
A step-by-step information utilizing PyTorch Geometric

Graph Neural Networks (GNNs) symbolize probably the most charming and quickly evolving architectures throughout the deep studying panorama. As deep studying fashions designed to course of knowledge structured as graphs, GNNs carry outstanding versatility and highly effective studying capabilities.
Among the many varied kinds of GNNs, the Graph Convolutional Networks (GCNs) have emerged as probably the most prevalent and broadly applied model. GCNs are progressive on account of their potential to leverage each the options of a node and its locality to make predictions, offering an efficient strategy to deal with graph-structured knowledge.
On this article, we are going to delve into the mechanics of the GCN layer and clarify its interior workings. Moreover, we are going to discover its sensible utility for node classification duties, utilizing PyTorch Geometric as our device of selection.
PyTorch Geometric is a specialised extension of PyTorch that has been created particularly for the event and implementation of GNNs. It’s a sophisticated, but user-friendly library that gives a complete suite of instruments to facilitate graph-based machine studying. To begin our journey, the PyTorch Geometric set up shall be required. In case you are utilizing Google Colab, PyTorch ought to already be in place, so all we have to do is execute a couple of extra instructions.
All of the code is obtainable on Google Colab and GitHub.
!pip set up torch_geometric
import torch
import numpy as np
import networkx as nx
import matplotlib.pyplot as plt
Now that PyTorch Geometric is put in, let’s discover the dataset we are going to use on this tutorial.
Graphs are a necessary construction for representing relationships between objects. You may encounter graph knowledge in a mess of real-world eventualities, resembling social and pc networks, chemical constructions of molecules, pure language processing, and picture recognition, to call a couple of.
On this article, we are going to examine the notorious and much-used Zachary’s karate club dataset.

The Zachary’s karate membership dataset embodies the relationships shaped inside a karate membership as noticed by Wayne W. Zachary throughout the Seventies. It’s a form of social community, the place every node represents a membership member, and edges between nodes symbolize interactions that occurred exterior the membership atmosphere.
On this explicit state of affairs, the members of the membership are break up into 4 distinct teams. Our process is to assign the right group to every member (node classification), primarily based on the sample of their interactions.
Let’s import the dataset with PyG’s built-in operate and attempt to perceive the Datasets object it makes use of.
from torch_geometric.datasets import KarateClub
# Import dataset from PyTorch Geometric
dataset = KarateClub()# Print data
print(dataset)
print('------------')
print(f'Variety of graphs: {len(dataset)}')
print(f'Variety of options: {dataset.num_features}')
print(f'Variety of lessons: {dataset.num_classes}')
KarateClub()
------------
Variety of graphs: 1
Variety of options: 34
Variety of lessons: 4
This dataset solely has 1 graph, the place every node has a characteristic vector of 34 dimensions and is a part of one out of 4 lessons (our 4 teams). Really, the Datasets object will be seen as a group of Knowledge (graph) objects.
We will additional examine our distinctive graph to know extra about it.
# Print first factor
print(f'Graph: {dataset[0]}')
Graph: Knowledge(x=[34, 34], edge_index=[2, 156], y=[34], train_mask=[34])
The Data object is especially attention-grabbing. Printing it presents a superb abstract of the graph we’re finding out:
x=[34, 34]is the node characteristic matrix with form (variety of nodes, variety of options). In our case, it signifies that we’ve 34 nodes (our 34 members), every node being related to a 34-dim characteristic vector.edge_index=[2, 156]represents the graph connectivity (how the nodes are linked) with form (2, variety of directed edges).y=[34]is the node ground-truth labels. On this downside, each node is assigned to 1 class (group), so we’ve one worth for every node.train_mask=[34]is an non-obligatory attribute that tells which nodes ought to be used for coaching with a listing ofTrueorFalsestatements.
Let’s print every of those tensors to grasp what they retailer. Let’s begin with the node options.
knowledge = dataset[0]
print(f'x = {knowledge.x.form}')
print(knowledge.x)
x = torch.Dimension([34, 34])
tensor([[1., 0., 0., ..., 0., 0., 0.],
[0., 1., 0., ..., 0., 0., 0.],
[0., 0., 1., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 1., 0., 0.],
[0., 0., 0., ..., 0., 1., 0.],
[0., 0., 0., ..., 0., 0., 1.]])
Right here, the node characteristic matrix x is an identification matrix: it does not include any related data in regards to the nodes. It might include data like age, ability stage, and many others. however this isn’t the case on this dataset. It means we’ll should classify our nodes simply by taking a look at their connections.
