
Visual language processing (VLP) is at the forefront of generative AI, driving advancements in multimodal learning that encompasses language intelligence, vision understanding, and processing. Combined with large language models (LLM) and Contrastive Language-Image Pre-Training (CLIP) trained with a large quantity of multimodality data, visual language models (VLMs) are particularly adept at tasks like image captioning, object detection and segmentation, and visual question answering. Their use cases span various domains, from media entertainment to medical diagnostics and quality assurance in manufacturing.
Key strengths of VLP include the effective utilization of pre-trained VLMs and LLMs, enabling zero-shot or few-shot predictions without necessitating task-specific modifications, and categorizing images from a broad spectrum through casual multi-round dialogues. Augmented by Grounded Segment Anything, VLP exhibits prowess in visual recognition, with object detection and segmentation being particularly notable. The potential exists to fine-tune VLMs and LLMs further using domain-specific data, aiming to boost precision and mitigate hallucination. However, like other nascent technologies, obstacles remain in managing model intricacy, harmonizing diverse modalities, and formulating uniform evaluation metrics.
Courtesy of NOMIC for OBELICS, HuggingFaceM4 for IDEFICS, Charles Bensimon for Gradio and Amazon Polly for TTS
In this post, we explore the technical nuances of VLP prototyping using Amazon SageMaker JumpStart in conjunction with contemporary generative AI models. Through multi-round dialogues, we highlight the capabilities of instruction-oriented zero-shot and few-shot vision language processing, emphasizing its versatility and aiming to capture the interest of the broader multimodal community. The demo implementation code is available in the following GitHub repo.
Solution overview
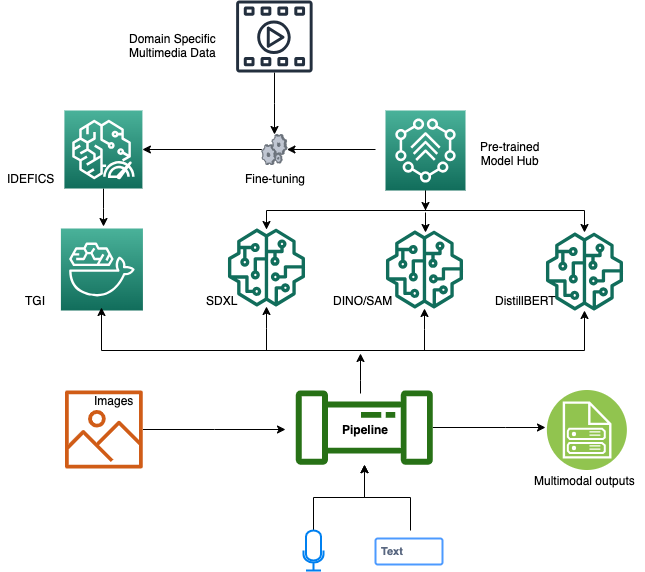
The proposed VLP solution integrates a suite of state-of-the-art generative AI modules to yield accurate multimodal outputs. Central to the architecture are the fine-tuned VLM and LLM, both instrumental in decoding visual and textual data streams. The TGI framework underpins the model inference layer, providing RESTful APIs for robust integration and effortless accessibility. Supplementing our auditory data processing, the Whisper ASR is also furnished with a RESTful API, enabling streamlined voice-to-text conversions. Addressing complex challenges like image-to-text segmentation, we use the containerized Grounded Segment Anything module, synergizing with the Grounded DINO and Segment Anything Model (SAM) mechanism for text-driven object detection and segmentation. The system is further refined with DistilBERT, optimizing our dialogue-guided multi-class classification process. Orchestrating these components is the LangChain processing pipeline, a sophisticated mechanism proficient in dissecting text or voice inputs, discerning user intentions, and methodically delegating sub-tasks to the relevant services. The synthesis of these operations produces aggregated outputs, delivering pinpoint and context-aware multimodal answers.
The following diagram illustrates the architecture of our dialogue-guided VLP solution.
