
The rise in on-line social actions resembling social networking or on-line gaming is commonly riddled with hostile or aggressive conduct that may result in unsolicited manifestations of hate speech, cyberbullying, or harassment. For instance, many on-line gaming communities supply voice chat performance to facilitate communication amongst their customers. Though voice chat typically helps pleasant banter and trash speaking, it may well additionally result in issues resembling hate speech, cyberbullying, harassment, and scams. Flagging dangerous language helps organizations hold conversations civil and keep a protected and inclusive on-line atmosphere for customers to create, share, and take part freely. In the present day, many corporations rely solely on human moderators to assessment poisonous content material. Nevertheless, scaling human moderators to satisfy these wants at a enough high quality and velocity is pricey. Because of this, many organizations danger dealing with excessive person attrition charges, reputational injury, and regulatory fines. As well as, moderators are sometimes psychologically impacted by reviewing the poisonous content material.
Amazon Transcribe is an automated speech recognition (ASR) service that makes it straightforward for builders so as to add speech-to-text functionality to their purposes. In the present day, we’re excited to announce Amazon Transcribe Toxicity Detection, a machine studying (ML)-powered functionality that makes use of each audio and text-based cues to establish and classify voice-based poisonous content material throughout seven classes, together with sexual harassment, hate speech, threats, abuse, profanity, insults, and graphic language. Along with textual content, Toxicity Detection makes use of speech cues resembling tones and pitch to hone in on poisonous intent in speech.
That is an enchancment from customary content material moderation programs which might be designed to focus solely on particular phrases, with out accounting for intention. Most enterprises have an SLA of seven–15 days to assessment content material reported by customers as a result of moderators should hearken to prolonged audio information to judge if and when the dialog grew to become poisonous. With Amazon Transcribe Toxicity Detection, moderators solely assessment the particular portion of the audio file flagged for poisonous content material (vs. the complete audio file). The content material human moderators should assessment is diminished by 95%, enabling prospects to scale back their SLA to only a few hours, in addition to allow them to proactively average extra content material past simply what’s flagged by the customers. It should enable enterprises to robotically detect and average content material at scale, present a protected and inclusive on-line atmosphere, and take motion earlier than it may well trigger person churn or reputational injury. The fashions used for poisonous content material detection are maintained by Amazon Transcribe and up to date periodically to take care of accuracy and relevance.
On this put up, you’ll discover ways to:
- Determine dangerous content material in speech with Amazon Transcribe Toxicity Detection
- Use the Amazon Transcribe console for toxicity detection
- Create a transcription job with toxicity detection utilizing the AWS Command Line Interface (AWS CLI) and Python SDK
- Use the Amazon Transcribe toxicity detection API response
Detect toxicity in audio chat with Amazon Transcribe Toxicity Detection
Amazon Transcribe now gives a easy, ML-based resolution for flagging dangerous language in spoken conversations. This characteristic is very helpful for social media, gaming, and basic wants, eliminating the necessity for purchasers to offer their very own information to coach the ML mannequin. Toxicity Detection classifies poisonous audio content material into the next seven classes and gives a confidence rating (0–1) for every class:
- Profanity – Speech that comprises phrases, phrases, or acronyms which might be rude, vulgar, or offensive.
- Hate speech – Speech that criticizes, insults, denounces, or dehumanizes an individual or group on the idea of an id (resembling race, ethnicity, gender, faith, sexual orientation, skill, and nationwide origin).
- Sexual – Speech that signifies sexual curiosity, exercise, or arousal utilizing direct or oblique references to physique elements, bodily traits, or intercourse.
- Insults – Speech that features demeaning, humiliating, mocking, insulting, or belittling language. Any such language can be labeled as bullying.
- Violence or risk – Speech that features threats in search of to inflict ache, harm, or hostility towards an individual or group.
- Graphic – Speech that makes use of visually descriptive and unpleasantly vivid imagery. Any such language is commonly deliberately verbose to amplify a recipient’s discomfort.
- Harassment or abusive – Speech meant to affect the psychological well-being of the recipient, together with demeaning and objectifying phrases.
You may entry Toxicity Detection both through the Amazon Transcribe console or by calling the APIs instantly utilizing the AWS CLI or the AWS SDKs. On the Amazon Transcribe console, you may add the audio information you need to check for toxicity and get leads to only a few clicks. Amazon Transcribe will establish and categorize poisonous content material, resembling harassment, hate speech, sexual content material, violence, insults, and profanity. Amazon Transcribe additionally gives a confidence rating for every class, offering precious insights into the content material’s toxicity degree. Toxicity Detection is presently obtainable in the usual Amazon Transcribe API for batch processing and helps US English language.