Now, let’s print the sting index.
print(f'edge_index = {knowledge.edge_index.form}')
print(knowledge.edge_index)
edge_index = torch.Dimension([2, 156])
tensor([[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1,
1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 3,
3, 3, 3, 3, 3, 4, 4, 4, 5, 5, 5, 5, 6, 6, 6, 6, 7, 7,
7, 7, 8, 8, 8, 8, 8, 9, 9, 10, 10, 10, 11, 12, 12, 13, 13, 13,
13, 13, 14, 14, 15, 15, 16, 16, 17, 17, 18, 18, 19, 19, 19, 20, 20, 21,
21, 22, 22, 23, 23, 23, 23, 23, 24, 24, 24, 25, 25, 25, 26, 26, 27, 27,
27, 27, 28, 28, 28, 29, 29, 29, 29, 30, 30, 30, 30, 31, 31, 31, 31, 31,
31, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 33, 33, 33, 33, 33,
33, 33, 33, 33, 33, 33, 33, 33, 33, 33, 33, 33],
[ 1, 2, 3, 4, 5, 6, 7, 8, 10, 11, 12, 13, 17, 19, 21, 31, 0, 2,
3, 7, 13, 17, 19, 21, 30, 0, 1, 3, 7, 8, 9, 13, 27, 28, 32, 0,
1, 2, 7, 12, 13, 0, 6, 10, 0, 6, 10, 16, 0, 4, 5, 16, 0, 1,
2, 3, 0, 2, 30, 32, 33, 2, 33, 0, 4, 5, 0, 0, 3, 0, 1, 2,
3, 33, 32, 33, 32, 33, 5, 6, 0, 1, 32, 33, 0, 1, 33, 32, 33, 0,
1, 32, 33, 25, 27, 29, 32, 33, 25, 27, 31, 23, 24, 31, 29, 33, 2, 23,
24, 33, 2, 31, 33, 23, 26, 32, 33, 1, 8, 32, 33, 0, 24, 25, 28, 32,
33, 2, 8, 14, 15, 18, 20, 22, 23, 29, 30, 31, 33, 8, 9, 13, 14, 15,
18, 19, 20, 22, 23, 26, 27, 28, 29, 30, 31, 32]])
In graph concept and community evaluation, connectivity between nodes is saved utilizing a wide range of knowledge constructions. The edge_index is one such knowledge construction, the place the graph’s connections are saved in two lists (156 directed edges, which equate to 78 bidirectional edges). The rationale for these two lists is that one record shops the supply nodes, whereas the second identifies the vacation spot nodes.
This methodology is called a coordinate record (COO) format, which is basically a method to effectively retailer a sparse matrix. Sparse matrices are knowledge constructions that effectively retailer matrices with a majority of zero components. Within the COO format, solely non-zero components are saved, saving reminiscence and computational assets.
Contrarily, a extra intuitive and easy strategy to symbolize graph connectivity is thru an adjacency matrix A. It is a sq. matrix the place every factor Aᵢⱼ specifies the presence or absence of an edge from node i to node j within the graph. In different phrases, a non-zero factor Aᵢⱼ implies a connection from node i to node j, and a zero signifies no direct connection.

An adjacency matrix, nevertheless, will not be as space-efficient because the COO format for sparse matrices or graphs with fewer edges. Nevertheless, for readability and straightforward interpretation, the adjacency matrix stays a well-liked selection for representing graph connectivity.
The adjacency matrix will be inferred from the edge_index with a utility operate to_dense_adj().
from torch_geometric.utils import to_dense_adj
A = to_dense_adj(knowledge.edge_index)[0].numpy().astype(int)
print(f'A = {A.form}')
print(A)
A = (34, 34)
[[0 1 1 ... 1 0 0]
[1 0 1 ... 0 0 0]
[1 1 0 ... 0 1 0]
...
[1 0 0 ... 0 1 1]
[0 0 1 ... 1 0 1]
[0 0 0 ... 1 1 0]]
With graph knowledge, it’s comparatively unusual for nodes to be densely interconnected. As you’ll be able to see, our adjacency matrix A is sparse (full of zeros).
In lots of real-world graphs, most nodes are linked to just a few different nodes, leading to a lot of zeros within the adjacency matrix. Storing so many zeros will not be environment friendly in any respect, which is why the COO format is adopted by PyG.
Quite the opposite, ground-truth labels are straightforward to grasp.
print(f'y = {knowledge.y.form}')
print(knowledge.y)
y = torch.Dimension([34])
tensor([1, 1, 1, 1, 3, 3, 3, 1, 0, 1, 3, 1, 1, 1, 0, 0, 3, 1, 0, 1, 0, 1, 0, 0,
2, 2, 0, 0, 2, 0, 0, 2, 0, 0])
Our node ground-truth labels saved in y merely encode the group quantity (0, 1, 2, 3) for every node, which is why we’ve 34 values.
Lastly, let’s print the practice masks.
print(f'train_mask = {knowledge.train_mask.form}')
print(knowledge.train_mask)
train_mask = torch.Dimension([34])
tensor([ True, False, False, False, True, False, False, False, True, False,
False, False, False, False, False, False, False, False, False, False,
False, False, False, False, True, False, False, False, False, False,
False, False, False, False])
The practice masks reveals which nodes are supposed for use for coaching with True statements. These nodes symbolize the coaching set, whereas the others will be thought of because the check set. This division helps in mannequin analysis by offering unseen knowledge for testing.