Text Generation Inference
Text Generation Inference (TGI) is an open-source toolkit developed by Hugging Face for deploying LLMs as well as VLMs for inference. It enables high-performance text generation using tensor parallelism, model parallelism, and dynamic batching supporting some leading open-source LLMs such as Falcon and Llama V2, as well as VLMs like IDEFICS. Utilizing the latest Hugging Face LLM modules on Amazon SageMaker, AWS customers can now tap into the power of SageMaker deep learning containers (DLCs). This allows for the seamless deployment of LLMs from the Hugging Face hubs via pre-built SageMaker DLCs supporting TGI. This inference setup not only offers exceptional performance but also eliminates the need for managing the heavy lifting GPU infrastructure. Additionally, you benefit from advanced features like auto scaling of inference endpoints, enhanced security, and built-in model monitoring.
TGI offers text generation speeds up to 100 times faster than traditional inference methods and scales efficiently to handle increased requests. Its design ensures compatibility with various LLMs and, being open-source, democratizes advanced features for the tech community. TGI’s versatility extends across domains, enhancing chatbots, improving machine translations, summarizing texts, and generating diverse content, from poetry to code. Therefore, TGI emerges as a comprehensive solution for text generation challenges. TGI is implemented in Python and uses the PyTorch framework. It’s open-source and available on GitHub. It also supports PEFT with QLoRA for faster performance and logits warping to control generated text attributes, such as determining its length and diversity, without modifying the underlying model.
You can build a customized TGI Docker container directly from the following Dockerfile and then push the container image to Amazon Elastic Container Registry (ECR) for inference deployment. See the following code:
%%sh
# Define docker image name and container's Amazon Reource Name on ECR
container_name="tgi1.03"
region=`aws configure get region`
account=`aws sts get-caller-identity --query "Account" --output text`
full_name="${account}.dkr.ecr.${region}.amazonaws.com/${container_name}:latest"
# Get the login command from ECR and execute it directly
aws ecr get-login-password --region ${region}|docker login --username AWS \
--password-stdin ${account}.dkr.ecr.${region}.amazonaws.com
# Build the TGI docker image locally
docker build . -f Dockerfile -t ${container_name}
docker tag ${container_name} ${full_name}
docker push ${full_name}
LLM inference with TGI
The VLP solution in this post employs the LLM in tandem with LangChain, harnessing the chain-of-thought (CoT) approach for more accurate intent classification. CoT processes queries to discern intent and trigger-associated sub-tasks to meet the query’s goals. Llama-2-7b-chat-hf (license agreement) is the streamlined version of the Llama-2 line, designed for dialogue contexts. The inference of Llama-2-7b-chat-hf is powered by the TGI container image, making it available as an API-enabled service.
For Llama-2-7b-chat-hf inference, a g5.2xlarge (24G VRAM) is recommended to achieve peak performance. For applications necessitating a more robust LLM, the Llama-v2-13b models fit well with a g5.12xlarge (96G VRAM) instance. For the Llama-2-70b models, consider either the GPU [2xlarge] – 2x Nvidia A100 utilizing bitsandbytes quantization or the g5.48xlarge. Notably, employing bitsandbytes quantization can reduce the required inference GPU VRAM by 50%.
You can use SageMaker DLCs with the TGI container image detailed earlier to deploy Llama-2-7b-chat-hf for inference (see the following code). Alternatively, you can stand up a quick local inference for a proof of concept on a g5.2xlarge instance using a Docker container.
import json
from time import gmtime, strftime
from sagemaker.huggingface import get_huggingface_llm_image_uri
from sagemaker.huggingface import HuggingFaceModel
from sagemaker import get_execution_role
# Prerequisite:create an unique model name
model_name="Llama-7b-chat-hf" + strftime("%Y-%m-%d-%H-%M-%S", gmtime())
# retrieve the llm image uri of SageMaker pre-built DLC TGI v1.03
tgi_image_ecr_uri = get_huggingface_llm_image_uri(
"huggingface",
version="1.0.3"
)
# Define Model and Endpoint configuration parameter
hf_config = {
'HF_MODEL_ID': "meta-research/Llama-2-7b-chat-hf", # Matching model_id on Hugging Face Hub
'SM_NUM_GPUS': json.dumps(number_of_gpu),
'MAX_TOTAL_TOKENS': json.dumps(1024),
'HF_MODEL_QUANTIZE': "bitsandbytes", # Use quantization for less vram requirement, commet it if no needed.
