
These days, nearly all of our prospects is happy about massive language fashions (LLMs) and pondering how generative AI might remodel their enterprise. Nonetheless, bringing such options and fashions to the business-as-usual operations shouldn’t be a simple activity. On this submit, we talk about learn how to operationalize generative AI purposes utilizing MLOps rules resulting in basis mannequin operations (FMOps). Moreover, we deep dive on the most typical generative AI use case of text-to-text purposes and LLM operations (LLMOps), a subset of FMOps. The next determine illustrates the subjects we talk about.
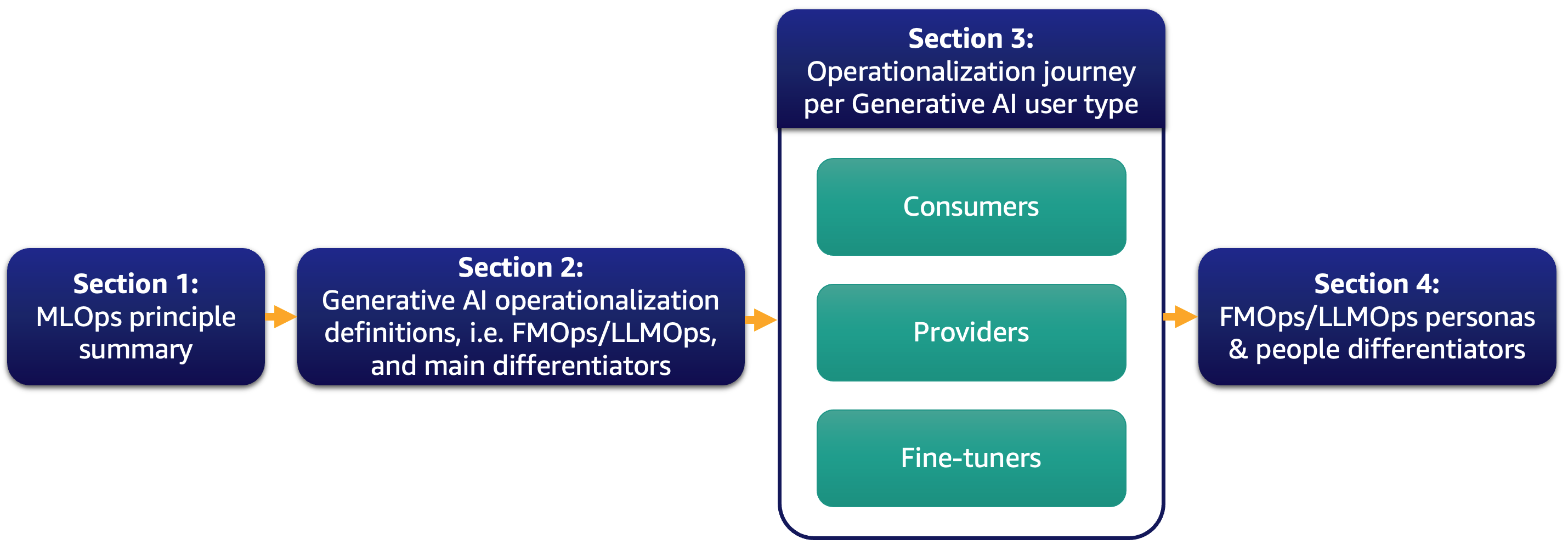
Particularly, we briefly introduce MLOps rules and give attention to the principle differentiators in comparison with FMOps and LLMOps concerning processes, folks, mannequin choice and analysis, knowledge privateness, and mannequin deployment. This is applicable to prospects that use them out of the field, create basis fashions from scratch, or fine-tune them. Our method applies to each open-source and proprietary fashions equally.
ML operationalization abstract
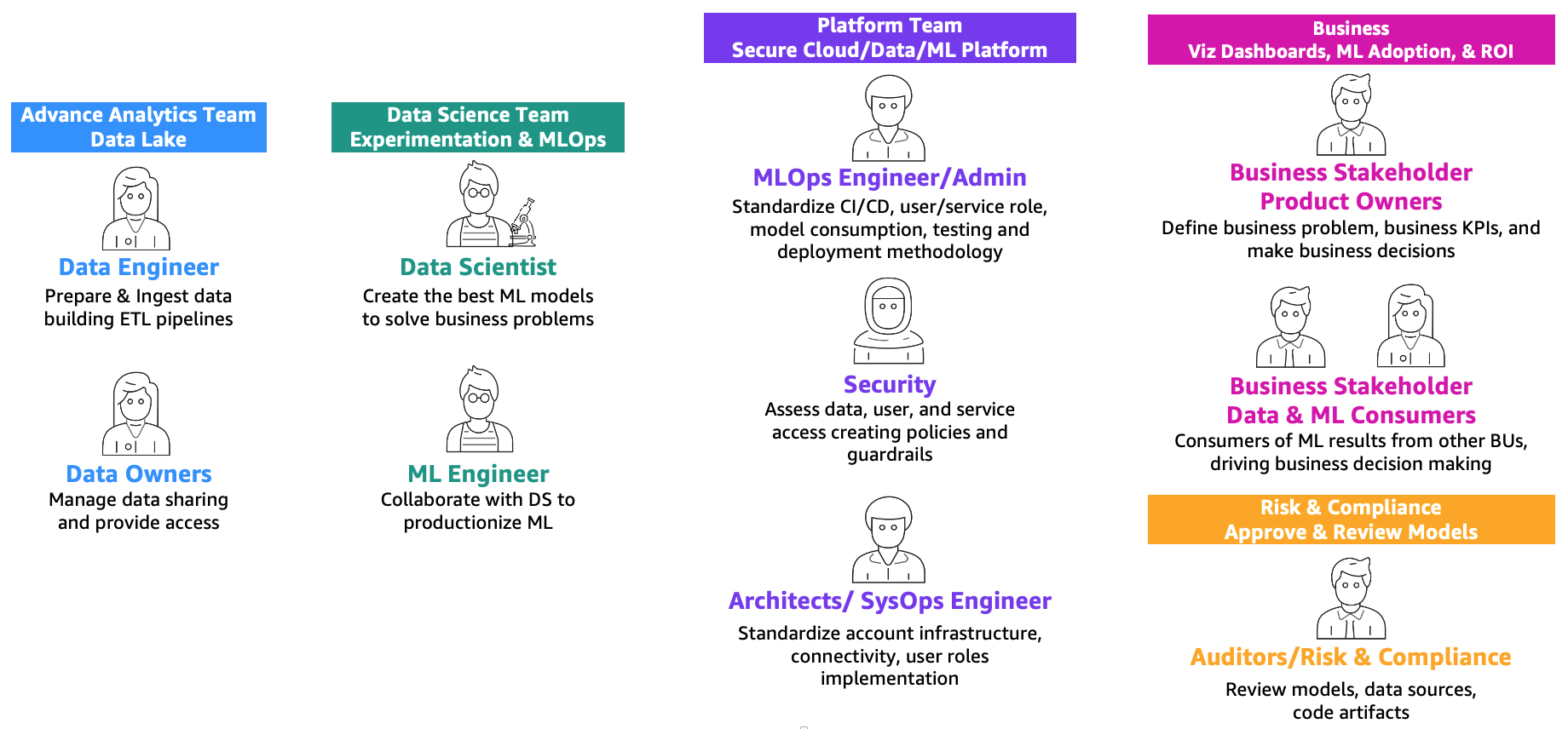
As outlined within the submit MLOps foundation roadmap for enterprises with Amazon SageMaker, ML and operations (MLOps) is the mix of individuals, processes, and know-how to productionize machine studying (ML) options effectively. To attain this, a mixture of groups and personas must collaborate, as illustrated within the following determine.
These groups are as follows:
- Superior analytics crew (knowledge lake and knowledge mesh) – Knowledge engineers are accountable for getting ready and ingesting knowledge from a number of sources, constructing ETL (extract, remodel, and cargo) pipelines to curate and catalog the info, and put together the mandatory historic knowledge for the ML use instances. These knowledge house owners are centered on offering entry to their knowledge to a number of enterprise models or groups.
- Knowledge science crew – Knowledge scientists must give attention to creating one of the best mannequin based mostly on predefined key efficiency indicators (KPIs) working in notebooks. After the completion of the analysis part, the info scientists must collaborate with ML engineers to create automations for constructing (ML pipelines) and deploying fashions into manufacturing utilizing CI/CD pipelines.
- Enterprise crew – A product proprietor is accountable for defining the enterprise case, necessities, and KPIs for use to guage mannequin efficiency. The ML customers are different enterprise stakeholders who use the inference outcomes (predictions) to drive selections.
- Platform crew – Architects are accountable for the general cloud structure of the enterprise and the way all of the totally different providers are related collectively. Safety SMEs assessment the structure based mostly on enterprise safety insurance policies and wishes. MLOps engineers are accountable for offering a safe setting for knowledge scientists and ML engineers to productionize the ML use instances. Particularly, they’re accountable for standardizing CI/CD pipelines, consumer and repair roles and container creation, mannequin consumption, testing, and deployment methodology based mostly on enterprise and safety necessities.
- Threat and compliance crew – For extra restrictive environments, auditors are accountable for assessing the info, code, and mannequin artifacts and ensuring that the enterprise is compliant with rules, similar to knowledge privateness.
Notice that a number of personas will be coated by the identical individual relying on the scaling and MLOps maturity of the enterprise.
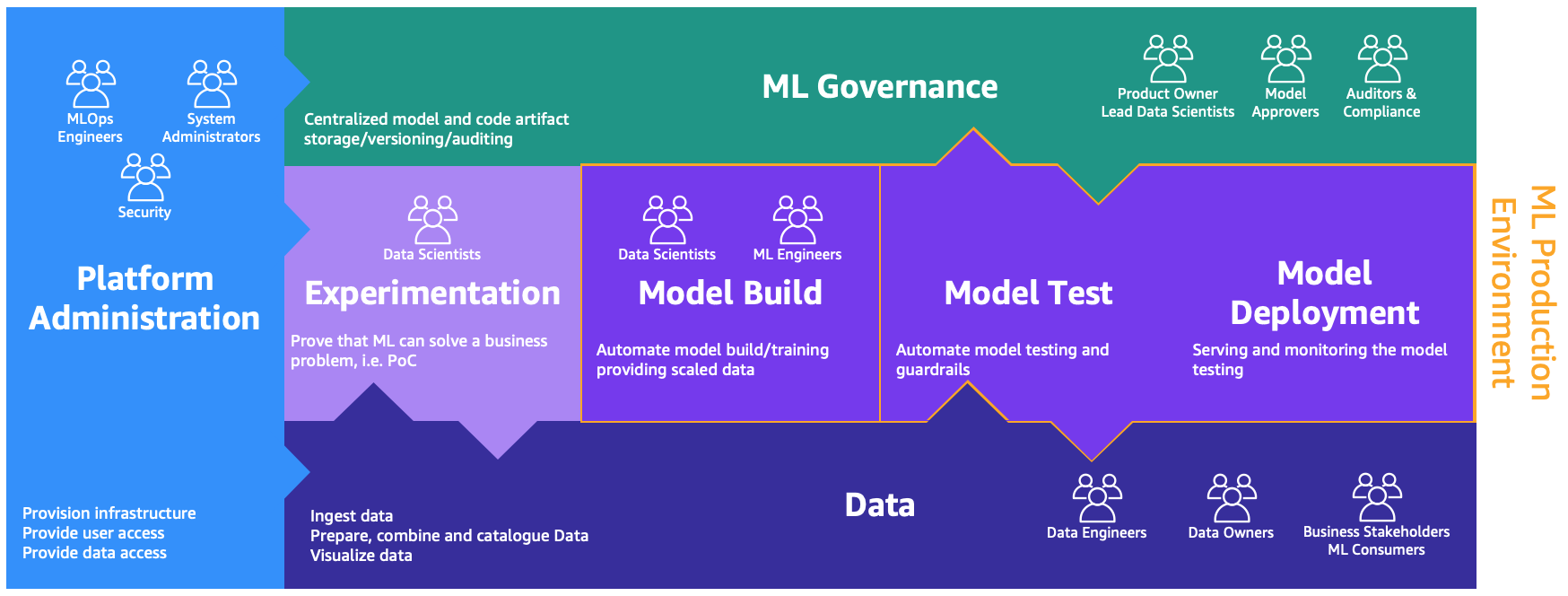
These personas want devoted environments to carry out the totally different processes, as illustrated within the following determine.