However we’re not performed but! The Data object has much more to supply. It offers varied utility capabilities that allow the investigation of a number of properties of the graph. For example:
is_directed()tells you if the graph is directed. A directed graph signifies that the adjacency matrix will not be symmetric, i.e., the course of edges issues within the connections between nodes.isolated_nodes()checks if some nodes are not linked to the remainder of the graph. These nodes are more likely to pose challenges in duties like classification on account of their lack of connections.has_self_loops()signifies if no less than one node is linked to itself. That is distinct from the idea of loops: a loop implies a path that begins and ends on the identical node, traversing different nodes in between.
Within the context of the Zachary’s karate membership dataset, all these properties return False. This suggests that the graph will not be directed, doesn’t have any remoted nodes, and none of its nodes are linked to themselves.
print(f'Edges are directed: {knowledge.is_directed()}')
print(f'Graph has remoted nodes: {knowledge.has_isolated_nodes()}')
print(f'Graph has loops: {knowledge.has_self_loops()}')
Edges are directed: False
Graph has remoted nodes: False
Graph has loops: False
Lastly, we will convert a graph from PyTorch Geometric to the favored graph library NetworkX utilizing to_networkx. That is notably helpful to visualise a small graph with networkx and matplotlib.
Let’s plot our dataset with a special coloration for every group.
from torch_geometric.utils import to_networkx
G = to_networkx(knowledge, to_undirected=True)
plt.determine(figsize=(12,12))
plt.axis('off')
nx.draw_networkx(G,
pos=nx.spring_layout(G, seed=0),
with_labels=True,
node_size=800,
node_color=knowledge.y,
cmap="hsv",
vmin=-2,
vmax=3,
width=0.8,
edge_color="gray",
font_size=14
)
plt.present()

This plot of Zachary’s karate membership shows our 34 nodes, 78 (bidirectional) edges, and 4 labels with 4 completely different colours. Now that we’ve seen the necessities of loading and dealing with a dataset with PyTorch Geometric, we will introduce the Graph Convolutional Community structure.
This part goals to introduce and construct the graph convolutional layer from the bottom up.
In conventional neural networks, linear layers apply a linear transformation to the incoming knowledge. This transformation converts enter options x into hidden vectors h by the usage of a weight matrix 𝐖. Ignoring biases in the interim, this may be expressed as:

With graph knowledge, an extra layer of complexity is added by the connections between nodes. These connections matter as a result of, sometimes, in networks, it’s assumed that related nodes usually tend to be linked to one another than dissimilar ones, a phenomenon referred to as network homophily.
We will enrich our node illustration by merging its options with these of its neighbors. This operation is known as convolution, or neighborhood aggregation. Let’s symbolize the neighborhood of node i together with itself as Ñ.

In contrast to filters in Convolutional Neural Networks (CNNs), our weight matrix 𝐖 is exclusive and shared amongst each node. However there’s one other challenge: nodes do not need a fastened variety of neighbors like pixels do.
How will we handle instances the place one node has just one neighbor, and one other has 500? If we merely sum the characteristic vectors, the ensuing embedding h can be a lot bigger for the node with 500 neighbors. To make sure a related vary of values for all nodes and comparability between them, we will normalize the consequence primarily based on the diploma of nodes, the place diploma refers back to the variety of connections a node has.

We’re virtually there! Launched by Kipf et al. (2016), the graph convolutional layer has one last enchancment.
The authors noticed that options from nodes with quite a few neighbors propagate way more simply than these from extra remoted nodes. To offset this impact, they instructed assigning larger weights to options from nodes with fewer neighbors, thus balancing the affect throughout all nodes. This operation is written as:

Observe that when i and j have the identical variety of neighbors, it’s equal to our personal layer. Now, let’s see tips on how to implement it in Python with PyTorch Geometric.
PyTorch Geometric offers the GCNConv operate, which straight implements the graph convolutional layer.
On this instance, we’ll create a primary Graph Convolutional Community with a single GCN layer, a ReLU activation operate, and a linear output layer. This output layer will yield 4 values equivalent to our 4 classes, with the very best worth figuring out the category of every node.
Within the following code block, we outline the GCN layer with a third-dimensional hidden layer.
from torch.nn import Linear
from torch_geometric.nn import GCNConv
class GCN(torch.nn.Module):
def __init__(self):
tremendous().__init__()
self.gcn = GCNConv(dataset.num_features, 3)
self.out = Linear(3, dataset.num_classes) def ahead(self, x, edge_index):
h = self.gcn(x, edge_index).relu()
z = self.out(h)
return h, zmannequin = GCN()
print(mannequin)
GCN(
(gcn): GCNConv(34, 3)
(out): Linear(in_features=3, out_features=4, bias=True)
)
If we added a second GCN layer, our mannequin wouldn’t solely mixture characteristic vectors from the neighbors of every node, but additionally from the neighbors of those neighbors.
We will stack a number of graph layers to mixture increasingly distant values, however there’s a catch: if we add too many layers, the aggregation turns into so intense that every one the embeddings find yourself wanting the identical. This phenomenon is known as over-smoothing and generally is a actual downside when you might have too many layers.
Now that we’ve outlined our GNN, let’s write a easy coaching loop with PyTorch. I selected an everyday cross-entropy loss because it’s a multi-class classification process, with Adam as optimizer. On this article, we gained’t implement a practice/check break up to maintain issues easy and concentrate on how GNNs be taught as a substitute.