}
# create HuggingFaceModel with the SageMaker pre-built DLC TGI image uri
sm_llm_model = HuggingFaceModel(
role=get_execution_role(),
image_uri=tgi_image_ecr_uri,
env=hf_config
)
# Deploy the model
llm = sm_llm_model.deploy(
initial_instance_count=1,
instance_type="ml.g5.2xlarge",
container_startup_health_check_timeout=300, # in sec. Allow 5 minutes to be able to load the model
)
# define inference payload
prompt="""<|prompter|>How to select a right LLM for your generative AI project?<|endoftext|><|assistant|>"""
# hyperparameters for llm
payload = {
"inputs": prompt,
"parameters": {
"best_of": 1,
"decoder_input_details": true,
"details": true,
"do_sample": true,
"max_new_tokens": 20,
"repetition_penalty": 1.03,
"return_full_text": false,
"seed": null,
"stop": [
"photographer"
],
"temperature": 0.5,
"top_k": 10,
"top_p": 0.95,
"truncate": null,
"typical_p": 0.95,
"watermark": true
},
"stream": false
}
# send request to endpoint
response = llm.predict(payload)
Fine-tune and customize your LLM
SageMaker JumpStart offers numerous notebook samples that demonstrate the use of Parameter Efficient Fine Tuning (PEFT), including QLoRA for training and fine-tuning LLMs. QLoRA maintains the pre-trained model weights in a static state and introduces trainable rank decomposition matrices into each layer of the Transformer structure. This method substantially decreases the number of trainable parameters needed for downstream tasks.
Alternatively, you can explore Direct Preference Optimization (DPO), which obviates the necessity for setting up a reward model, drawing samples during fine-tuning from the LLM, or extensive hyperparameter adjustments. Recent research has shown that DPO’s fine-tuning surpasses RLHF in managing sentiment generation and enhances the quality of summaries and single-conversation responses, all while being considerably easier to set up and educate. There are three main steps to the DPO training process (refer to the GitHub repo for details):
- Perform supervised fine-tuning of a pre-trained base LLM to create a fine-tuned LLM.
- Run the DPO trainer using the fine-tuned model to create a reinforcement learning model.
- Merge the adaptors from DPO into the base LLM model for text generation inference.
You can deploy the merged model for inference using the TGI container image.
Visual language model
Visual Language Models (VLM) which combine both the vision and language modalities have been showing their improving effectiveness in generalization, leading to various practical use cases with zero-shot prompts or few-shot prompts with instructions. A VLM typically consists of three key elements: an image encoder, a text encoder, and a strategy to fuse information from the two encoders. These key elements are tightly coupled together because the loss functions are designed around both the model architecture and the learning strategy. Many state-of-the-art VLMs use CLIP/ViT (such as OpenCLIP) and LLMs (such as Llama-v1) and are trained on multiple publicly available datasets such as Wikipedia, LAION, and Public Multimodal Dataset.
This demo used a pre-trained IDEFICS-9b-instruct model developed by HuggingFaceM4, a fine-tuned version of IDEFICS-9b, following the training procedure laid out in Flamingo by combining the two pre-trained models (laion/CLIP-ViT-H-14-laion2B-s32B-b79K and huggyllama/llama-7b) with modified Transformer blocks. The IDEFICS-9b was trained on OBELIC, Wikipedia, LAION, and PMD multimodal datasets with a total 150 billion tokens and 1.582 billion images with 224×224 resolution each. The IDEFICS-9b was based on Llama-7b with a 1.31 million effective batch size. The IDEFICS-9b-instruct was then fine-tuned with 6.8 million multimodality instruction datasets created from augmentation using generative AI by unfreezing all the parameters (vision encoder, language model, cross-attentions). The fine-tuning datasets include the pre-training data with the following sampling ratios: 5.1% of image-text pairs and 30.7% of OBELICS multimodal web documents.
The training software is built on top of Hugging Face Transformers and Accelerate, and DeepSpeed ZeRO-3 for training, plus WebDataset and Image2DataSets for data loading. The pre-training of IDEFICS-9b took 350 hours to complete on 128 Nvidia A100 GPUs, whereas fine-tuning of IDEFICS-9b-instruct took 70 hours on 128 Nvidia A100 GPUs, both on AWS p4.24xlarge instances.