Amazon Transcribe console walkthrough
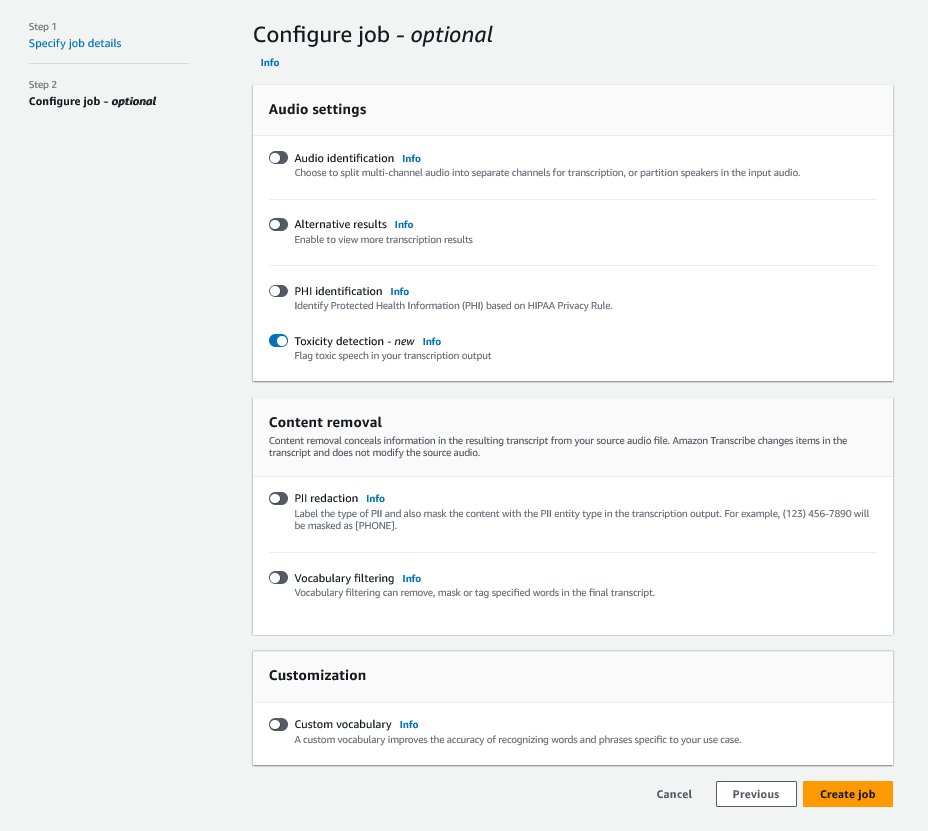
To get began, sign up to the AWS Management Console and go to Amazon Transcribe. To create a brand new transcription job, you must add your recorded information into an Amazon Simple Storage Service (Amazon S3) bucket earlier than they are often processed. On the audio settings web page, as proven within the following screenshot, allow Toxicity detection and proceed to create the brand new job. Amazon Transcribe will course of the transcription job within the background. Because the job progresses, you may count on the standing to vary to COMPLETED when the method is completed.
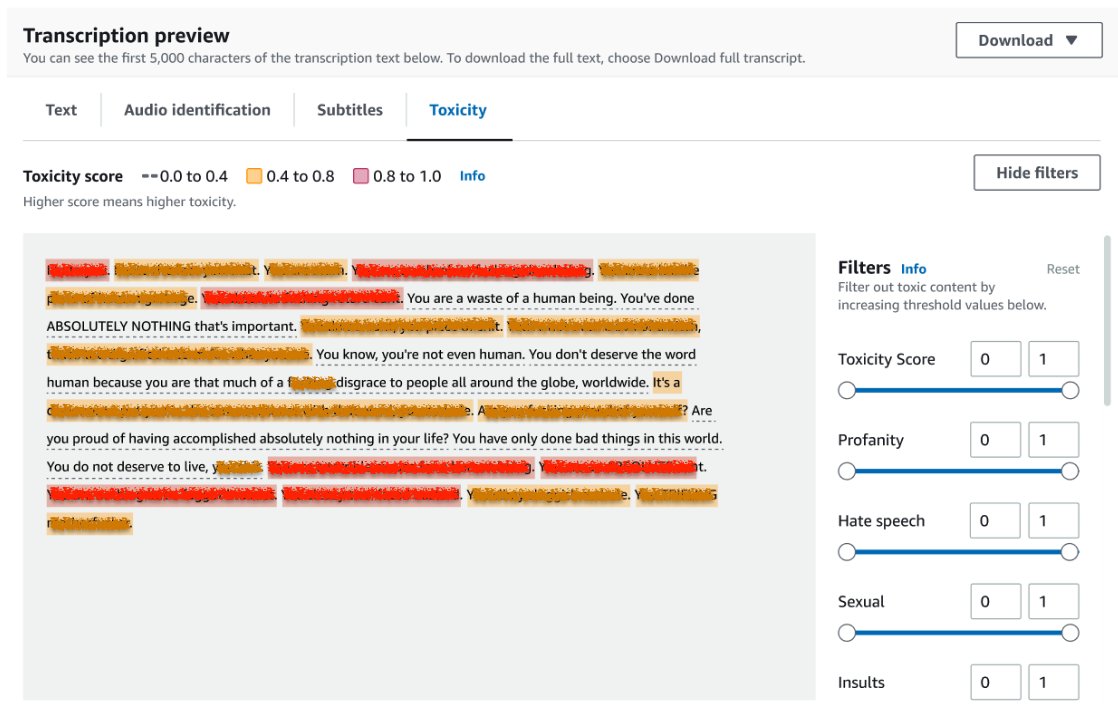
To assessment the outcomes of a transcription job, select the job from the job checklist to open it. Scroll right down to the Transcription preview part to test outcomes on the Toxicity tab. The UI reveals color-coded transcription segments to point the extent of toxicity, decided by the arrogance rating. To customise the show, you need to use the toggle bars within the Filters pane. These bars permit you to modify the thresholds and filter the toxicity classes accordingly.