The coaching loop is normal: we attempt to predict the right labels, and we examine the GCN’s outcomes to the values saved in knowledge.y. The error is calculated by the cross-entropy loss and backpropagated with Adam to fine-tune our GNN’s weights and biases. Lastly, we print metrics each 10 epochs.
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(mannequin.parameters(), lr=0.02)
# Calculate accuracy
def accuracy(pred_y, y):
return (pred_y == y).sum() / len(y)# Knowledge for animations
embeddings = []
losses = []
accuracies = []
outputs = []# Coaching loop
for epoch in vary(201):
# Clear gradients
optimizer.zero_grad() # Ahead move
h, z = mannequin(knowledge.x, knowledge.edge_index) # Calculate loss operate
loss = criterion(z, knowledge.y) # Calculate accuracy
acc = accuracy(z.argmax(dim=1), knowledge.y) # Compute gradients
loss.backward() # Tune parameters
optimizer.step() # Retailer knowledge for animations
embeddings.append(h)
losses.append(loss)
accuracies.append(acc)
outputs.append(z.argmax(dim=1)) # Print metrics each 10 epochs
if epoch % 10 == 0:
print(f'Epoch {epoch:>3} | Loss: {loss:.2f} | Acc: {acc*100:.2f}%')
Epoch 0 | Loss: 1.40 | Acc: 41.18%
Epoch 10 | Loss: 1.21 | Acc: 47.06%
Epoch 20 | Loss: 1.02 | Acc: 67.65%
Epoch 30 | Loss: 0.80 | Acc: 73.53%
Epoch 40 | Loss: 0.59 | Acc: 73.53%
Epoch 50 | Loss: 0.39 | Acc: 94.12%
Epoch 60 | Loss: 0.23 | Acc: 97.06%
Epoch 70 | Loss: 0.13 | Acc: 100.00%
Epoch 80 | Loss: 0.07 | Acc: 100.00%
Epoch 90 | Loss: 0.05 | Acc: 100.00%
Epoch 100 | Loss: 0.03 | Acc: 100.00%
Epoch 110 | Loss: 0.02 | Acc: 100.00%
Epoch 120 | Loss: 0.02 | Acc: 100.00%
Epoch 130 | Loss: 0.02 | Acc: 100.00%
Epoch 140 | Loss: 0.01 | Acc: 100.00%
Epoch 150 | Loss: 0.01 | Acc: 100.00%
Epoch 160 | Loss: 0.01 | Acc: 100.00%
Epoch 170 | Loss: 0.01 | Acc: 100.00%
Epoch 180 | Loss: 0.01 | Acc: 100.00%
Epoch 190 | Loss: 0.01 | Acc: 100.00%
Epoch 200 | Loss: 0.01 | Acc: 100.00%
Nice! With out a lot shock, we attain 100% accuracy on the coaching set (full dataset). It signifies that our mannequin discovered to accurately assign each member of the karate membership to its appropriate group.
We will produce a neat visualization by animating the graph and see the evolution of the GNN’s predictions throughout the coaching course of.
%%seize
from IPython.show import HTML
from matplotlib import animation
plt.rcParams["animation.bitrate"] = 3000
def animate(i):
G = to_networkx(knowledge, to_undirected=True)
nx.draw_networkx(G,
pos=nx.spring_layout(G, seed=0),
with_labels=True,
node_size=800,
node_color=outputs[i],
cmap="hsv",
vmin=-2,
vmax=3,
width=0.8,
edge_color="gray",
font_size=14
)
plt.title(f'Epoch {i} | Loss: {losses[i]:.2f} | Acc: {accuracies[i]*100:.2f}%',
fontsize=18, pad=20)fig = plt.determine(figsize=(12, 12))
plt.axis('off')anim = animation.FuncAnimation(fig, animate,
np.arange(0, 200, 10), interval=500, repeat=True)
html = HTML(anim.to_html5_video())
show(html)

The primary predictions are random, however the GCN completely labels each node after some time. Certainly, the ultimate graph is similar because the one we plotted on the finish of the primary part. However what does the GCN actually be taught?
By aggregating options from neighboring nodes, the GNN learns a vector illustration (or embedding) of each node within the community. In our mannequin, the ultimate layer simply learns tips on how to use these representations to supply the very best classifications. Nevertheless, embeddings are the true merchandise of GNNs.
Let’s print the embeddings discovered by our mannequin.