With SageMaker, you can seamlessly deploy IDEFICS-9b-instruct on a g5.2xlarge instance for inference tasks. The following code snippet illustrates how to launch a tailored deep learning local container integrated with the customized TGI Docker image:
%%sh
llm_model="HuggingFaceM4/idefics-9b-instruct"
docker_rt_name="idefics-9b-instruct"
docker_image_name="tgi1.03"
docker run --gpus="1,2,3,4" --shm-size 20g -p 8080:80 --restart unless-stopped --name ${docker_rt_name} ${docker_image_name} --model-id ${llm_model}
# Test the LLM API using curl
curl -X 'POST' \ ' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"inputs": "User:Which device produced this image? Please explain the main clinical purpose of such image?Can you write a radiology report based on this image?<end_of_utterance>", \ "parameters": {
"best_of": 1, "decoder_input_details": true, \
"details": true, "do_sample": true, "max_new_tokens": 20, \
"repetition_penalty": 1.03, "return_full_text": false, \
"seed": null, "stop": [ "photographer" ], \
"temperature": 0.5, "top_k": 10, "top_p": 0.95, \
"truncate": null, "typical_p": 0.95, "watermark": true }, \
"stream": false \
}'
You can fine-tune IDEFICS or other VLMs including Open Flamingo with your own domain-specific data with instructions. Refer to the following README for multimodality dataset preparation and the fine-tuning script for further details.
Intent classification with chain-of-thought
A picture is worth a thousand words, therefore VLM requires guidance to generate an accurate caption from a given image and question. We can use few-shot prompting to enable in-context learning, where we provide demonstrations in the prompt to steer the model to better performance. The demonstrations serve as conditioning for subsequent examples where we would like the model to generate a response.
Standard few-shot prompting works well for many tasks but is still not a perfect technique, especially when dealing with more complex reasoning tasks. The few-shot prompting template is not enough to get reliable responses. It might help if we break the problem down into steps and demonstrate that to the model. More recently, chain-of-thought (CoT) prompting has been popularized to address more complex arithmetic, common sense, and symbolic reasoning tasks
CoT eliminate manual efforts by using LLMs with a “Let’s think step by step” prompt to generate reasoning chains for demonstrations one by one. However, this automatic process can still end up with mistakes in generated chains. To mitigate the effects of the mistakes, the diversity of demonstrations matter. This post proposes Auto-CoT, which samples questions with diversity and generates reasoning chains to construct the demonstrations. CoT consists of two main stages:
- Question clustering – Partition questions of a given dataset into a few clusters
- Demonstration sampling – Select a representative question from each cluster and generate its reasoning chain using zero-shot CoT with simple heuristics
See the following code snippet:
from langchain.llms import HuggingFaceTextGenInference
from langchain import PromptTemplate, LLMChain
inference_server_url_local = <Your_local_url_for_llm_on_tgi:port>
llm_local = HuggingFaceTextGenInference(
inference_server_url=inference_server_url_local,
max_new_tokens=512,
top_k=10,
top_p=0.95,
typical_p=0.95,
temperature=0.1,
repetition_penalty=1.05,
template = """Use the following pieces of context to answer the question at the end. If you don't know the answer, just say that you don't know, don't try to make up an answer.
Use ten five maximum and keep the answer as subtle as possible. List all actionable sub-tasks step by step in detail. Be cautious to avoid phrasing that might replicate previous
inquiries. This will help in obtaining an accurate and detailed answer. Avoid repetition for clarity.
Question: {question}
Answer: Understand the intent of the question then break down the {question} in to sub-tasks. """
prompt = PromptTemplate(
template=template,
input_variables= ["question"]
)
llm_chain_local = LLMChain(prompt=prompt, llm=llm_local)
llm_chain_local("Can you describe the nature of this image? Do you think it's real??")
Automatic Speech Recognition
The VLP solution incorporates Whisper, an Automatic Speech Recognition (ASR) model by OpenAI, to handle audio queries. Whisper can be effortlessly deployed via SageMaker JumpStart using its template. SageMaker JumpStart, known for its straightforward setup, high performance, scalability, and dependability, is ideal for developers aiming to craft exceptional voice-driven applications. The following GitHub repo demonstrates how to harness SageMaker real-time inference endpoints to fine-tune and host Whisper for instant audio-to-text transcription, showcasing the synergy between SageMaker hosting and generative models.
