
This can be a visitor put up by Dr. Naoki Okada, Lead Information Scientist at BrainPad Inc.
Based in 2004, BrainPad Inc. is a pioneering companion within the discipline of information utilization, serving to corporations create enterprise and enhance their administration by way of the usage of knowledge. So far, BrainPad has helped greater than 1,300 corporations, primarily business leaders. BrainPad has the benefit of offering a one-stop service from formulating a knowledge utilization technique to proof of idea and implementation. BrainPad’s distinctive model is to work along with shoppers to unravel issues on the bottom, corresponding to knowledge that isn’t being collected as a consequence of a siloed organizational construction or knowledge that exists however isn’t organized.
This put up discusses the best way to construction inner information sharing utilizing Amazon Kendra and AWS Lambda and the way Amazon Kendra solves the obstacles round information sharing many corporations face. We summarize BrainPad’s efforts in 4 key areas:
- What are the information sharing issues that many corporations face?
- Why did we select Amazon Kendra?
- How did we implement the information sharing system?
- Even when a instrument is beneficial, it’s meaningless if it isn’t used. How did we overcome the barrier to adoption?
Information sharing issues that many corporations face
Many corporations obtain their outcomes by dividing their work into completely different areas. Every of those actions generates new concepts on daily basis. This information is gathered on a person foundation. If this data could be shared amongst individuals and organizations, synergies in associated work could be created, and the effectivity and high quality of labor will enhance dramatically. That is the facility of data sharing.
Nevertheless, there are lots of frequent boundaries to information sharing:
- Few persons are proactively concerned, and the method can’t be sustained for lengthy as a consequence of busy schedules.
- Information is scattered throughout a number of media, corresponding to inner wikis and PDFs, making it troublesome to search out the knowledge you want.
- Nobody enters information into the information consolidation system. The system won’t be broadly used due to its poor searchability.
Our firm confronted an analogous state of affairs. The basic drawback with information sharing is that though most staff have a powerful must get hold of information, they’ve little motivation to share their very own information at a price. Altering worker conduct for the only function of data sharing is just not straightforward.
As well as, every worker or division has its personal most well-liked technique of accumulating information, and attempting to pressure unification received’t result in motivation or efficiency in information sharing. This can be a headache for administration, who needs to consolidate information, whereas these within the discipline wish to have information in a decentralized manner.
At our firm, Amazon Kendra is the cloud service that has solved these issues.
Why we selected Amazon Kendra
Amazon Kendra is a cloud service that permits us to seek for inner data from a standard interface. In different phrases, it’s a search engine that focuses on inner data. On this part, we focus on the three key the explanation why we selected Amazon Kendra.
Straightforward aggregation of data
As talked about within the earlier part, information, even when it exists, tends to be scattered throughout a number of media. In our case, it was scattered throughout our inner wiki and numerous doc recordsdata. Amazon Kendra supplies highly effective connectors for this example. We will simply import paperwork from a wide range of media, together with groupware, wikis, Microsoft PowerPoint recordsdata, PDFs, and extra, with none problem.
Which means staff don’t have to alter the best way they retailer information with a view to share it. Though information aggregation could be achieved briefly, it’s very pricey to keep up. The flexibility to automate this was a really fascinating issue for us.
Nice searchability
There are loads of groupware and wikis on the market that excel at data enter. Nevertheless, they typically have weaknesses in data output (searchability). That is very true for Japanese search. For instance, in English, word-level matching supplies an affordable degree of searchability. In Japanese, nonetheless, phrase extraction is tougher, and there are instances the place matching is completed by separating phrases by an acceptable variety of characters. If a seek for “Tokyo-to (東京都)” is separated by two characters, “Tokyo (東京)” and “Kyoto (京都),” will probably be troublesome to search out the information you’re in search of.
Amazon Kendra presents nice searchability through machine learning. Along with conventional key phrase searches corresponding to “know-how developments,” pure language searches corresponding to “I would like data on new know-how initiatives” can enormously improve the person expertise. The flexibility to go looking appropriately for collected data is the second purpose we selected Amazon Kendra.
Low price of possession
IT instruments focusing on information aggregation and retrieval are referred to as enterprise search techniques. One drawback with implementing these techniques is the fee. For a company with a number of hundred staff, working prices can exceed 10 million yen per 12 months. This isn’t an affordable strategy to begin a information sharing initiative.