# Print embeddings
print(f'Remaining embeddings = {h.form}')
print(h)
Remaining embeddings = torch.Dimension([34, 3])
tensor([[1.9099e+00, 2.3584e+00, 7.4027e-01],
[2.6203e+00, 2.7997e+00, 0.0000e+00],
[2.2567e+00, 2.2962e+00, 6.4663e-01],
[2.0802e+00, 2.8785e+00, 0.0000e+00],
[0.0000e+00, 0.0000e+00, 2.9694e+00],
[0.0000e+00, 0.0000e+00, 3.3817e+00],
[0.0000e+00, 1.5008e-04, 3.4246e+00],
[1.7593e+00, 2.4292e+00, 2.4551e-01],
[1.9757e+00, 6.1032e-01, 1.8986e+00],
[1.7770e+00, 1.9950e+00, 6.7018e-01],
[0.0000e+00, 1.1683e-04, 2.9738e+00],
[1.8988e+00, 2.0512e+00, 2.6225e-01],
[1.7081e+00, 2.3618e+00, 1.9609e-01],
[1.8303e+00, 2.1591e+00, 3.5906e-01],
[2.0755e+00, 2.7468e-01, 1.9804e+00],
[1.9676e+00, 3.7185e-01, 2.0011e+00],
[0.0000e+00, 0.0000e+00, 3.4787e+00],
[1.6945e+00, 2.0350e+00, 1.9789e-01],
[1.9808e+00, 3.2633e-01, 2.1349e+00],
[1.7846e+00, 1.9585e+00, 4.8021e-01],
[2.0420e+00, 2.7512e-01, 1.9810e+00],
[1.7665e+00, 2.1357e+00, 4.0325e-01],
[1.9870e+00, 3.3886e-01, 2.0421e+00],
[2.0614e+00, 5.1042e-01, 2.4872e+00],
...
[2.1778e+00, 4.4730e-01, 2.0077e+00],
[3.8906e-02, 2.3443e+00, 1.9195e+00],
[3.0748e+00, 0.0000e+00, 3.0789e+00],
[3.4316e+00, 1.9716e-01, 2.5231e+00]], grad_fn=<ReluBackward0>)