Alternatively, you can directly download the Dockerfile.gpu from GitHub developed by ahmetoner, which includes a pre-configured RESTful API. You can then construct a Docker image and run the container on a GPU-powered Amazon Elastic Compute Cloud (EC2) instance for a quick proof of concept. See the following code:
%%sh
docker_iamge_name="whisper-asr-webservice-gpu"
docker build -f Dockerfile.gpu -t ${docker_iamge_nam}
docker run -d --gpus all -p 8083:9000 --restart unless-stopped -e ASR_MODEL=base ${docker_iamge_nam}
curl -X 'POST' \ ' \
-H 'accept: application/json' \
-H 'Content-Type: multipart/form-data' \
-F 'audio_file=@dgvlp_3_5.mp3;type=audio/mpeg'
In the provided example, port 8083 is selected to host the Whisper API, with inbound network security rules activated. To test, direct a web browser to and initiate a POST request test to the ASR endpoint. As an alternative, run the given command or employ the whisper-live module to verify API connectivity.
!pip install whisper-live
from whisper_live.client import TranscriptionClient
client = TranscriptionClient("<whisper_hostname_or_IP>", 8083, is_multilingual=True, lang="zh", translate=True)
client(audio_file_path) # Use sudio file
client() # Use microphone for transcribe
Multi-class text classification and keyword extraction
Multi-class classification plays a pivotal role in text prompt-driven object detection and segmentation. The distilbert-base-uncased-finetuned-sst-2-english model is a refined checkpoint of DistilBERT-base-uncased, optimized on the Stanford Sentiment Treebank (SST2) dataset by Hugging Face. This model achieves a 91.3% accuracy on the development set, while its counterpart bert-base-uncased boasts an accuracy of 92.7%. The Hugging Face Hub provides access to over 1,000 pre-trained text classification models. For those seeking enhanced precision, SageMaker JumpStart provides templates to fine-tune DistilBERT using custom annotated datasets for more tailored classification tasks.
import torch
from transformers import pipeline
def mclass(text_prompt, top_k=3, topics = ['Mask creation', 'Object detection',
'Inpainting', 'Segmentation', 'Upscaling', 'Creating an image from another one', 'Generating:q an image from text'],
model="distilbert-base-uncased-finetuned-sst-2-english"):
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# Define a german hypothesis template and the potential candidates for entailment/contradiction
template_de="The topic is {}"
# Pipeline abstraction from hugging face
pipe = pipeline(task='zero-shot-classification', model=model, tokenizer=model, device=device)
# Run pipeline with a test case
prediction = pipe(text_prompt, topics, hypothesis_template=template_de)
# Top 3 topics as predicted in zero-shot regime
return zip(prediction['labels'][0:top_k], prediction['scores'][0:top_k])
top_3_intend = mclass(text_prompt=user_prompt_str, topics=['Others', 'Create image mask', 'Image segmentation'], top_k=3)
The keyword extraction process employs the KeyBERT module, a streamlined and user-friendly method that harnesses BERT embeddings to generate keywords and key phrases closely aligned with a document—in this case, the objects specified in the query:
# Keyword extraction
from keybert import KeyBERT
kw_model = KeyBERT()
words_list = kw_model.extract_keywords(docs=<user_prompt_str>, keyphrase_ngram_range=(1,3))
Text prompt-driven object detection and classification
The VLP solution employs dialogue-guided object detection and segmentation by analyzing the semantic meaning of the text and identifying the action and objects from text prompt. Grounded-SAM is an open-source package created by IDEA-Research to detect and segment anything from a given image with text inputs. It combines the strengths of Grounding DINO and Segment Anything in order to build a very powerful pipeline for solving complex problems.
The following figure illustrates how Grounded-SAM can detect objects and conduct instance segmentation by comprehending textual input.