The environments are as follows:
- Platform administration – The platform administration setting is the place the place the platform crew has entry to create AWS accounts and hyperlink the precise customers and knowledge
- Knowledge – The information layer, usually generally known as the info lake or knowledge mesh, is the setting that knowledge engineers or house owners and enterprise stakeholders use to arrange, work together, and visualize with the info
- Experimentation – The information scientists use a sandbox or experimentation setting to check new libraries and ML methods to show that their proof of idea can remedy enterprise issues
- Mannequin construct, mannequin check, mannequin deployment – The mannequin construct, check, and deployment setting is the layer of MLOps, the place knowledge scientists and ML engineers collaborate to automate and transfer the analysis to manufacturing
- ML governance – The final piece of the puzzle is the ML governance setting, the place all of the mannequin and code artifacts are saved, reviewed, and audited by the corresponding personas
The next diagram illustrates the reference structure, which has already been mentioned in MLOps foundation roadmap for enterprises with Amazon SageMaker.
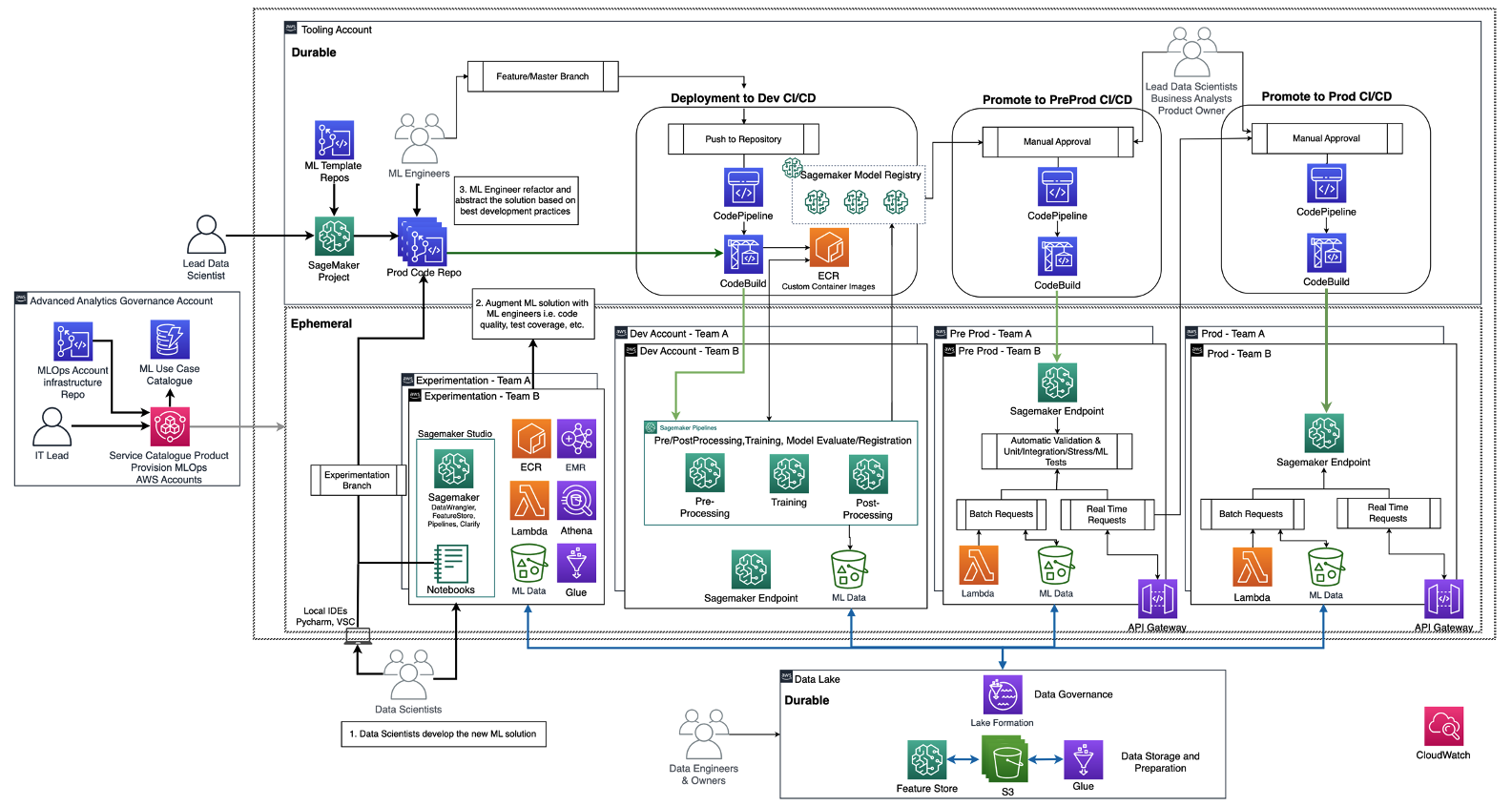
Every enterprise unit has every personal set of improvement (automated mannequin coaching and constructing), preproduction (computerized testing), and manufacturing (mannequin deployment and serving) accounts to productionize ML use instances, which retrieve knowledge from a centralized or decentralized knowledge lake or knowledge mesh, respectively. All of the produced fashions and code automation are saved in a centralized tooling account utilizing the potential of a mannequin registry. The infrastructure code for all these accounts is versioned in a shared service account (superior analytics governance account) that the platform crew can summary, templatize, preserve, and reuse for the onboarding to the MLOps platform of each new crew.
Generative AI definitions and variations to MLOps
In basic ML, the previous mixture of individuals, processes, and know-how can assist you productize your ML use instances. Nonetheless, in generative AI, the character of the use instances requires both an extension of these capabilities or new capabilities. Certainly one of these new notions is the muse mannequin (FM). They’re referred to as as such as a result of they can be utilized to create a variety of different AI fashions, as illustrated within the following determine.
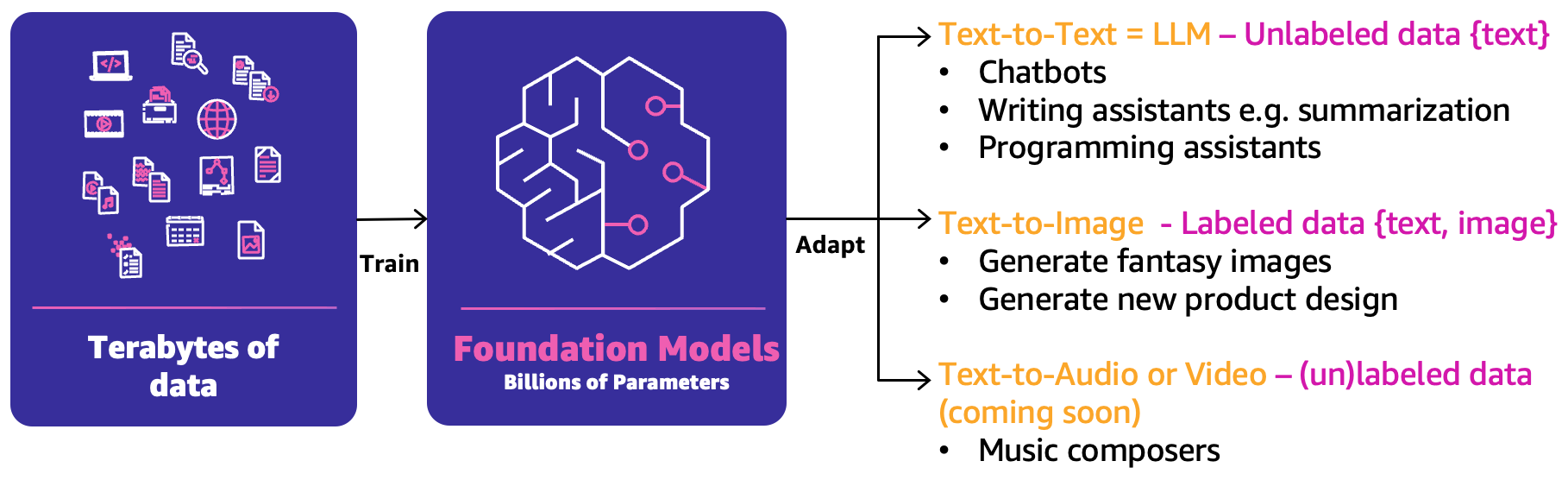
FM have been educated based mostly on terabytes of knowledge and have a whole bunch of billions of parameters to have the ability to predict the following finest reply based mostly on three predominant classes of generative AI use instances:
- Textual content-to-text – The FMs (LLMs) have been educated based mostly on unlabeled knowledge (similar to free textual content) and are in a position to predict the following finest phrase or sequence of phrases (paragraphs or lengthy essays). Foremost use instances are round human-like chatbots, summarization, or different content material creation similar to programming code.
- Textual content-to-image – Labeled knowledge, similar to pairs of <textual content, picture>, has been used to coach FMs, that are in a position to predict one of the best mixture of pixels. Instance use instances are clothes design era or imaginary personalised photos.
- Textual content-to-audio or video – Each labeled and unlabeled knowledge can be utilized for FM coaching. One predominant generative AI use case instance is music composition.
To productionize these generative AI use instances, we have to borrow and prolong the MLOps area to incorporate the next:
- FM operations (FMOps) – This will productionize generative AI options, together with any use case kind
- LLM operations (LLMOps) – This can be a subset of FMOps specializing in productionizing LLM-based options, similar to text-to-text
The next determine illustrates the overlap of those use instances.