As you’ll be able to see, embeddings don’t have to have the identical dimensions as characteristic vectors. Right here, I selected to scale back the variety of dimensions from 34 (dataset.num_features) to 3 to get a pleasant visualization in 3D.
Let’s plot these embeddings earlier than any coaching occurs, at epoch 0.
# Get first embedding at epoch = 0
embed = h.detach().cpu().numpy()
fig = plt.determine(figsize=(12, 12))
ax = fig.add_subplot(projection='3d')
ax.patch.set_alpha(0)
plt.tick_params(left=False,
backside=False,
labelleft=False,
labelbottom=False)
ax.scatter(embed[:, 0], embed[:, 1], embed[:, 2],
s=200, c=knowledge.y, cmap="hsv", vmin=-2, vmax=3)plt.present()

We see each node from Zachary’s karate membership with their true labels (and never the mannequin’s predictions). For now, they’re far and wide because the GNN will not be skilled but. But when we plot these embeddings at every step of the coaching loop, we’d be capable of visualize what the GNN really learns.
Let’s see how they evolve over time, because the GCN will get higher and higher at classifying nodes.
%%seize
def animate(i):
embed = embeddings[i].detach().cpu().numpy()
ax.clear()
ax.scatter(embed[:, 0], embed[:, 1], embed[:, 2],
s=200, c=knowledge.y, cmap="hsv", vmin=-2, vmax=3)
plt.title(f'Epoch {i} | Loss: {losses[i]:.2f} | Acc: {accuracies[i]*100:.2f}%',
fontsize=18, pad=40)fig = plt.determine(figsize=(12, 12))