Amazon Kendra is obtainable at a much lower cost than most enterprise search techniques. As talked about earlier, information sharing initiatives aren’t straightforward to implement. We needed to start out small, and Amazon Kendra’s low price of possession was a key think about our determination.
As well as, Amazon Kendra’s ease of implementation and suppleness are additionally nice benefits for us. The subsequent part summarizes an instance of our implementation.
How we applied the information sharing system
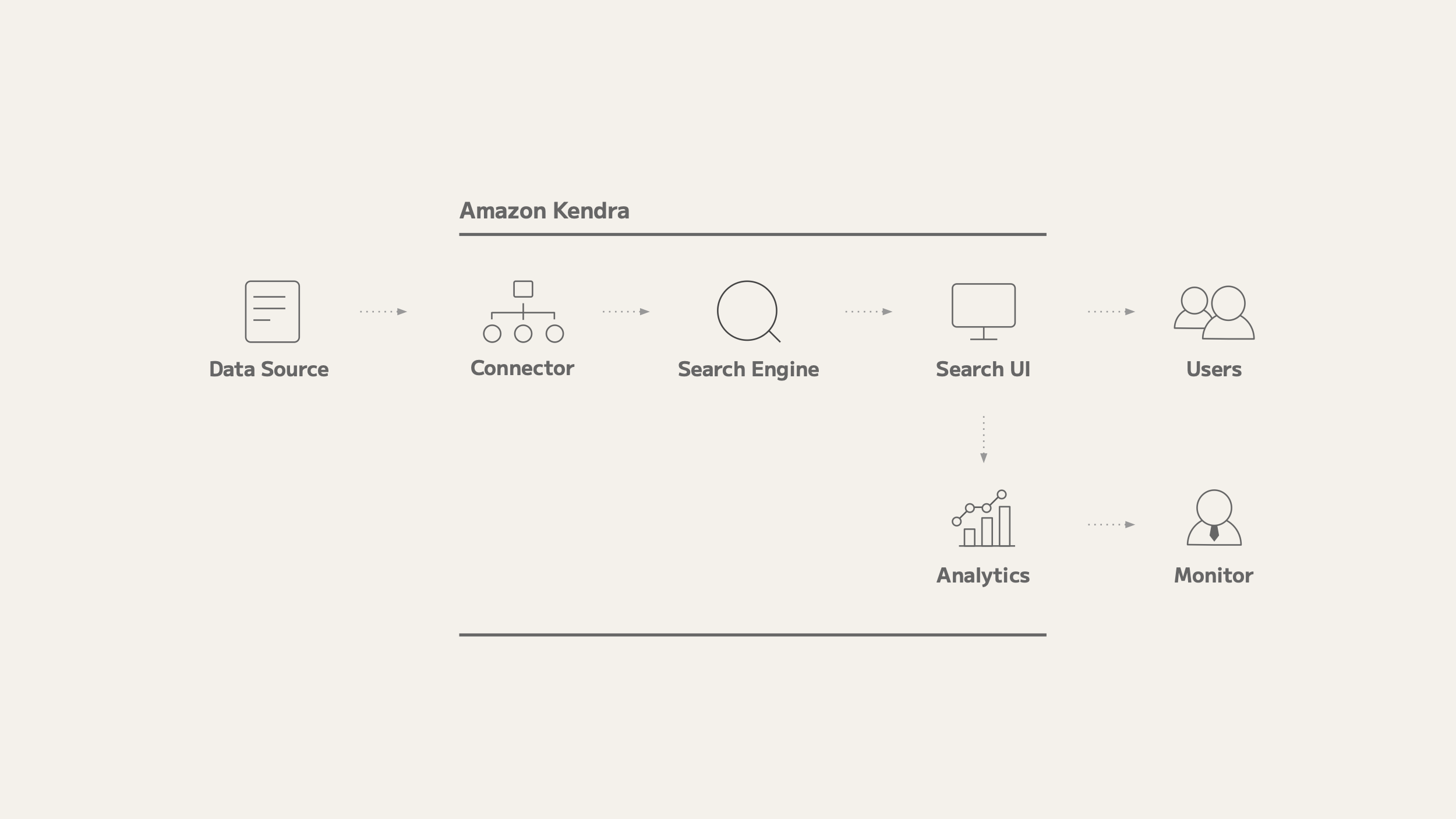
Implementation is just not an exaggerated growth course of; it may be performed with out code by following the Amazon Kendra processing circulation. Listed below are 5 key factors within the implementation course of:
- Information supply (accumulating information) – Every division and worker of our firm regularly held inner examine periods, and thru these actions, information was gathered in a number of media, corresponding to wikis and numerous forms of storage. At the moment, it was straightforward to evaluate the knowledge from the examine periods later. Nevertheless, with a view to extract information a few particular space or know-how, it was essential to evaluate every medium intimately, which was not very handy.