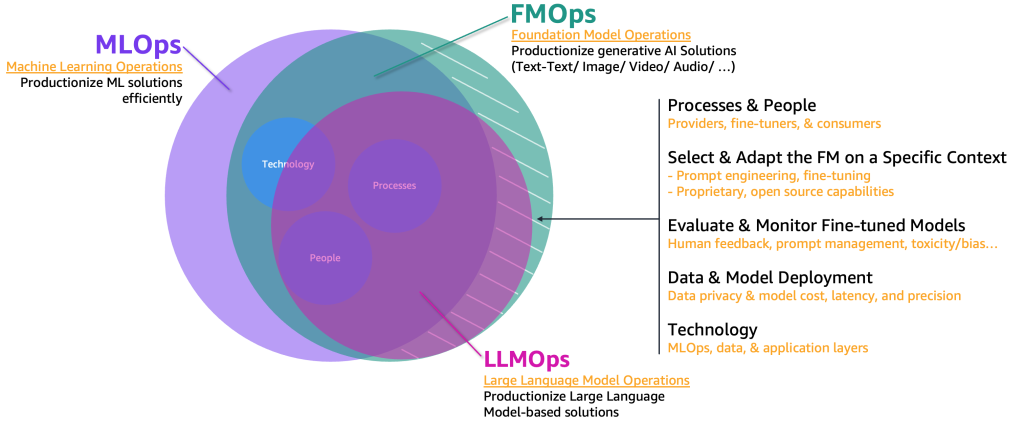
In comparison with basic ML and MLOps, FMOps and LLMOps defer based mostly on 4 predominant classes that we cowl within the following sections: folks and course of, choice and adaptation of FM, analysis and monitoring of FM, knowledge privateness and mannequin deployment, and know-how wants. We’ll cowl monitoring in a separate submit.
Operationalization journey per generative AI consumer kind
To simplify the outline of the processes, we have to categorize the principle generative AI consumer sorts, as proven within the following determine.
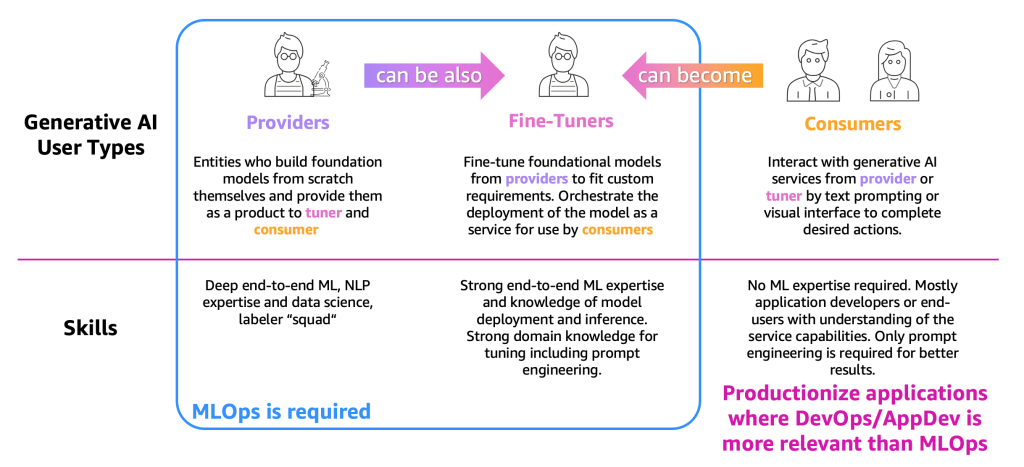
The consumer sorts are as follows:
- Suppliers – Customers who construct FMs from scratch and supply them as a product to different customers (fine-tuner and client). They’ve deep end-to-end ML and pure language processing (NLP) experience and knowledge science expertise, and large knowledge labeler and editor groups.
- Advantageous-tuners – Customers who retrain (fine-tune) FMs from suppliers to suit customized necessities. They orchestrate the deployment of the mannequin as a service to be used by customers. These customers want robust end-to-end ML and knowledge science experience and information of mannequin deployment and inference. Robust area information for tuning, together with immediate engineering, is required as effectively.
- Customers – Customers who work together with generative AI providers from suppliers or fine-tuners by textual content prompting or a visible interface to finish desired actions. No ML experience is required however, principally, software builders or end-users with understanding of the service capabilities. Solely immediate engineering is important for higher outcomes.
As per the definition and the required ML experience, MLOps is required principally for suppliers and fine-tuners, whereas customers can use software productionization rules, similar to DevOps and AppDev to create the generative AI purposes. Moreover, we’ve got noticed a motion among the many consumer sorts, the place suppliers would possibly turn into fine-tuners to help use instances based mostly on a particular vertical (such because the monetary sector) or customers would possibly turn into fine-tuners to realize extra correct outcomes. However let’s observe the principle processes per consumer kind.
The journey of customers
The next determine illustrates the buyer journey.
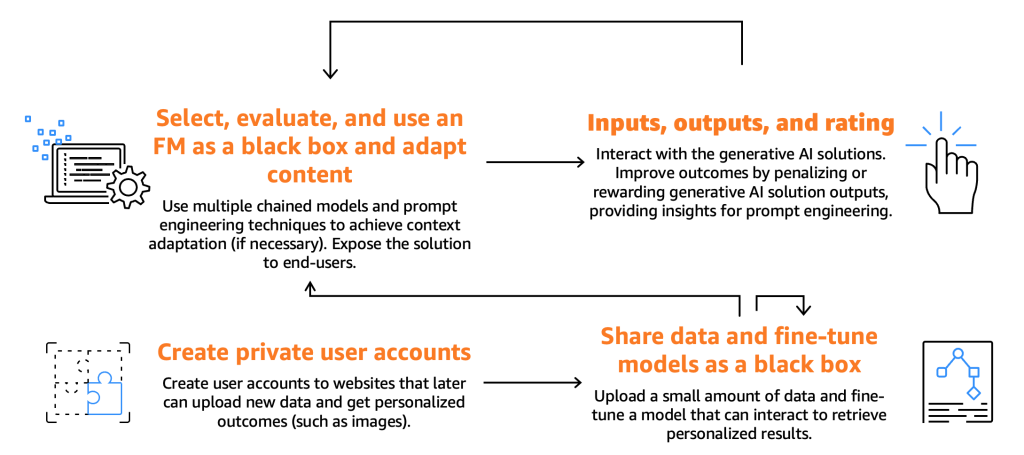
As beforehand talked about, customers are required to pick out, check, and use an FM, interacting with it by offering particular inputs, in any other case generally known as prompts. Prompts, within the context of laptop programming and AI, check with the enter that’s given to a mannequin or system to generate a response. This may be within the type of a textual content, command, or a query, which the system makes use of to course of and generate an output. The output generated by the FM can then be utilized by end-users, who also needs to be capable to charge these outputs to boost the mannequin’s future responses.
Past these basic processes, we’ve seen customers expressing a need to fine-tune a mannequin by harnessing the performance supplied by fine-tuners. Take, as an example, an internet site that generates photos. Right here, end-users can arrange non-public accounts, add private images, and subsequently generate content material associated to these photos (for instance, producing a picture depicting the end-user on a bike wielding a sword or positioned in an unique location). On this state of affairs, the generative AI software, designed by the buyer, should work together with the fine-tuner backend through APIs to ship this performance to the end-users.
Nonetheless, earlier than we delve into that, let’s first focus on the journey of mannequin choice, testing, utilization, enter and output interplay, and score, as proven within the following determine.
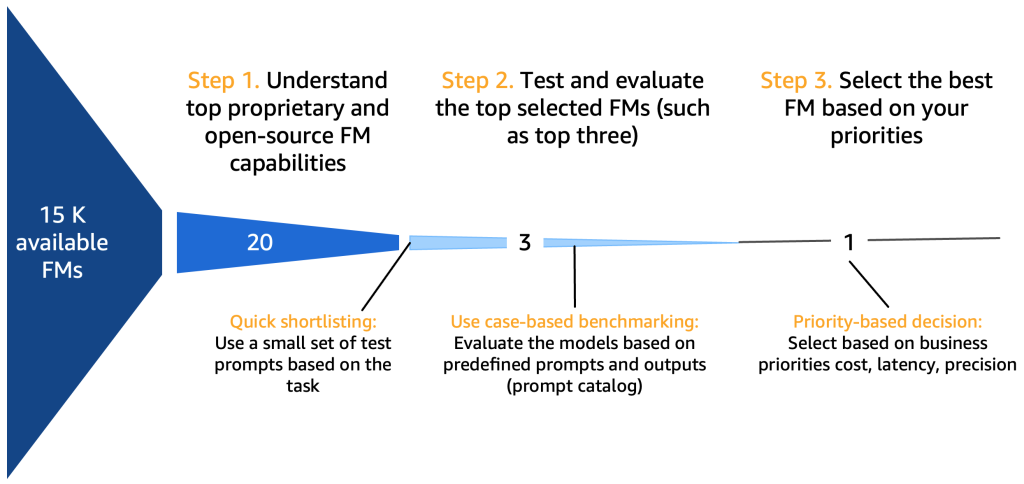
Step 1. Perceive prime FM capabilities
There are lots of dimensions that should be thought-about when choosing basis fashions, relying on the use case, the info out there, rules, and so forth. A very good guidelines, though not complete, may be the next:
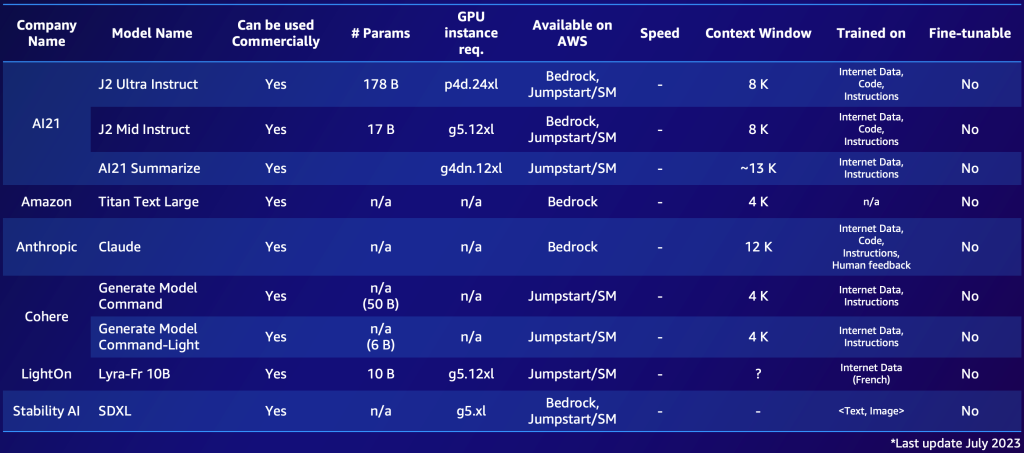
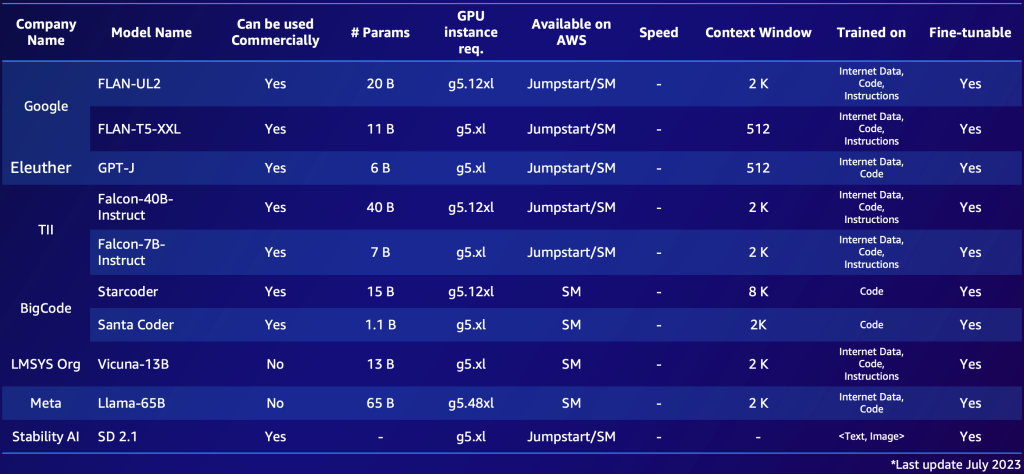
- Proprietary or open-source FM – Proprietary fashions usually come at a monetary value, however they sometimes provide higher efficiency (by way of high quality of the generated textual content or picture), usually being developed and maintained by devoted groups of mannequin suppliers who guarantee optimum efficiency and reliability. Alternatively, we additionally see adoption of open-source fashions that, aside from being free, provide further advantages of being accessible and versatile (for instance, each open-source mannequin is fine-tunable). An instance of a proprietary mannequin is Anthropic’s Claude mannequin, and an instance of a excessive performing open-source mannequin is Falcon-40B, as of July 2023.