plt.axis('off')
ax = fig.add_subplot(projection='3d')
plt.tick_params(left=False,
backside=False,
labelleft=False,
labelbottom=False)anim = animation.FuncAnimation(fig, animate,
np.arange(0, 200, 10), interval=800, repeat=True)
html = HTML(anim.to_html5_video())
show(html)
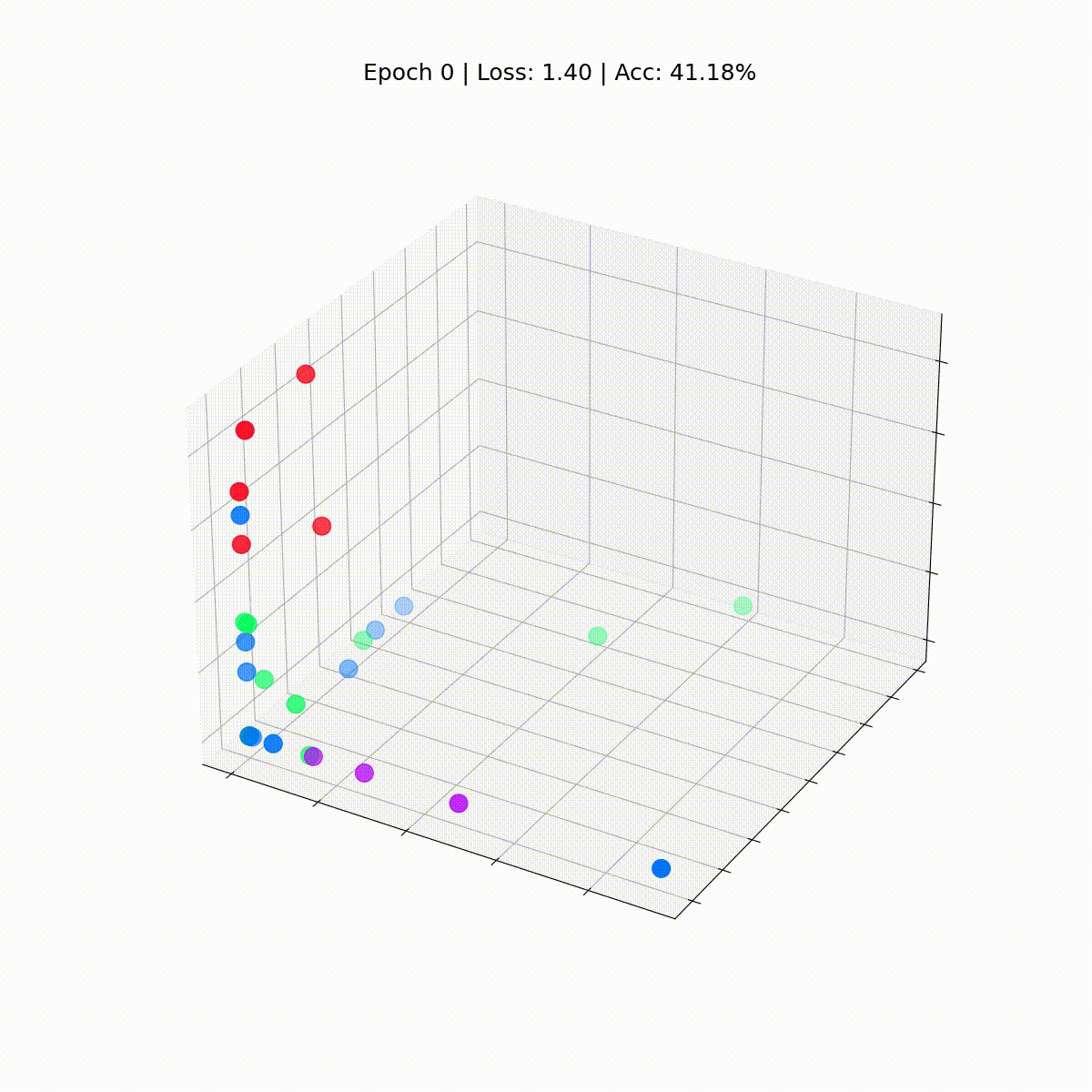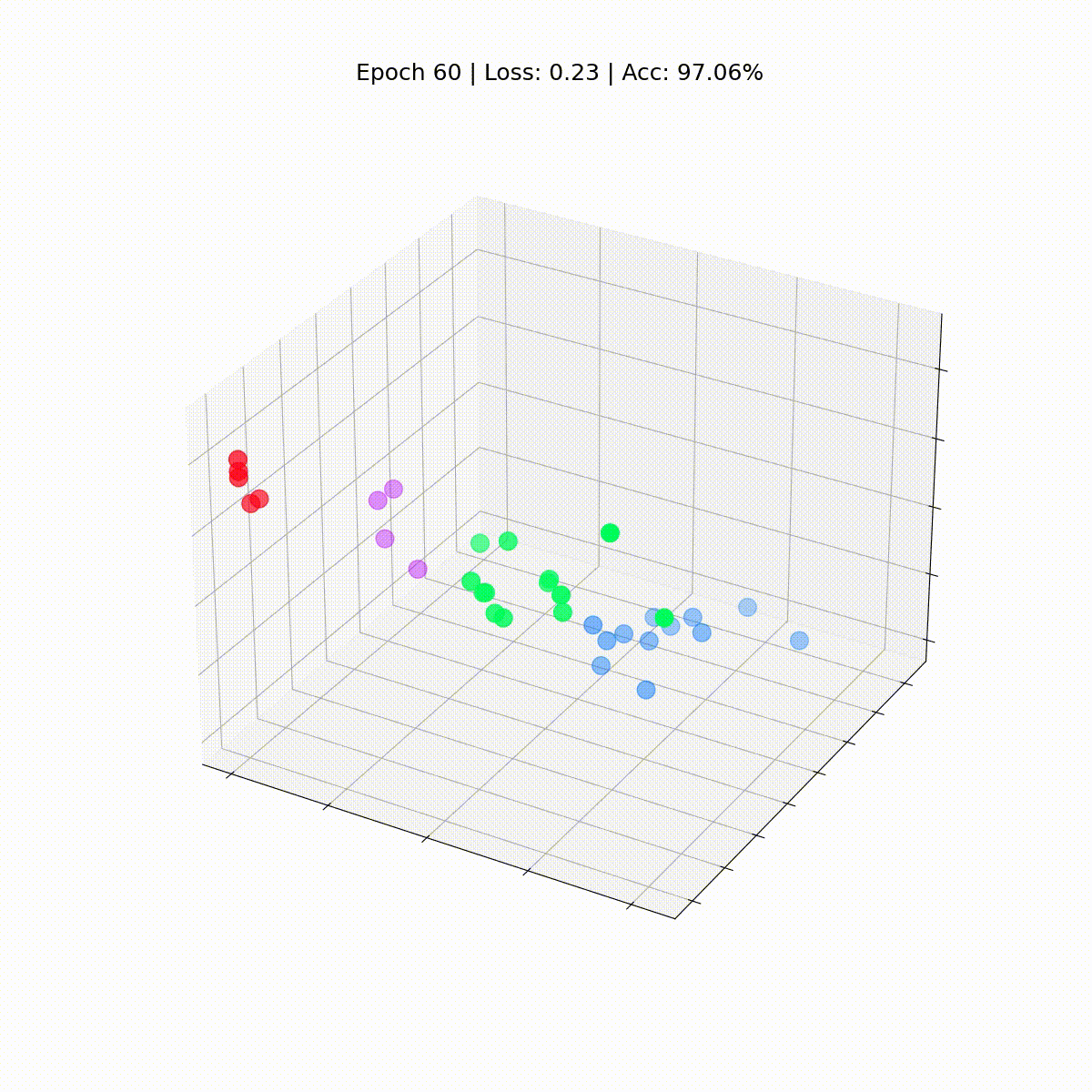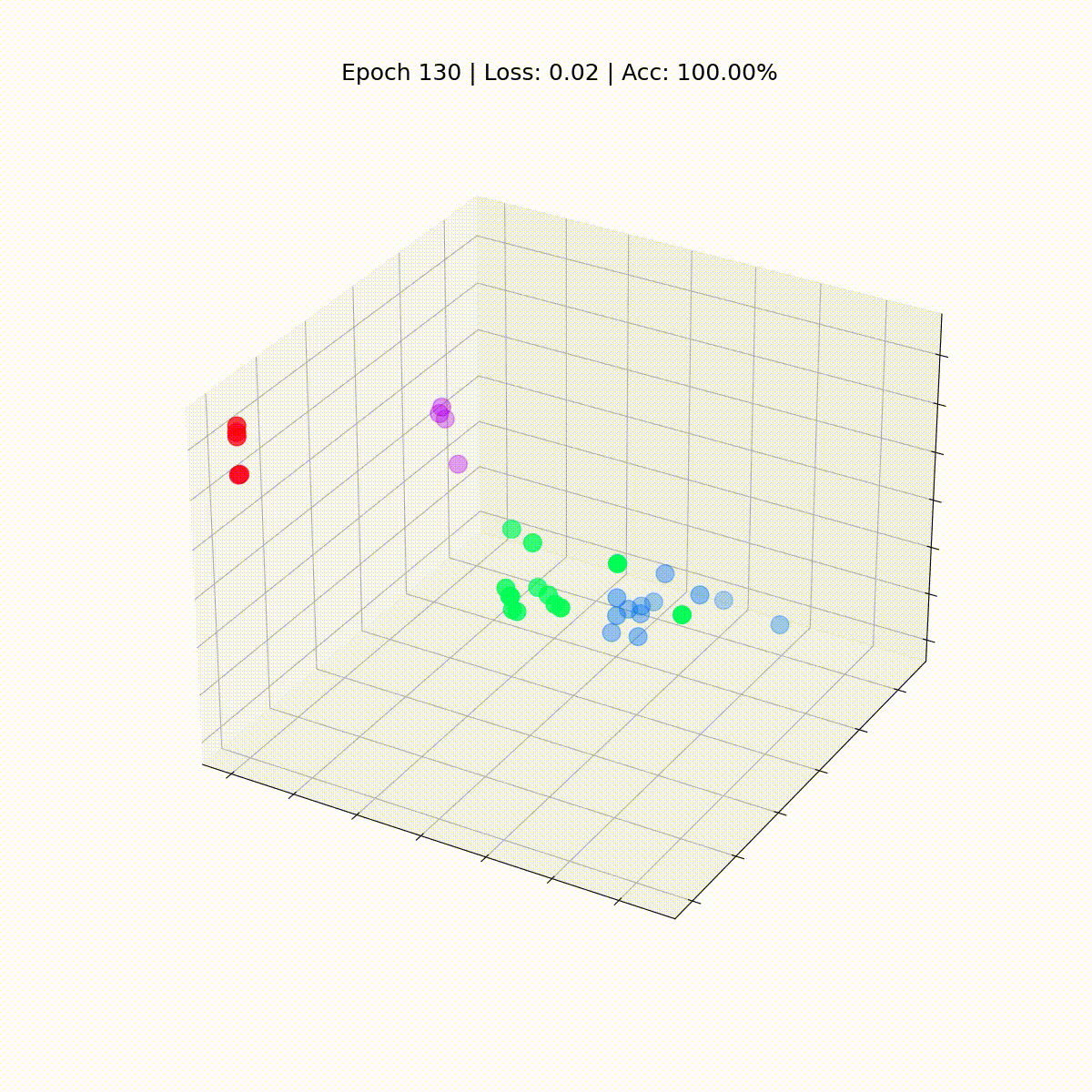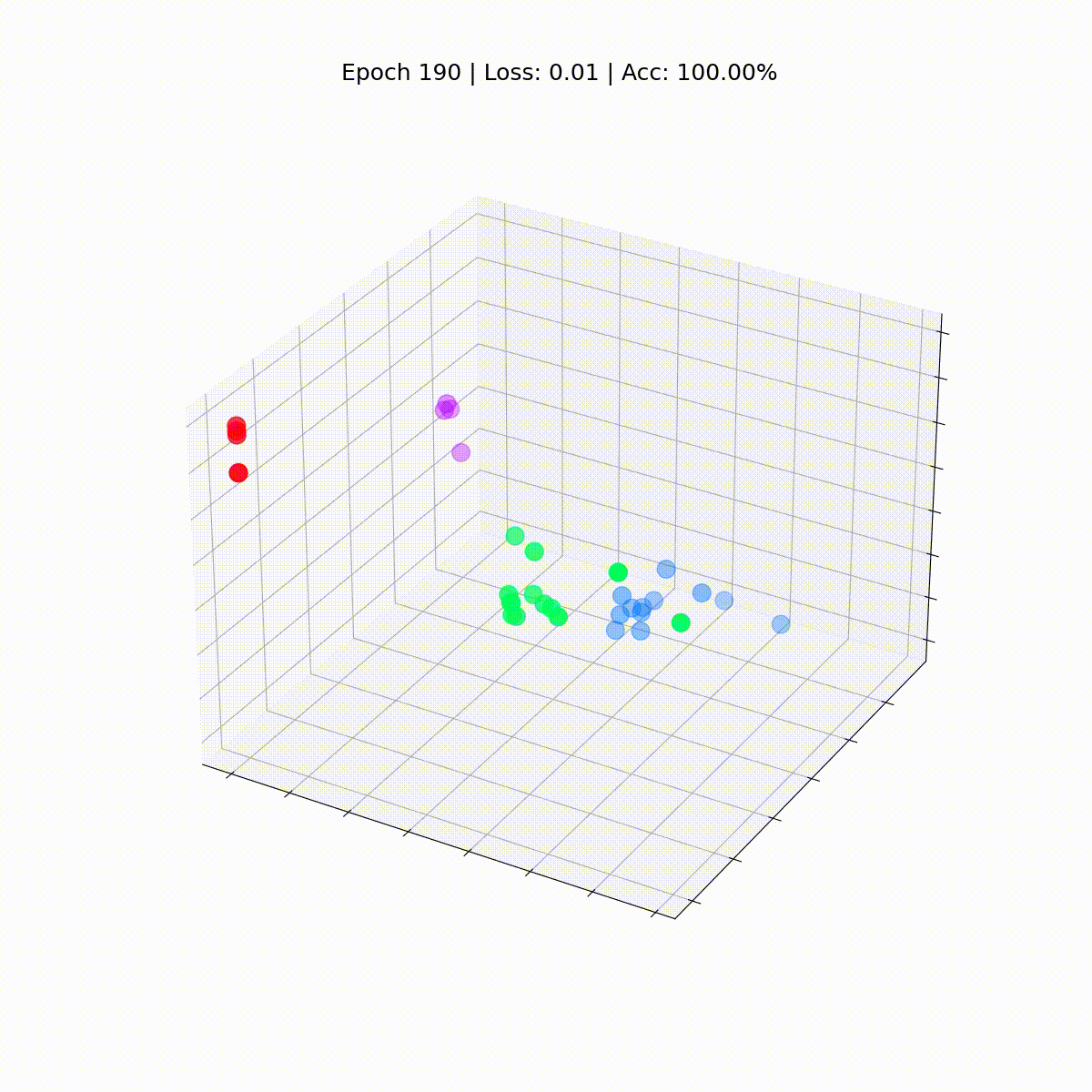
Our Graph Convolutional Community (GCN) has successfully discovered embeddings that group related nodes into distinct clusters. This allows the ultimate linear layer to differentiate them into separate lessons with ease.
Embeddings aren’t distinctive to GNNs: they are often discovered all over the place in deep studying. They don’t should be 3D both: really, they hardly ever are. For example, language fashions like BERT produce embeddings with 768 and even 1024 dimensions.
Further dimensions retailer extra details about nodes, textual content, photos, and many others. however additionally they create larger fashions which can be harder to coach. That is why preserving low-dimensional embeddings so long as doable is advantageous.
Graph Convolutional Networks are an extremely versatile structure that may be utilized in many contexts. On this article, we familiarized ourselves with the PyTorch Geometric library and objects like Datasets and Knowledge. Then, we efficiently reconstructed a graph convolutional layer from the bottom up. Subsequent, we put concept into apply by implementing a GCN, which gave us an understanding of sensible points and the way particular person elements work together. Lastly, we visualized the coaching course of and obtained a transparent perspective of what it includes for such a community.
Zachary’s karate membership is a simplistic dataset, however it’s adequate to grasp an important ideas in graph knowledge and GNNs. Though we solely talked about node classification on this article, there are different duties GNNs can accomplish: hyperlink prediction (e.g., to suggest a good friend), graph classification (e.g., to label molecules), graph era (e.g., to create new molecules), and so forth.
Past GCN, quite a few GNN layers and architectures have been proposed by researchers. Within the subsequent article, we’ll introduce the Graph Attention Network (GAT) structure, which dynamically computes the GCN’s normalization issue and the significance of every reference to an consideration mechanism.
If you wish to know extra about graph neural networks, dive deeper into the world of GNNs with my guide, Hands-On Graph Neural Networks.