- Connectors (aggregating information) – With the connector performance in Amazon Kendra, we have been capable of hyperlink information scattered all through the corporate into Amazon Kendra and obtain cross-sectional searchability. As well as, the connector is loaded by way of a restricted account, permitting for a security-conscious implementation.
- Search engine (discovering data) – As a result of Amazon Kendra has a search page for usability testing, we have been capable of shortly check the usability of the search engine instantly after loading paperwork to see what sort of information might be discovered. This was very useful in solidifying the picture of the launch.
- Search UI (search web page for customers) – Amazon Kendra has a function referred to as Experience Builder that exposes the search display to customers. This function could be applied with no code, which was very useful in getting suggestions in the course of the check deployment. Along with Expertise Builder, Amazon Kendra additionally helps Python and React.js API implementations, so we will ultimately present personalized search pages to our staff to enhance their expertise.
- Analytics (monitoring utilization developments) – An enterprise search system is simply priceless if lots of people are utilizing it. Amazon Kendra has the ability to monitor what number of searches are being carried out and for what phrases. We use this function to trace utilization developments.
We even have some Q&A associated to our implementation:
- What have been a few of the challenges in gathering inner information? We needed to begin by gathering the information that every division and worker had, however not essentially in a spot that might be straight related to Amazon Kendra.
- How did we profit from Amazon Kendra? We had tried to share information many occasions up to now, however had typically failed. The explanations have been data aggregation, searchability, operational prices, and implementation prices. Amazon Kendra has options that resolve these issues, and we efficiently launched it inside about 3 months of conception. Now we will use Amazon Kendra to search out options to duties that beforehand required the information of people or departments because the collective information of the whole group.
- How did you consider the searchability of the system, and what did you do to enhance it? First, we had many staff work together with the system and get suggestions. One drawback that arose initially of the implementation was that there was a scattering of knowledge that had little worth as information. This was as a result of a few of the knowledge sources contained data from inner weblog posts, for instance. We’re frequently working to enhance the person expertise by deciding on the appropriate knowledge sources.
As talked about earlier, through the use of Amazon Kendra, we have been capable of overcome many implementation hurdles at minimal price. Nevertheless, the most important problem with any such instrument is the adoption barrier that comes after implementation. The subsequent part supplies an instance of how we overcame this hurdle.
How we overcame the barrier to adoption
Have you ever ever seen a instrument that you just spent loads of effort, time, and cash implementing turn out to be out of date with out widespread use? Regardless of how good the performance is at fixing issues, it won’t be efficient if persons are not utilizing it.
One of many initiatives we took with the launch of Amazon Kendra was to supply a chatbot. In different phrases, if you ask a query in a chat instrument, you get a response with the suitable information. As a result of all of our telecommuting staff use a chat instrument every day, utilizing chatbots is far more suitable than having them open a brand new search display of their browsers.