- Business license – Licensing concerns are essential when deciding on an FM. It’s essential to notice that some fashions are open-source however can’t be used for industrial functions, resulting from licensing restrictions or situations. The variations will be delicate: The newly launched xgen-7b-8k-base mannequin, for instance, is open supply and commercially usable (Apache-2.0 license), whereas the instruction fine-tuned model of the mannequin xgen-7b-8k-inst is barely launched for analysis functions solely. When choosing an FM for a industrial software, it’s important to confirm the license settlement, perceive its limitations, and guarantee it aligns with the meant use of the mission.
- Parameters – The variety of parameters, which include the weights and biases within the neural community, is one other key issue. Extra parameters typically means a extra complicated and probably highly effective mannequin, as a result of it might seize extra intricate patterns and correlations within the knowledge. Nonetheless, the trade-off is that it requires extra computational sources and, due to this fact, prices extra to run. Moreover, we do see a pattern in the direction of smaller fashions, particularly within the open-source area (fashions starting from 7–40 billion) that carry out effectively, particularly, when fine-tuned.
- Pace – The pace of a mannequin is influenced by its dimension. Bigger fashions are likely to course of knowledge slower (larger latency) as a result of elevated computational complexity. Due to this fact, it’s essential to steadiness the necessity for a mannequin with excessive predictive energy (usually bigger fashions) with the sensible necessities for pace, particularly in purposes, like chat bots, that demand real-time or near-real-time responses.
- Context window dimension (variety of tokens) – The context window, outlined by the utmost variety of tokens that may be enter or output per immediate, is essential in figuring out how a lot context the mannequin can take into account at a time (a token roughly interprets to 0.75 phrases for English). Fashions with bigger context home windows can perceive and generate longer sequences of textual content, which will be helpful for duties involving longer conversations or paperwork.
- Coaching dataset – It’s additionally essential to grasp what sort of knowledge the FM was educated on. Some fashions could also be educated on various textual content datasets like web knowledge, coding scripts, directions, or human suggestions. Others may be educated on multimodal datasets, like combos of textual content and picture knowledge. This will affect the mannequin’s suitability for various duties. As well as, a company might need copyright issues relying on the precise sources a mannequin has been educated on—due to this fact, it’s necessary to examine the coaching dataset carefully.
- High quality – The standard of an FM can range based mostly on its kind (proprietary vs. open supply), dimension, and what it was educated on. High quality is context-dependent, that means what is taken into account high-quality for one software won’t be for one more. For instance, a mannequin educated on web knowledge may be thought-about top quality for producing conversational textual content, however much less so for technical or specialised duties.
- Advantageous-tunable – The flexibility to fine-tune an FM by adjusting its mannequin weights or layers is usually a essential issue. Advantageous-tuning permits for the mannequin to raised adapt to the precise context of the applying, bettering efficiency on the precise activity at hand. Nonetheless, fine-tuning requires further computational sources and technical experience, and never all fashions help this function. Open-source fashions are (generally) at all times fine-tunable as a result of the mannequin artifacts can be found for downloading and the customers are in a position to prolong and use them at will. Proprietary fashions would possibly generally provide the choice of fine-tuning.
- Current buyer expertise – The number of an FM will also be influenced by the abilities and familiarity of the shopper or the event crew. If a company has no AI/ML consultants of their crew, then an API service may be higher fitted to them. Additionally, if a crew has in depth expertise with a particular FM, it may be extra environment friendly to proceed utilizing it relatively than investing time and sources to study and adapt to a brand new one.
The next is an instance of two shortlists, one for proprietary fashions and one for open-source fashions. You would possibly compile related tables based mostly in your particular must get a fast overview of the out there choices. Notice that the efficiency and parameters of these fashions change quickly and may be outdated by the point of studying, whereas different capabilities may be essential for particular prospects, such because the supported language.
The next is an instance of notable proprietary FMs out there in AWS (July 2023).
The next is an instance of notable open-source FM out there in AWS (July 2023).
After you’ve compiled an outline of 10–20 potential candidate fashions, it turns into essential to additional refine this shortlist. On this part, we suggest a swift mechanism that can yield two or three viable closing fashions as candidates for the following spherical.
The next diagram illustrates the preliminary shortlisting course of.
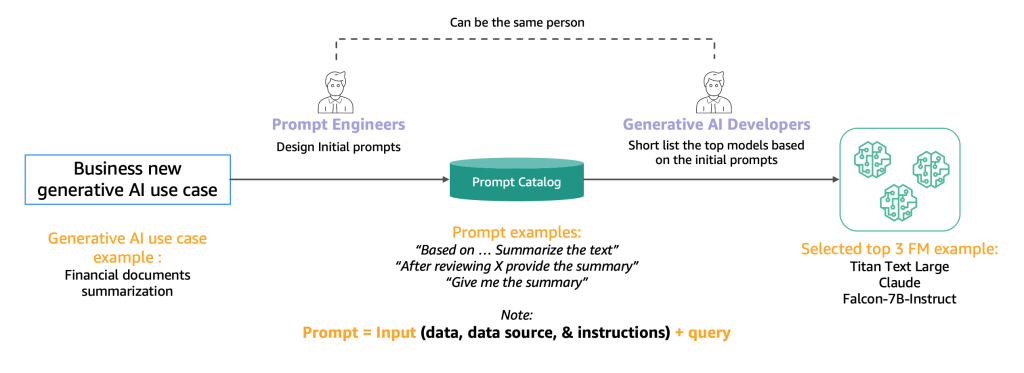
Sometimes, immediate engineers, who’re consultants in creating high-quality prompts that permit AI fashions to grasp and course of consumer inputs, experiment with numerous strategies to carry out the identical activity (similar to summarization) on a mannequin. We recommend that these prompts usually are not created on the fly, however are systematically extracted from a immediate catalog. This immediate catalog is a central location for storing prompts to keep away from replications, allow model management, and share prompts inside the crew to make sure consistency between totally different immediate testers within the totally different improvement phases, which we introduce within the subsequent part. This immediate catalog is analogous to a Git repository of a function retailer. The generative AI developer, who might probably be the identical individual because the immediate engineer, then wants to guage the output to find out if it might be appropriate for the generative AI software they’re searching for to develop.
Step 2. Check and consider the highest FM
After the shortlist is lowered to roughly three FMs, we suggest an analysis step to additional check the FMs’ capabilities and suitability for the use case. Relying on the supply and nature of analysis knowledge, we recommend totally different strategies, as illustrated within the following determine.
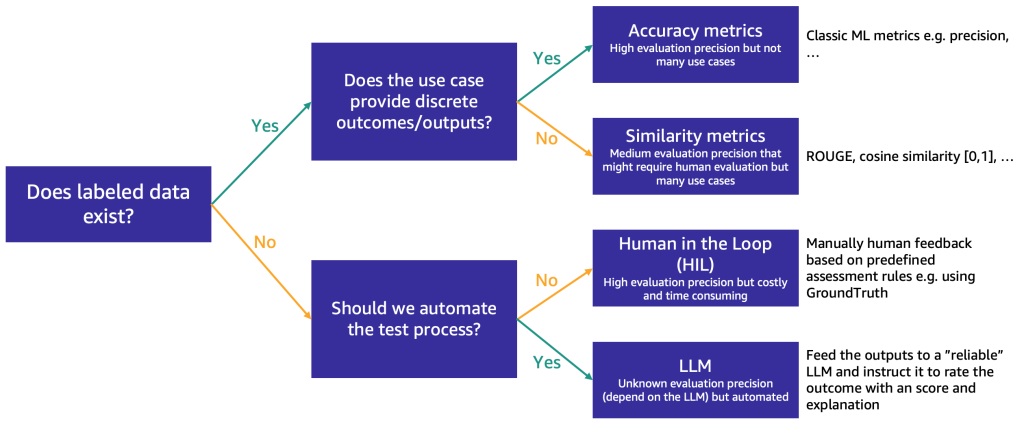
The tactic to make use of first is dependent upon whether or not you’ve labeled check knowledge or not.
In case you have labeled knowledge, you should use it to conduct a mannequin analysis, as we do with the normal ML fashions (enter some samples and examine the output with the labels). Relying on whether or not the check knowledge has discrete labels (similar to optimistic, damaging, or impartial sentiment evaluation) or is unstructured textual content (similar to summarization), we suggest totally different strategies for analysis:
- Accuracy metrics – In case of discrete outputs (similar to sentiment evaluation), we will use commonplace accuracy metrics similar to precision, recall, and F1 rating
- Similarity metrics – If the output is unstructured (similar to a abstract), we recommend similarity metrics like ROUGE and cosine similarity
Some use instances don’t lend themselves to having one true reply (for instance, “Create a brief youngsters’s story for my 5-year-old daughter”). In such instances, it turns into more difficult to guage the fashions since you don’t have labeled check knowledge. We suggest two approaches, relying on the significance of human assessment of the mannequin versus automated analysis:
- Human-in-the-Loop (HIL) – On this case, a crew of immediate testers will assessment the responses from a mannequin. Relying on how important the applying is, the immediate testers would possibly assessment 100% of the mannequin outputs or only a pattern.
- LLM-powered analysis – On this state of affairs, the immediate testers are changed by an LLM, ideally one that’s extra highly effective (though maybe slower and most expensive) than those being examined. The LLM will assessment all model-generated responses and rating them. This methodology could lead to decrease high quality, nevertheless it’s a less expensive and quicker analysis choice which may present an excellent preliminary gauge on the fashions’ efficiency.
