaced, and the order of occasions just isn’t preserved. We as an alternative used temporal binning by dividing the time window into N equal sub-windows and calculating the occasion frequencies in every. The ultimate options of a time window are the concatenation of all its sub-window options. Rising the variety of bins preserves extra temporal info. The next determine illustrates temporal binning on a pattern window.

First, the pattern time window is break up into two equal sub-windows (bins); we used solely two bins right here for simplicity for illustration. Then, the counts of the occasions E1, E2, E3, and E4 are calculated in every bin. Lastly, they’re concatenated and used as options.
Together with the occasion frequency-based options, we used machine-specific options like software program model, cupboard sort, recreation theme, and recreation model. Moreover, we added options associated to the timestamps to seize the seasonality, similar to hour of the day and day of the week.
Information preparation
To extract information effectively for coaching and testing, we make the most of Amazon Athena and the AWS Glue Information Catalog. The occasions information is saved in Amazon S3 in Parquet format and partitioned based on day/month/hour. This facilitates environment friendly extraction of information samples inside a specified time window. We use information from all machines within the newest month for testing and the remainder of the info for coaching, which helps keep away from potential information leakage.
ML methodology and mannequin coaching
On this part, we talk about our baseline mannequin with AutoGluon and the way we constructed a custom-made neural community with SageMaker automated mannequin tuning.
Constructing a baseline mannequin with AutoGluon
With any ML use case, it’s essential to ascertain a baseline mannequin for use for comparability and iteration. We used AutoGluon to discover a number of basic ML algorithms. AutoGluon is easy-to-use AutoML instrument that makes use of automated information processing, hyperparameter tuning, and mannequin ensemble. The very best baseline was achieved with a weighted ensemble of gradient boosted resolution tree fashions. The convenience of use of AutoGluon helped us within the discovery stage to navigate shortly and effectively by a variety of attainable information and ML modeling instructions.
Constructing and tuning a custom-made neural community mannequin with SageMaker automated mannequin tuning
After experimenting with totally different neural networks architectures, we constructed a custom-made deep studying mannequin for predictive upkeep. Our mannequin surpassed the AutoGluon baseline mannequin by 121% in recall at 80% precision. The ultimate mannequin ingests historic machine occasion sequence information, time options similar to hour of the day, and static machine metadata. We make the most of SageMaker automatic model tuning jobs to seek for the perfect hyperparameters and mannequin architectures.
The next determine reveals the mannequin structure. We first normalize the binned occasion sequence information by common frequencies of every occasion within the coaching set to take away the overwhelming impact of high-frequency occasions (begin of recreation, finish of recreation, and so forth). The embeddings for particular person occasions are learnable, whereas the temporal characteristic embeddings (day of the week, hour of the day) are extracted utilizing the bundle GluonTS. Then we concatenate the occasion sequence information with the temporal characteristic embeddings because the enter to the mannequin. The mannequin consists of the next layers:
- Convolutional layers (CNN) – Every CNN layer consists of two 1-dimensional convolutional operations with residual connections. The output of every CNN layer has the identical sequence size because the enter to permit for straightforward stacking with different modules. The full variety of CNN layers is a tunable hyperparameter.
- Transformer encoder layers (TRANS) – The output of the CNN layers is fed along with the positional encoding to a multi-head self-attention construction. We use TRANS to immediately seize temporal dependencies as an alternative of utilizing recurrent neural networks. Right here, binning of the uncooked sequence information (decreasing size from 1000’s to a whole bunch) helps alleviate the GPU reminiscence bottlenecks, whereas maintaining the chronological info to a tunable extent (the variety of the bins is a tunable hyperparameter).
- Aggregation layers (AGG) – The ultimate layer combines the metadata info (recreation theme sort, cupboard sort, places) to provide the precedence stage chance prediction. It consists of a number of pooling layers and totally related layers for incremental dimension discount. The multi-hot embeddings of metadata are additionally learnable, and don’t undergo CNN and TRANS layers as a result of they don’t include sequential info.

We use the cross-entropy loss with class weights as tunable hyperparameters to regulate for the category imbalance difficulty. As well as, the numbers of CNN and TRANS layers are essential hyperparameters with the attainable values of 0, which implies particular layers could not at all times exist within the mannequin structure. This manner, we’ve a unified framework the place the mannequin architectures are searched together with different normal hyperparameters.
We make the most of SageMaker automated mannequin tuning, also called hyperparameter optimization (HPO), to effectively discover mannequin variations and the big search house of all hyperparameters. Computerized mannequin tuning receives the custom-made algorithm, coaching information, and hyperparameter search house configurations, and searches for finest hyperparameters utilizing totally different methods similar to Bayesian, Hyperband, and extra with a number of GPU situations in parallel. After evaluating on a hold-out validation set, we obtained the perfect mannequin structure with two layers of CNN, one layer of TRANS with 4 heads, and an AGG layer.