The next screenshot has coated parts of the transcription textual content as a result of presence of delicate or poisonous info.
Transcription API with a toxicity detection request
On this part, we information you thru making a transcription job with toxicity detection utilizing programming interfaces. If the audio file shouldn’t be already in an S3 bucket, add it to make sure entry by Amazon Transcribe. Much like making a transcription job on the console, when invoking the job, you must present the next parameters:
- TranscriptionJobName – Specify a singular job identify.
- MediaFileUri – Enter the URI location of the audio file on Amazon S3. Amazon Transcribe helps the next audio codecs: MP3, MP4, WAV, FLAC, AMR, OGG, or WebM
- LanguageCode – Set to
en-US. As of this writing, Toxicity Detection solely helps US English language. - ToxicityCategories – Go the
ALLworth to incorporate all supported toxicity detection classes.
The next are examples of beginning a transcription job with toxicity detection enabled utilizing Python3:
You may invoke the identical transcription job with toxicity detection utilizing the next AWS CLI command:
Transcription API with toxicity detection response
The Amazon Transcribe toxicity detection JSON output will embody the transcription leads to the outcomes subject. Enabling toxicity detection provides an additional subject referred to as toxicityDetection beneath the outcomes subject. toxicityDetection features a checklist of transcribed objects with the next parameters:
- textual content – The uncooked transcribed textual content
- toxicity – A confidence rating of detection (a price between 0–1)
- classes – A confidence rating for every class of poisonous speech
- start_time – The beginning place of detection within the audio file (seconds)
- end_time – The top place of detection within the audio file (seconds)
The next is a pattern abbreviated toxicity detection response you may obtain from the console:
Abstract
On this put up, we supplied an outline of the brand new Amazon Transcribe Toxicity Detection characteristic. We additionally described how one can parse the toxicity detection JSON output. For extra info, take a look at the Amazon Transcribe console and check out the Transcription API with Toxicity Detection.
Amazon Transcribe Toxicity Detection is now obtainable within the following AWS Areas: US East (Ohio), US East (N. Virginia), US West (Oregon), Asia Pacific (Sydney), Europe (Eire), and Europe (London). To study extra, go to Amazon Transcribe.
Be taught extra about content moderation on AWS and our content moderation ML use cases. Take step one in the direction of streamlining your content moderation operations with AWS.
In regards to the writer
 Lana Zhang is a Senior Options Architect at AWS WWSO AI Companies staff, specializing in AI and ML for content material moderation, laptop imaginative and prescient, and pure language processing. Along with her experience, she is devoted to selling AWS AI/ML options and helping prospects in reworking their enterprise options throughout numerous industries, together with social media, gaming, e-commerce, and promoting & advertising.
Lana Zhang is a Senior Options Architect at AWS WWSO AI Companies staff, specializing in AI and ML for content material moderation, laptop imaginative and prescient, and pure language processing. Along with her experience, she is devoted to selling AWS AI/ML options and helping prospects in reworking their enterprise options throughout numerous industries, together with social media, gaming, e-commerce, and promoting & advertising.
 Sumit Kumar is a Sr Product Supervisor, Technical at AWS AI Language Companies staff. He has 10 years of product administration expertise throughout a wide range of domains and is keen about AI/ML. Outdoors of labor, Sumit likes to journey and enjoys enjoying cricket and Garden-Tennis.
Sumit Kumar is a Sr Product Supervisor, Technical at AWS AI Language Companies staff. He has 10 years of product administration expertise throughout a wide range of domains and is keen about AI/ML. Outdoors of labor, Sumit likes to journey and enjoys enjoying cricket and Garden-Tennis.