For instance, we will use the next instance immediate to an LLM, which incorporates the enter question, the LLM response, and directions: “We want to request your suggestions on the efficiency of an AI assistant in response to the consumer query displayed above. Please charge the helpfulness, relevance, accuracy, stage of particulars of the assistant’s response. The assistant shall obtain an total rating on a scale of 1 to 10, the place a better rating signifies higher total efficiency.”
This immediate can be despatched to a different LLM (the EvalLLM) for analysis. The next is an instance the place the response of the Falcon-40B mannequin has been evaluated by an EvalLLM (on this case Claude). We use the query “What if the Suez Canal had by no means been constructed?” The response is as follows:
Query: What if the Suez Canal had by no means been constructed?
falcon-40b-instruct
If the Suez Canal had by no means been constructed, ships must journey round Africa to navigate between the Mediterranean and the Pink Sea. This could add vital time and distance to the voyage, making it much less environment friendly and costlier. Moreover, with out the Suez Canal, many international locations within the Center East and North Africa would have been a lot much less related to the remainder of the world, hindering financial and cultural improvement.
Evaluate (Rating: 9/10)
The assistant’s response is extremely related, correct, and detailed. It gives a superb reply to the consumer’s hypothetical query concerning the non-existence of the Suez Canal. The assistant accurately factors out the implications on maritime journey and the financial and cultural impression on the Center East and North Africa. Nonetheless, it might have additional elaborated on the geopolitical implications or the impression on world commerce patterns for a extra complete response.
The next determine illustrates the end-to-end analysis course of instance.
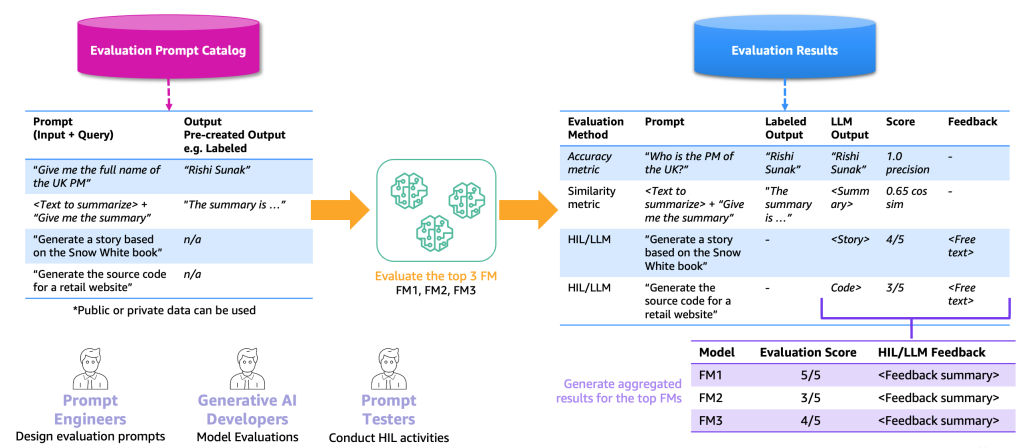
Based mostly on this instance, to carry out analysis, we have to present the instance prompts, which we retailer within the immediate catalog, and an analysis labeled or unlabeled dataset based mostly on our particular purposes. For instance, with a labeled analysis dataset, we will present prompts (enter and question) similar to “Give me the complete identify of the UK PM in 2023” and outputs and solutions, similar to “Rishi Sunak.” With an unlabeled dataset, we offer simply the query or instruction, similar to “Generate the supply code for a retail web site.” We name the mix of immediate catalog and analysis dataset the analysis immediate catalog. The explanation that we differentiate the immediate catalog and analysis immediate catalog is as a result of the latter is devoted to a particular use case as a substitute of generic prompts and directions (similar to query answering) that the immediate catalog accommodates.
With this analysis immediate catalog, the following step is to feed the analysis prompts to the highest FMs. The result’s an analysis outcome dataset that accommodates the prompts, outputs of every FM, and the labeled output along with a rating (if it exists). Within the case of an unlabeled analysis immediate catalog, there’s an extra step for an HIL or LLM to assessment the outcomes and supply a rating and suggestions (as we described earlier). The ultimate consequence can be aggregated outcomes that mix the scores of all of the outputs (calculate the typical precision or human score) and permit the customers to benchmark the standard of the fashions.
After the analysis outcomes have been collected, we suggest selecting a mannequin based mostly on a number of dimensions. These sometimes come right down to elements similar to precision, pace, and value. The next determine exhibits an instance.
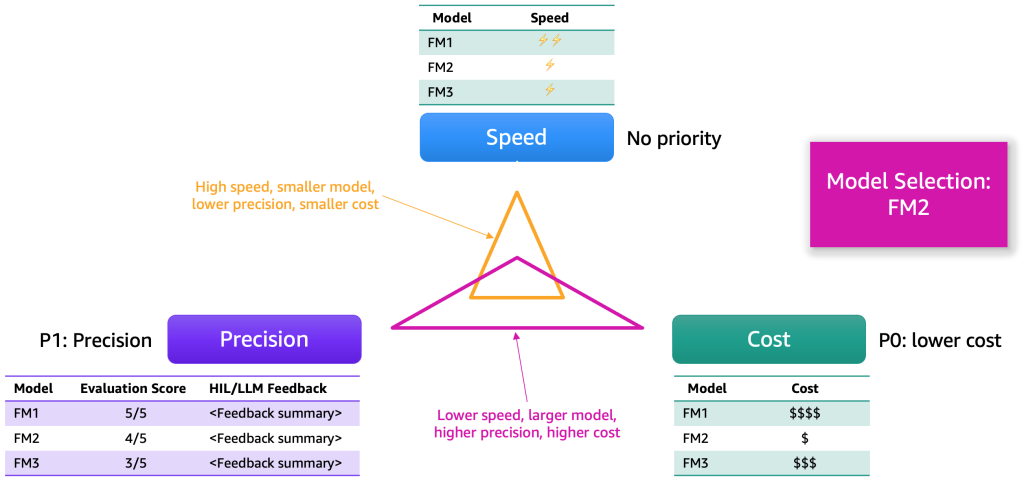
Every mannequin will possess strengths and sure trade-offs alongside these dimensions. Relying on the use case, we must always assign various priorities to those dimensions. Within the previous instance, we elected to prioritize value as an important issue, adopted by precision, after which pace. Regardless that it’s slower and never as environment friendly as FM1, it stays sufficiently efficient and considerably cheaper to host. Consequently, we would choose FM2 because the best choice.
Step 3. Develop the generative AI software backend and frontend
At this level, the generative AI builders have chosen the precise FM for the precise software along with the assistance of immediate engineers and testers. The subsequent step is to start out growing the generative AI software. We’ve got separated the event of the generative AI software into two layers, a backend and entrance finish, as proven within the following determine.
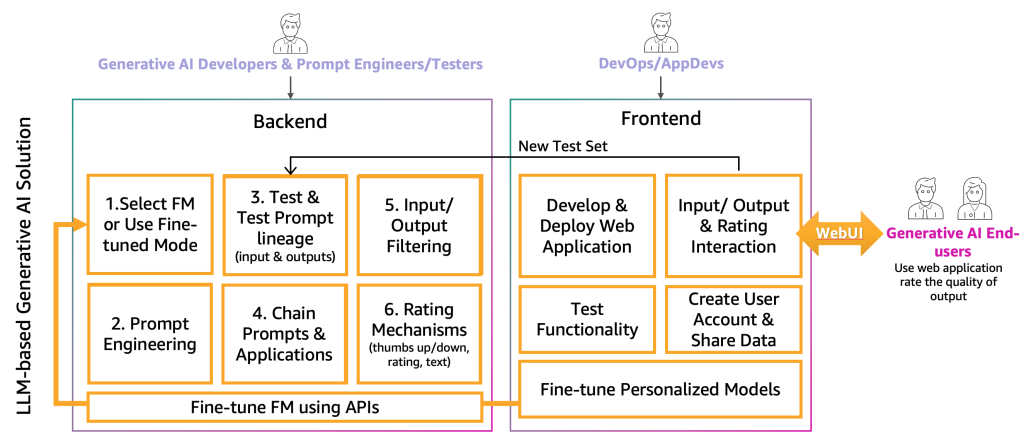
On the backend, the generative AI builders incorporate the chosen FM into the options and work along with the immediate engineers to create the automation to remodel the end-user enter to applicable FM prompts. The immediate testers create the mandatory entries to the immediate catalog for computerized or handbook (HIL or LLM) testing. Then, the generative AI builders create the immediate chaining and software mechanism to offer the ultimate output. Immediate chaining, on this context, is a way to create extra dynamic and contextually-aware LLM purposes. It really works by breaking down a fancy activity right into a sequence of smaller, extra manageable sub-tasks. For instance, if we ask an LLM the query “The place was the prime minister of the UK born and the way far is that place from London,” the duty will be damaged down into particular person prompts, the place a immediate may be constructed based mostly on the reply of a earlier immediate analysis, similar to “Who’s the prime minister of the UK,” “What’s their birthplace,” and “How far is that place from London?” To make sure a sure enter and output high quality, the generative AI builders additionally must create the mechanism to observe and filter the end-user inputs and software outputs. If, for instance, the LLM software is meant to keep away from poisonous requests and responses, they may apply a toxicity detector for enter and output and filter these out. Lastly, they should present a score mechanism, which is able to help the augmentation of the analysis immediate catalog with good and dangerous examples. A extra detailed illustration of these mechanisms can be offered in future posts.
To offer the performance to the generative AI end-user, the event of a frontend web site that interacts with the backend is important. Due to this fact, DevOps and AppDevs (software builders on the cloud) personas must observe finest improvement practices to implement the performance of enter/output and score.
Along with this fundamental performance, the frontend and backend want to include the function of making private consumer accounts, importing knowledge, initiating fine-tuning as a black field, and utilizing the personalised mannequin as a substitute of the fundamental FM. The productionization of a generative AI software is analogous with a standard software. The next determine depicts an instance structure.