We used the next hyperparameter ranges to seek for the perfect mannequin structure:
To additional enhance mannequin accuracy and cut back mannequin variance, we skilled the mannequin with a number of unbiased random weight initializations, and aggregated the outcome with imply values as the ultimate chance prediction. There’s a trade-off between extra computing assets and higher mannequin efficiency, and we noticed that 5–10 must be an affordable quantity within the present use case (outcomes proven later on this submit).
Mannequin efficiency outcomes
On this part, we current the mannequin efficiency analysis metrics and outcomes.
Analysis metrics
Precision is essential for this predictive upkeep use case. Low precision means reporting extra false upkeep calls, which drives prices up by pointless upkeep. As a result of common precision (AP) doesn’t totally align with the excessive precision goal, we launched a brand new metric named common recall at excessive precisions (ARHP). ARHP is the same as the typical of remembers at 60%, 70%, and 80% precision factors. We additionally used precision at high Ok% (Ok=1, 10), AUPR, and AUROC as extra metrics.
Outcomes
The next desk summarizes the outcomes utilizing the baseline and the custom-made neural community fashions, with 7/1/2022 because the practice/take a look at break up level. Experiments present that growing the window size and pattern information dimension each enhance the mannequin efficiency, as a result of they include extra historic info to assist with the prediction. Whatever the information settings, the neural community mannequin outperforms AutoGluon in all metrics. For instance, recall on the fastened 80% precision is elevated by 121%, which lets you shortly establish extra malfunctioned machines if utilizing the neural community mannequin.
| Mannequin | Window size/Information dimension | AUROC | AUPR | ARHP | [email protected] | [email protected] | [email protected] | Prec@top1% | Prec@top10% |
|---|---|---|---|---|---|---|---|---|---|
| AutoGluon baseline | 12H/500k | 66.5 | 36.1 | 9.5 | 12.7 | 9.3 | 6.5 | 85 | 42 |
| Neural Community | 12H/500k | 74.7 | 46.5 | 18.5 | 25 | 18.1 | 12.3 | 89 | 55 |
| AutoGluon baseline | 48H/1mm | 70.2 | 44.9 | 18.8 | 26.5 | 18.4 | 11.5 | 92 | 55 |
| Neural Community | 48H/1mm | 75.2 | 53.1 | 32.4 | 39.3 | 32.6 | 25.4 | 94 | 65 |
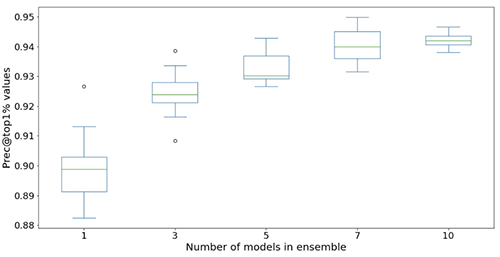
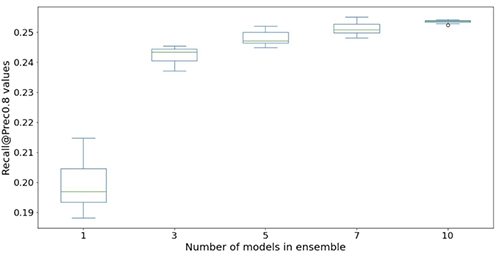
The next figures illustrate the impact of utilizing ensembles to spice up the neural community mannequin efficiency. All of the analysis metrics proven on the x-axis are improved, with greater imply (extra correct) and decrease variance (extra secure). Every box-plot is from 12 repeated experiments, from no ensembles to 10 fashions in ensembles (x-axis). Related traits persist in all metrics apart from the Prec@top1% and Recall@Prec80% proven.
After factoring within the computational price, we observe that utilizing 5–10 fashions in ensembles is appropriate for Mild & Surprise datasets.
Conclusion
Our collaboration has resulted within the creation of a groundbreaking predictive upkeep answer for the gaming {industry}, in addition to a reusable framework that could possibly be utilized in a wide range of predictive upkeep situations. The adoption of AWS applied sciences similar to SageMaker automated mannequin tuning facilitates Mild & Surprise to navigate new alternatives utilizing near-real-time information streams. Mild & Surprise is beginning the deployment on AWS.
If you want assist accelerating using ML in your services and products, please contact the Amazon ML Solutions Lab program.
Concerning the authors
 Aruna Abeyakoon is the Senior Director of Information Science & Analytics at Mild & Surprise Land-based Gaming Division. Aruna leads the industry-first Mild & Surprise Join initiative and helps each on line casino companions and inner stakeholders with shopper habits and product insights to make higher video games, optimize product choices, handle belongings, and well being monitoring & predictive upkeep.