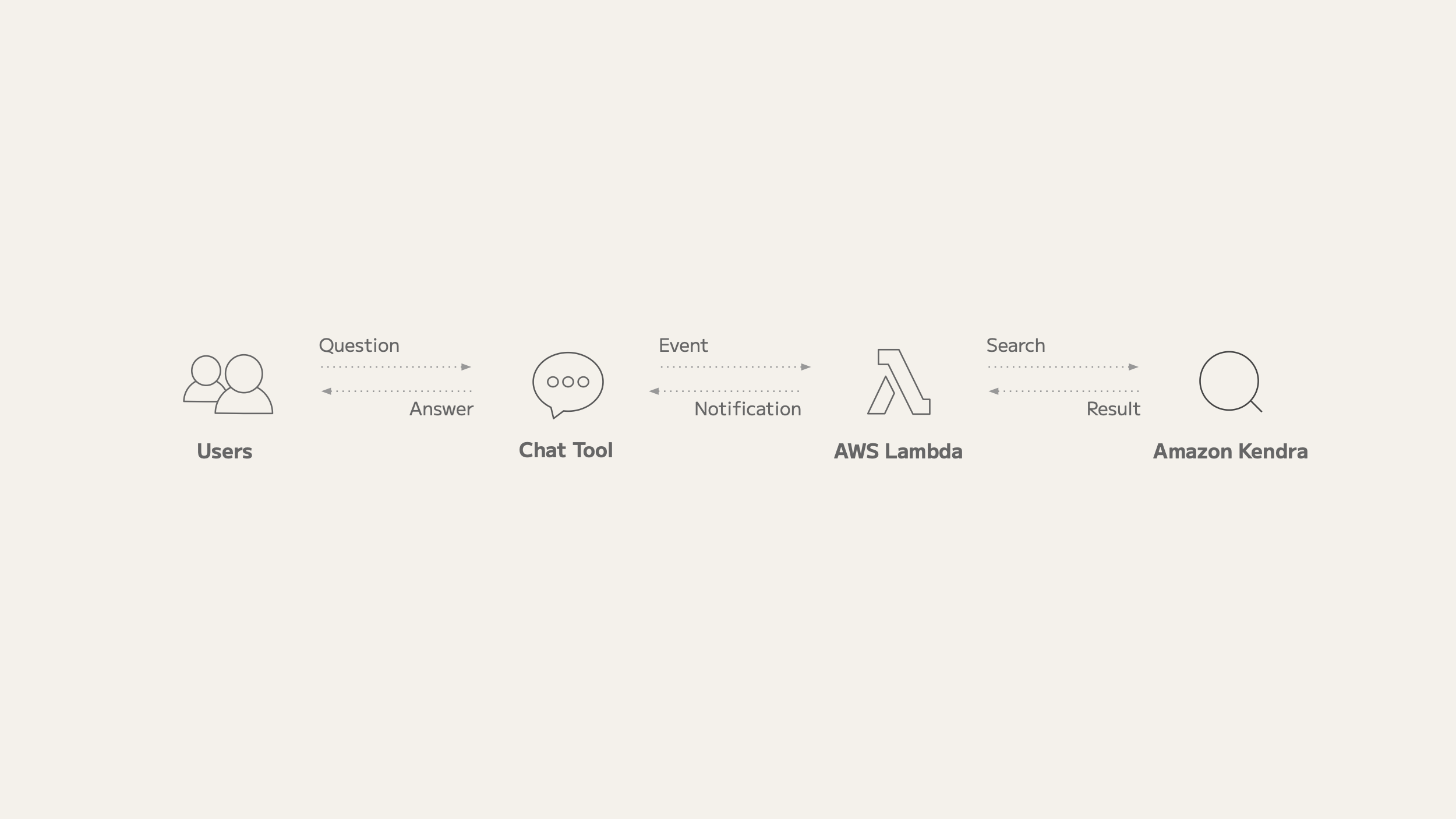
To implement this chatbot, we use Lambda, a service that permits us to run serverless, event-driven applications. Particularly, the next workflow is applied:
- A person posts a query to the chatbot with a point out.
- The chatbot points an occasion to Lambda.
- A Lambda operate detects the occasion and searches Amazon Kendra for the query.
- The Lambda operate posts the search outcomes to the chat instrument.
- The person views the search outcomes.
This course of takes just a few seconds and supplies a high-quality person expertise for information discovery. The vast majority of staff have been uncovered to the information sharing mechanism by way of the chatbot, and there’s no doubt that the chatbot contributed to the diffusion of the mechanism. And since there are some areas that may’t be lined by the chatbot alone, we now have additionally requested them to make use of the personalized search display along side the chatbot to supply a good higher person expertise.
Conclusion
On this put up, we offered a case examine of Amazon Kendra for information sharing and an instance of a chatbot implementation utilizing Lambda to propagate the mechanism. We stay up for seeing Amazon Kendra take one other leap ahead as large-scale language fashions proceed to evolve.
In case you are serious about attempting out Amazon Kendra, take a look at Enhancing enterprise search with Amazon Kendra. BrainPad may also provide help to with inner information sharing and doc exploitation utilizing generative AI. Please contact us for extra data.
Concerning the Creator

Dr. Naoki Okada is a Lead Information Scientist at BrainPad Inc. Together with his cross-functional expertise in enterprise, analytics, and engineering, he helps a variety of shoppers from build up DX organizations to leveraging knowledge in unexplored areas.