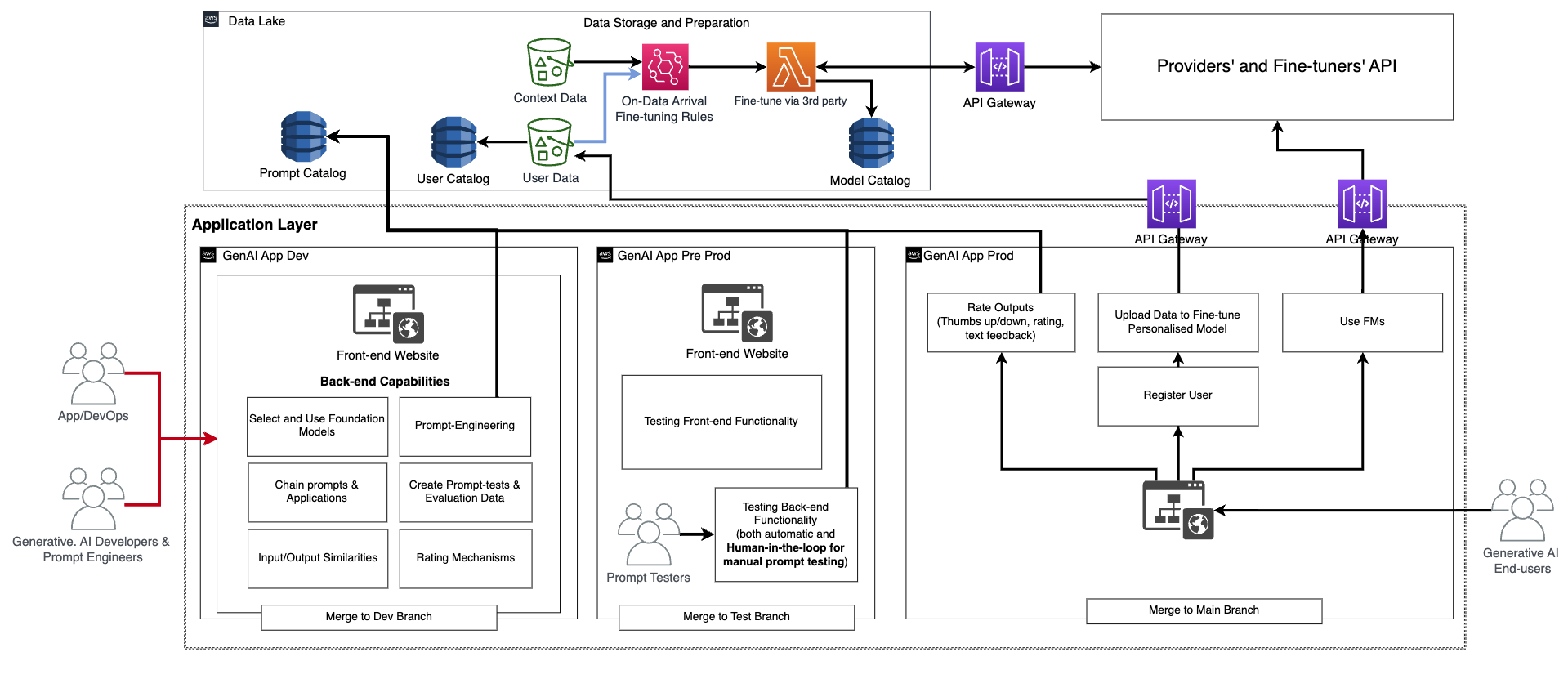
On this structure, the generative AI builders, immediate engineers, and DevOps or AppDevs create and check the applying manually by deploying it through CI/CD to a improvement setting (generative AI App Dev within the previous determine) utilizing devoted code repositories and merging with the dev department. At this stage, the generative AI builders will use the corresponding FM by calling the API as has been supplied by the FM suppliers of fine-tuners. Then, to check the applying extensively, they should promote the code to the check department, which is able to set off the deployment through CI/CD to the preproduction setting (generative AI App Pre-prod). At this setting, the immediate testers must strive a considerable amount of immediate combos and assessment the outcomes. The mixture of prompts, outputs, and assessment should be moved to the analysis immediate catalog to automate the testing course of sooner or later. After this in depth check, the final step is to advertise the generative AI software to manufacturing through CI/CD by merging with the principle department (generative AI App Prod). Notice that each one the info, together with the immediate catalog, analysis knowledge and outcomes, end-user knowledge and metadata, and fine-tuned mannequin metadata, should be saved within the knowledge lake or knowledge mesh layer. The CI/CD pipelines and repositories should be saved in a separate tooling account (just like the one described for MLOps).
The journey of suppliers
FM suppliers want to coach FMs, similar to deep studying fashions. For them, the end-to-end MLOps lifecycle and infrastructure is important. Additions are required in historic knowledge preparation, mannequin analysis, and monitoring. The next determine illustrates their journey.
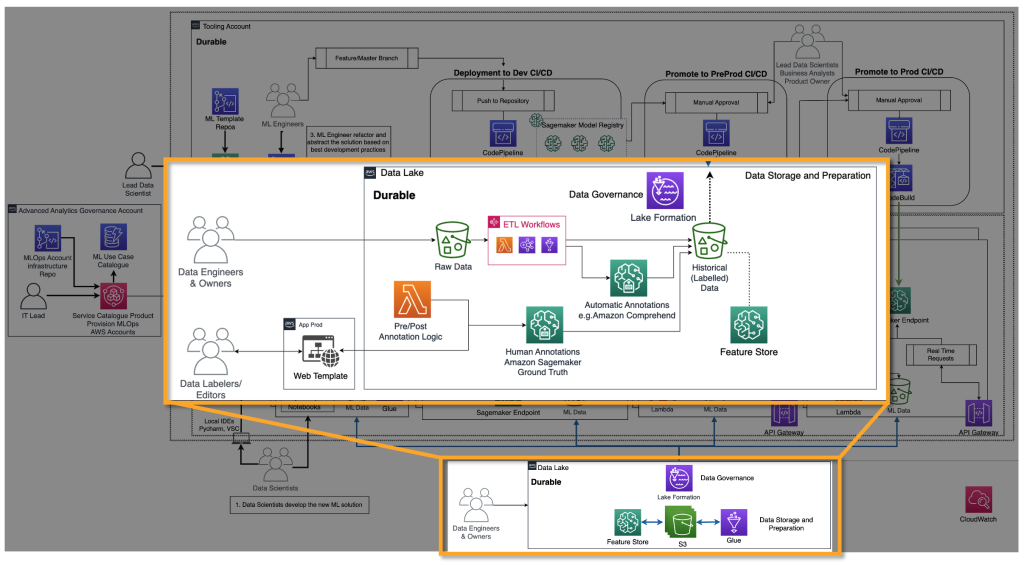
In basic ML, the historic knowledge is most frequently created by feeding the bottom fact through ETL pipelines. For instance, in a churn prediction use case, an automation updates a database desk based mostly on the brand new standing of a buyer to churn/not churn robotically. Within the case of FMs, they want both billions of labeled or unlabeled knowledge factors. In text-to-image use instances, a crew of knowledge labelers must label <textual content, picture> pairs manually. That is an costly train requiring a lot of folks sources. Amazon SageMaker Ground Truth Plus can present a crew of labelers to carry out this exercise for you. For some use instances, this course of will be additionally partially automated, for instance by utilizing CLIP-like fashions. Within the case of an LLM, similar to text-to-text, the info is unlabeled. Nonetheless, they should be ready and observe the format of the prevailing historic unlabeled knowledge. Due to this fact, knowledge editors are wanted to carry out vital knowledge preparation and guarantee consistency.
With the historic knowledge ready, the following step is the coaching and productionization of the mannequin. Notice that the identical analysis methods as we described for customers can be utilized.
The journey of fine-tuners
Advantageous-tuners purpose to adapt an present FM to their particular context. For instance, an FM mannequin can summarize a general-purpose textual content however not a monetary report precisely or can’t generate supply code for a non-common programming language. In these instances, the fine-tuners must label knowledge, fine-tune a mannequin by operating a coaching job, deploy the mannequin, check it based mostly on the buyer processes, and monitor the mannequin. The next diagram illustrates this course of.
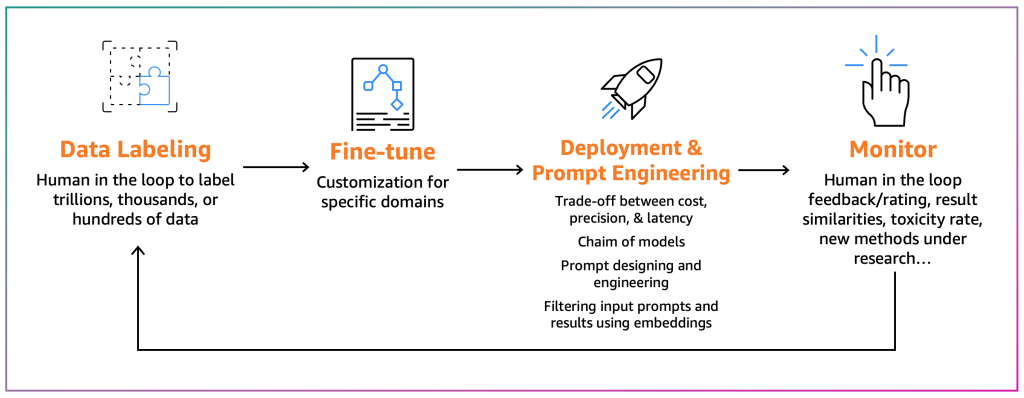
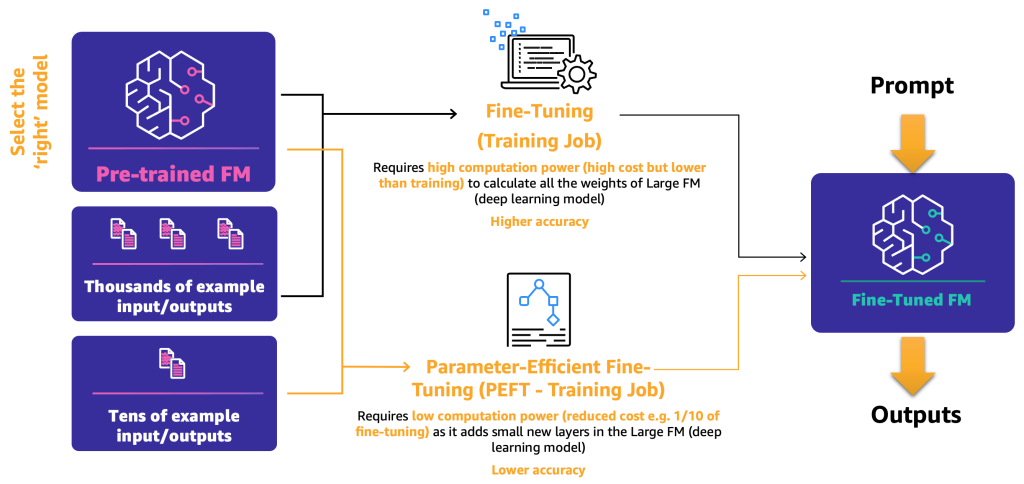
In the meanwhile, there are two fine-tuning mechanisms:
- Advantageous-tuning – By utilizing an FM and labeled knowledge, a coaching job recalculates the weights and biases of the deep studying mannequin layers. This course of will be computationally intensive and requires a consultant quantity of knowledge however can generate correct outcomes.
- Parameter-efficient fine-tuning (PEFT) – As an alternative of recalculating all of the weights and biases, researchers have proven that by including further small layers to the deep studying fashions, they’ll obtain passable outcomes (for instance, LoRA). PEFT requires decrease computational energy than deep fine-tuning and a coaching job with much less enter knowledge. The downside is potential decrease accuracy.
The next diagram illustrates these mechanisms.
Now that we’ve got outlined the 2 predominant fine-tuning strategies, the following step is to find out how we will deploy and use the open-source and proprietary FM.