Aruna Abeyakoon is the Senior Director of Information Science & Analytics at Mild & Surprise Land-based Gaming Division. Aruna leads the industry-first Mild & Surprise Join initiative and helps each on line casino companions and inner stakeholders with shopper habits and product insights to make higher video games, optimize product choices, handle belongings, and well being monitoring & predictive upkeep.
 Denisse Colin is a Senior Information Science Supervisor at Mild & Surprise, a number one cross-platform world recreation firm. She is a member of the Gaming Information & Analytics group serving to develop revolutionary options to enhance product efficiency and clients’ experiences by Mild & Surprise Join.
Denisse Colin is a Senior Information Science Supervisor at Mild & Surprise, a number one cross-platform world recreation firm. She is a member of the Gaming Information & Analytics group serving to develop revolutionary options to enhance product efficiency and clients’ experiences by Mild & Surprise Join.
 Tesfagabir Meharizghi is a Information Scientist on the Amazon ML Options Lab the place he helps AWS clients throughout numerous industries similar to gaming, healthcare and life sciences, manufacturing, automotive, and sports activities and media, speed up their use of machine studying and AWS cloud companies to unravel their enterprise challenges.
Tesfagabir Meharizghi is a Information Scientist on the Amazon ML Options Lab the place he helps AWS clients throughout numerous industries similar to gaming, healthcare and life sciences, manufacturing, automotive, and sports activities and media, speed up their use of machine studying and AWS cloud companies to unravel their enterprise challenges.
 Mohamad Aljazaery is an utilized scientist at Amazon ML Options Lab. He helps AWS clients establish and construct ML options to deal with their enterprise challenges in areas similar to logistics, personalization and suggestions, pc imaginative and prescient, fraud prevention, forecasting and provide chain optimization.
Mohamad Aljazaery is an utilized scientist at Amazon ML Options Lab. He helps AWS clients establish and construct ML options to deal with their enterprise challenges in areas similar to logistics, personalization and suggestions, pc imaginative and prescient, fraud prevention, forecasting and provide chain optimization.
 Yawei Wang is an Utilized Scientist on the Amazon ML Answer Lab. He helps AWS enterprise companions establish and construct ML options to deal with their group’s enterprise challenges in a real-world state of affairs.
Yawei Wang is an Utilized Scientist on the Amazon ML Answer Lab. He helps AWS enterprise companions establish and construct ML options to deal with their group’s enterprise challenges in a real-world state of affairs.
 Yun Zhou is an Utilized Scientist on the Amazon ML Options Lab, the place he helps with analysis and growth to make sure the success of AWS clients. He works on pioneering options for numerous industries utilizing statistical modeling and machine studying methods. His curiosity contains generative fashions and sequential information modeling.
Yun Zhou is an Utilized Scientist on the Amazon ML Options Lab, the place he helps with analysis and growth to make sure the success of AWS clients. He works on pioneering options for numerous industries utilizing statistical modeling and machine studying methods. His curiosity contains generative fashions and sequential information modeling.
 Panpan Xu is a Utilized Science Supervisor with the Amazon ML Options Lab at AWS. She is engaged on analysis and growth of Machine Studying algorithms for high-impact buyer functions in a wide range of industrial verticals to speed up their AI and cloud adoption. Her analysis curiosity contains mannequin interpretability, causal evaluation, human-in-the-loop AI and interactive information visualization.
Panpan Xu is a Utilized Science Supervisor with the Amazon ML Options Lab at AWS. She is engaged on analysis and growth of Machine Studying algorithms for high-impact buyer functions in a wide range of industrial verticals to speed up their AI and cloud adoption. Her analysis curiosity contains mannequin interpretability, causal evaluation, human-in-the-loop AI and interactive information visualization.
 Raj Salvaji leads Options Structure within the Hospitality section at AWS. He works with hospitality clients by offering strategic steerage, technical experience to create options to advanced enterprise challenges. He attracts on 25 years of expertise in a number of engineering roles throughout Hospitality, Finance and Automotive industries.
Raj Salvaji leads Options Structure within the Hospitality section at AWS. He works with hospitality clients by offering strategic steerage, technical experience to create options to advanced enterprise challenges. He attracts on 25 years of expertise in a number of engineering roles throughout Hospitality, Finance and Automotive industries.
 Shane Rai is a Principal ML Strategist with the Amazon ML Options Lab at AWS. He works with clients throughout a various spectrum of industries to unravel their most urgent and revolutionary enterprise wants utilizing AWS’s breadth of cloud-based AI/ML companies.
Shane Rai is a Principal ML Strategist with the Amazon ML Options Lab at AWS. He works with clients throughout a various spectrum of industries to unravel their most urgent and revolutionary enterprise wants utilizing AWS’s breadth of cloud-based AI/ML companies.