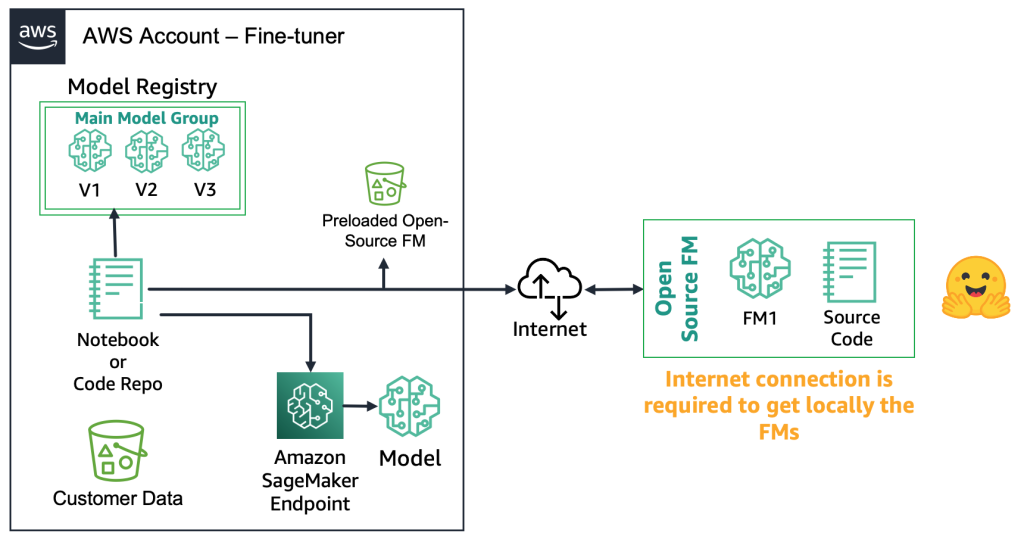
With open-source FMs, the fine-tuners can obtain the mannequin artifact and the supply code from the online, for instance, by utilizing the Hugging Face Model Hub. This offers you the flexibleness to deep fine-tune the mannequin, retailer it to a neighborhood mannequin registry, and deploy it to an Amazon SageMaker endpoint. This course of requires an web connection. To help safer environments (similar to for patrons within the monetary sector), you possibly can obtain the mannequin on premises, run all the mandatory safety checks, and add them to a neighborhood bucket on an AWS account. Then, the fine-tuners use the FM from the native bucket with out an web connection. This ensures knowledge privateness, and the info doesn’t journey over the web. The next diagram illustrates this methodology.
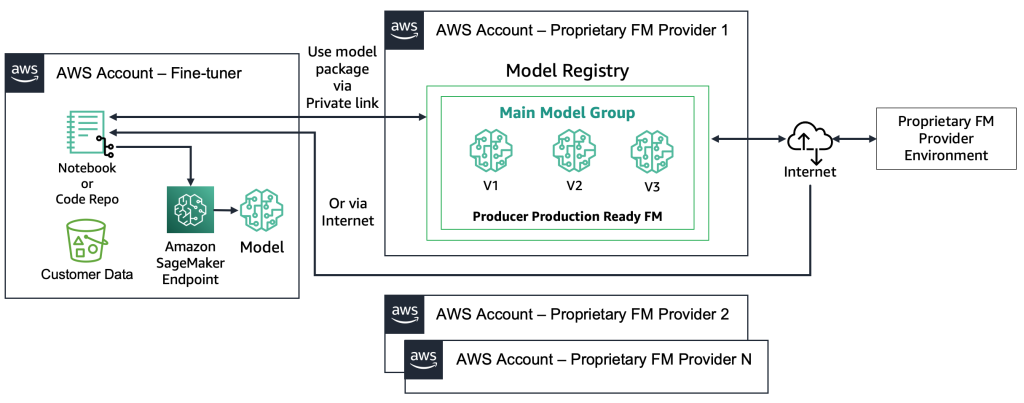
With proprietary FMs, the deployment course of is totally different as a result of the fine-tuners don’t have entry to the mannequin artifact or supply code. The fashions are saved in proprietary FM supplier AWS accounts and mannequin registries. To deploy such a mannequin to a SageMaker endpoint, the fine-tuners can request solely the mannequin bundle that can be deployed on to an endpoint. This course of requires buyer knowledge for use within the proprietary FM suppliers’ accounts, which raises questions concerning customer-sensitive knowledge being utilized in a distant account to carry out fine-tuning, and fashions being hosted in a mannequin registry that’s shared amongst a number of prospects. This results in a multi-tenancy downside that turns into more difficult if the proprietary FM suppliers must serve these fashions. If the fine-tuners use Amazon Bedrock, these challenges are resolved—the info doesn’t journey over the web and the FM suppliers don’t have entry to fine-tuners’ knowledge. The identical challenges maintain for the open-source fashions if the fine-tuners wish to serve fashions from a number of prospects, similar to the instance we gave earlier with the web site that 1000’s of consumers will add personalised photos to. Nonetheless, these eventualities will be thought-about controllable as a result of solely the fine-tuner is concerned. The next diagram illustrates this methodology.
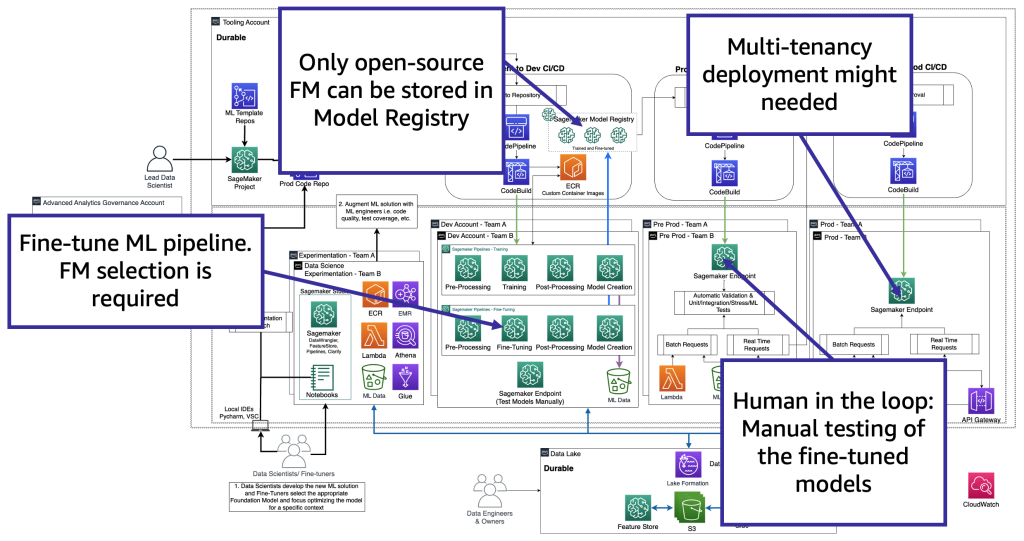
From a know-how perspective, the structure {that a} fine-tuner must help is just like the one for MLOps (see the next determine). The fine-tuning must be carried out in dev by creating ML pipelines, similar to utilizing Amazon SageMaker Pipelines; performing preprocessing, fine-tuning (coaching job), and postprocessing; and sending the fine-tuned fashions to a neighborhood mannequin registry within the case of an open-source FM (in any other case, the brand new mannequin can be saved to the proprietary FM present setting). Then, in pre-production, we have to check the mannequin as we describe for the customers’ state of affairs. Lastly, the mannequin can be served and monitored in prod. Notice that the present (fine-tuned) FM requires GPU occasion endpoints. If we have to deploy every fine-tuned mannequin to a separate endpoint, this would possibly improve the price within the case of a whole bunch of fashions. Due to this fact, we have to use multi-model endpoints and resolve the multi-tenancy problem.
The fine-tuners adapt an FM mannequin based mostly on a particular context to make use of it for his or her enterprise objective. That signifies that more often than not, the fine-tuners are additionally customers required to help all of the layers, as we described within the earlier sections, together with generative AI software improvement, knowledge lake and knowledge mesh, and MLOps.
The next determine illustrates the entire FM fine-tuning lifecycle that the fine-tuners want to offer the generative AI end-user.
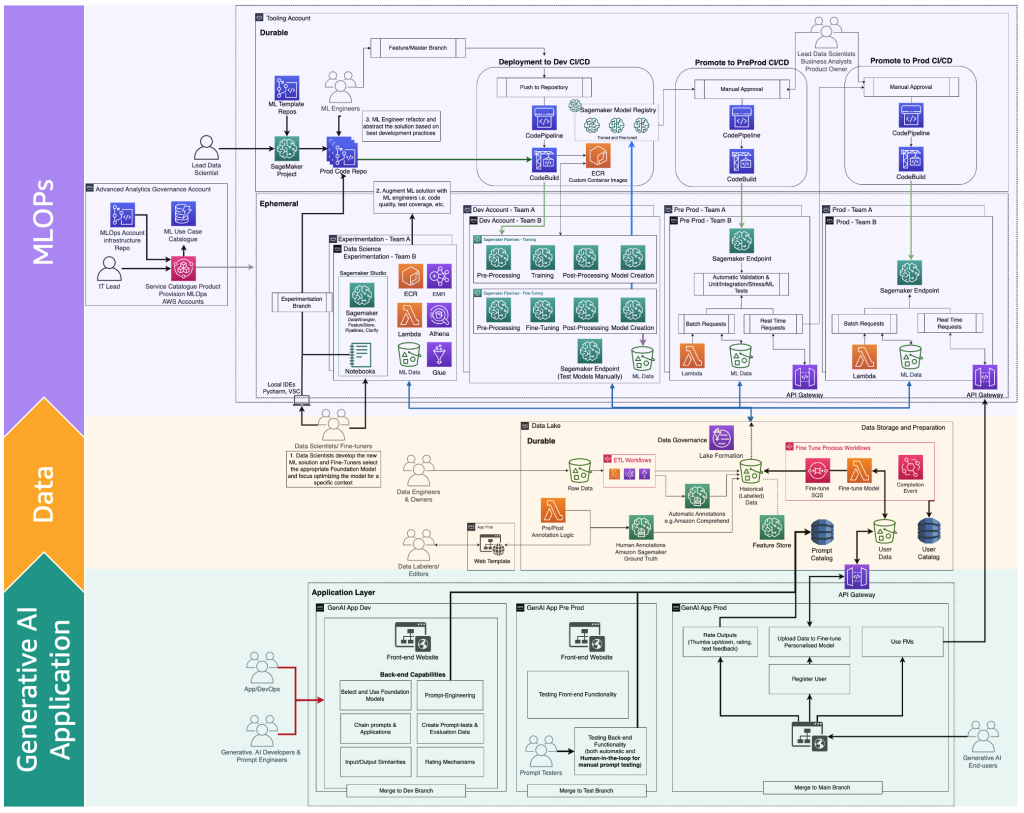
The next determine illustrates the important thing steps.
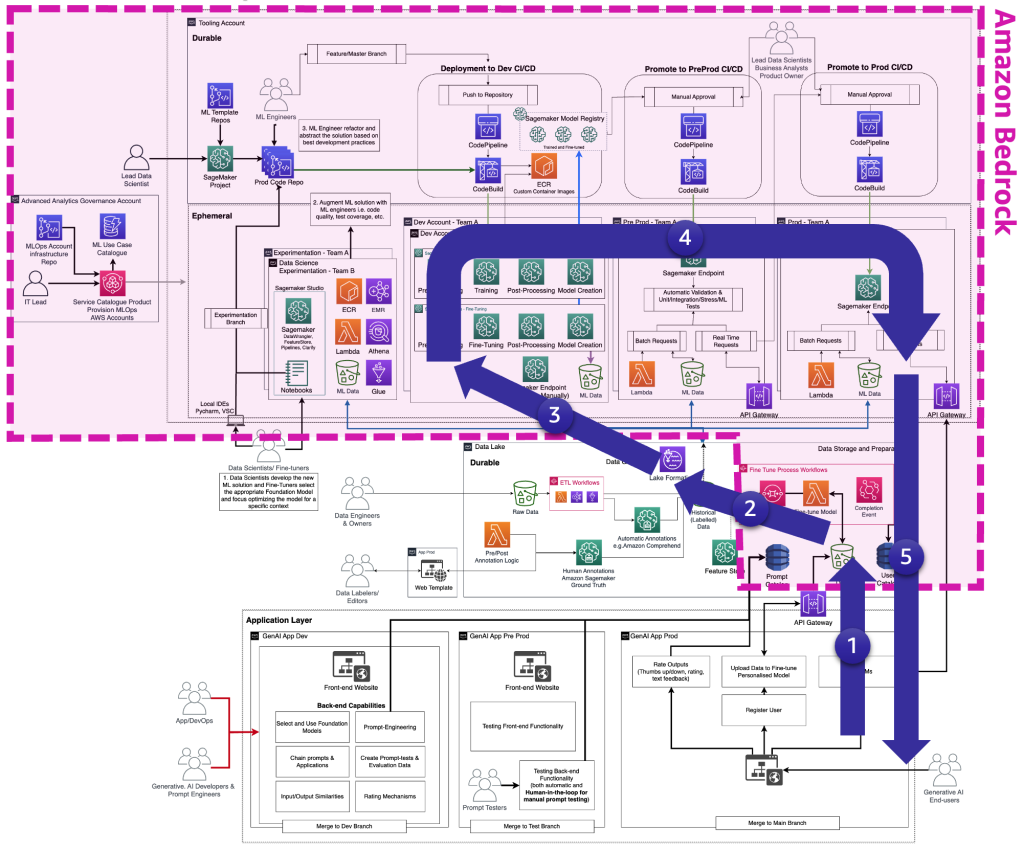
The important thing steps are the next:
- The top-user creates a private account and uploads non-public knowledge.
- The information is saved within the knowledge lake and is preprocessed to observe the format that the FM expects.
- This triggers a fine-tuning ML pipeline that provides the mannequin to the mannequin registry,
- From there, both the mannequin is deployed to manufacturing with minimal testing or the mannequin pushes in depth testing with HIL and handbook approval gates.
- The fine-tuned mannequin is made out there for end-users.
As a result of this infrastructure is complicated for non-enterprise prospects, AWS launched Amazon Bedrock to dump the hassle of making such architectures and bringing fine-tuned FMs nearer to manufacturing.
FMOps and LLMOps personas and processes differentiators
Based mostly on the previous consumer kind journeys (client, producer, and fine-tuner), new personas with particular expertise are required, as illustrated within the following determine.
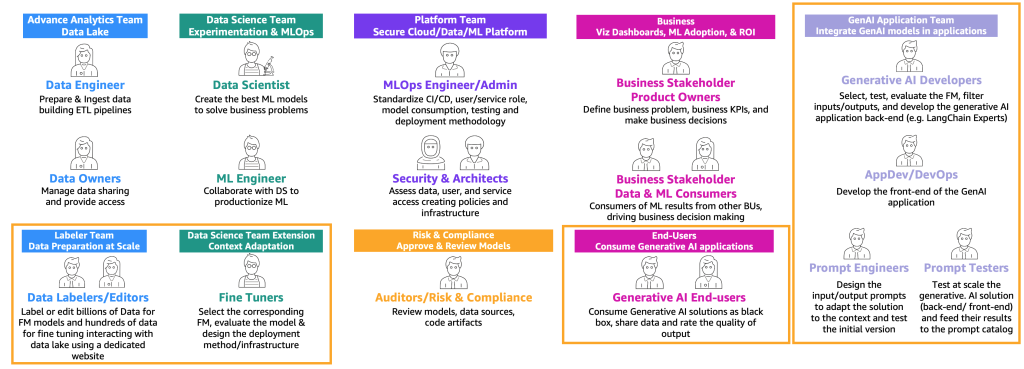
The brand new personas are as follows:
- Knowledge labelers and editors – These customers label knowledge, similar to <textual content, picture> pairs, or put together unlabeled knowledge, similar to free textual content, and prolong the superior analytics crew and knowledge lake environments.
- Advantageous-tuners – These customers have deep information on FMs and know to tune them, extending the info science crew that can give attention to basic ML.
- Generative AI builders – They’ve deep information on choosing FMs, chaining prompts and purposes, and filtering enter and outputs. They belong a brand new crew—the generative AI software crew.
- Immediate engineers – These customers design the enter and output prompts to adapt the answer to the context and check and create the preliminary model of immediate catalog. Their crew is the generative AI software crew.
- Immediate testers – They check at scale the generative AI answer (backend and frontend) and feed their outcomes to reinforce the immediate catalog and analysis dataset. Their crew is the generative AI software crew.
- AppDev and DevOps – They develop the entrance finish (similar to an internet site) of the generative AI software. Their crew is the generative AI software crew.
- Generative AI end-users – These customers eat generative AI purposes as black bins, share knowledge, and charge the standard of the output.
The prolonged model of the MLOps course of map to include generative AI will be illustrated with the next determine.
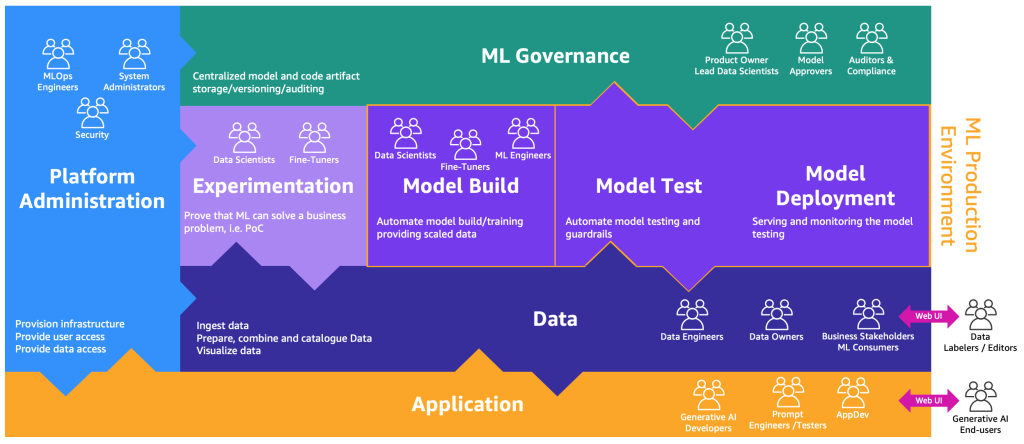
A brand new software layer is the setting the place generative AI builders, immediate engineers, and testers, and AppDevs created the backend and entrance finish of generative AI purposes. The generative AI end-users work together with the generative AI purposes entrance finish through the web (similar to an internet UI). On the opposite facet, knowledge labelers and editors must preprocess the info with out accessing the backend of the info lake or knowledge mesh. Due to this fact, an internet UI (web site) with an editor is important for interacting securely with the info. SageMaker Floor Reality gives this performance out of the field.
Conclusion
MLOps can assist us productionize ML fashions effectively. Nonetheless, to operationalize generative AI purposes, you want further expertise, processes, and applied sciences, resulting in FMOps and LLMOps. On this submit, we outlined the principle ideas of FMOps and LLMOps and described the important thing differentiators in comparison with MLOps capabilities by way of folks, processes, know-how, FM mannequin choice, and analysis. Moreover, we illustrated the thought technique of a generative AI developer and the event lifecycle of a generative AI software.
Sooner or later, we are going to give attention to offering options per the area we mentioned, and can present extra particulars on learn how to combine FM monitoring (similar to toxicity, bias, and hallucination) and third-party or non-public knowledge supply architectural patterns, similar to Retrieval Augmented Era (RAG), into FMOps/LLMOps.
To study extra, check with MLOps foundation roadmap for enterprises with Amazon SageMaker and check out the end-to-end answer in Implementing MLOps practices with Amazon SageMaker JumpStart pre-trained models.
In case you have any feedback or questions, please depart them within the feedback part.
In regards to the Authors
 Dr. Sokratis Kartakis is a Senior Machine Studying and Operations Specialist Options Architect for Amazon Internet Companies. Sokratis focuses on enabling enterprise prospects to industrialize their Machine Studying (ML) options by exploiting AWS providers and shaping their working mannequin, i.e. MLOps basis, and transformation roadmap leveraging finest improvement practices. He has spent 15+ years on inventing, designing, main, and implementing modern end-to-end production-level ML and Web of Issues (IoT) options within the domains of power, retail, well being, finance/banking, motorsports and many others. Sokratis likes to spend his spare time with household and mates, or using motorbikes.
Dr. Sokratis Kartakis is a Senior Machine Studying and Operations Specialist Options Architect for Amazon Internet Companies. Sokratis focuses on enabling enterprise prospects to industrialize their Machine Studying (ML) options by exploiting AWS providers and shaping their working mannequin, i.e. MLOps basis, and transformation roadmap leveraging finest improvement practices. He has spent 15+ years on inventing, designing, main, and implementing modern end-to-end production-level ML and Web of Issues (IoT) options within the domains of power, retail, well being, finance/banking, motorsports and many others. Sokratis likes to spend his spare time with household and mates, or using motorbikes.
 Heiko Hotz is a Senior Options Architect for AI & Machine Studying with a particular give attention to pure language processing, massive language fashions, and generative AI. Previous to this function, he was the Head of Knowledge Science for Amazon’s EU Buyer Service. Heiko helps our prospects achieve success of their AI/ML journey on AWS and has labored with organizations in lots of industries, together with insurance coverage, monetary providers, media and leisure, healthcare, utilities, and manufacturing. In his spare time, Heiko travels as a lot as attainable.
Heiko Hotz is a Senior Options Architect for AI & Machine Studying with a particular give attention to pure language processing, massive language fashions, and generative AI. Previous to this function, he was the Head of Knowledge Science for Amazon’s EU Buyer Service. Heiko helps our prospects achieve success of their AI/ML journey on AWS and has labored with organizations in lots of industries, together with insurance coverage, monetary providers, media and leisure, healthcare, utilities, and manufacturing. In his spare time, Heiko travels as a lot as attainable.