SAM stands out as a robust segmentation model, though it requires prompts, such as bounding boxes or points, to produce high-quality object masks. Grounding DINO excels as a zero-shot detector, adeptly creating high-quality boxes and labels using free-form text prompts. When these two models are combined, they offer the remarkable capability to detect and segment any object purely through text inputs. The Python utility script dino_sam_inpainting.py was developed to integrate Grounded-SAM methods:
!pip install git+
import dino_sam_inpainting as D
def dino_sam(image_path, text_prompt, text_threshold=0.4, box_threshold=0.5, output_dir="/temp/gradio/outputs"):
config_file="GroundingDINO/groundingdino/config/GroundingDINO_SwinT_OGC.py" # change the path of the model config file
grounded_checkpoint="./models/groundingdino_swint_ogc.pth" # change the path of the model
sam_checkpoint="./models/sam_vit_h_4b8939.pth"
sam_hq_checkpoint="" #if to use high quality, like sam_hq_vit_h.pth
use_sam_hq = ''
output_dir="/tmp/gradio/outputs"
device="cuda"
# make dir
os.makedirs(output_dir, exist_ok=True)
# load image
image_pil, image = D.load_image(image_path)
# load model
model = D.load_model(config_file, grounded_checkpoint, device=device)
output_file_name = f'{format(os.path.basename(image_path))}'
# visualize raw image
image_pil.save(os.path.join(output_dir, output_file_name))
# run grounding dino model
boxes_filt, pred_phrases = D.get_grounding_output(
model, image, text_prompt, box_threshold, text_threshold, device=device
)
# initialize SAM
if use_sam_hq:
predictor = D.SamPredictor(D.build_sam_hq(checkpoint=sam_hq_checkpoint).to(device))
else:
predictor = D.SamPredictor(D.build_sam(checkpoint=sam_checkpoint).to(device))
image = cv2.imread(image_path)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
predictor.set_image(image)
size = image_pil.size
H, W = size[1], size[0]
for i in range(boxes_filt.size(0)):
boxes_filt[i] = boxes_filt[i] * torch.Tensor([W, H, W, H])
boxes_filt[i][:2] -= boxes_filt[i][2:] / 2
boxes_filt[i][2:] += boxes_filt[i][:2]
boxes_filt = boxes_filt.cpu()
transformed_boxes = predictor.transform.apply_boxes_torch(boxes_filt, image.shape[:2]).to(device)
masks, _, _ = predictor.predict_torch(
point_coords = None,
point_labels = None,
boxes = transformed_boxes.to(device),
multimask_output = False,
)
# draw output image
plt.figure(figsize=(10, 10))
plt.imshow(image)
for mask in masks:
D.show_mask(mask.cpu().numpy(), plt.gca(), random_color=True)
for box, label in zip(boxes_filt, pred_phrases):
D.show_box(box.numpy(), plt.gca(), label)
output_file_name = f'{format(os.path.basename(image_path))}'
plt.axis('off')
plt.savefig(
os.path.join(output_dir, f'grounded_sam_{output_file_name}'),
bbox_inches="tight", dpi=300, pad_inches=0.0
)
D.save_mask_data(output_dir, masks, boxes_filt, pred_phrases)
return f'grounded_sam_{output_file_name}'
filename = dino_sam(image_path=<image_path_str>, text_prompt=<object_name_str>, output_dir=<output_image_filename_path_str>, box_threshold=0.5, text_threshold=0.55)
You can choose HQ-SAM to upgrade SAM for high-quality zero-shot segmentation. Refer to the following paper and code sample on GitHub for more details.
VLP processing pipeline
The main objective of the VLP processing pipeline is to combine the strengths of different models, creating a sophisticated workflow specialized for VLP. It’s important to highlight that this setup prioritizes the integration of top-tier models across visual, text, and voice domains. Each segment of the pipeline is modular, facilitating either standalone use or combined operation. Furthermore, the design ensures flexibility, enabling the replacement of components with more advanced models yet to come, while supporting multithreading and error handling with reputable implementation.
The following figure illustrates a VLP pipeline data flow and service components.

In our exploration of the VLP pipeline, we design one which can process both text prompts from open text format and casual voice inputs from microphones. The audio processing is facilitated by Whisper, capable of multilingual speech recognition and translation. The transcribed text is then channeled to an intent classification module, which discerns the semantic essence of the prompts. This works in tandem with a LangChain driven CoT engine, dissecting the main intent into finer sub-tasks for more detailed information retrieval and generation. If image processing is inferred from the input, the pipeline commences a keyword extraction process, selecting the top N keywords by cross-referencing objects detected in the original image. Subsequently, these keywords are routed to the Grounded-SAM engine, which generates bounding boxes. These bounding boxes are then supplied to the SAM model, which crafts precise segmentation masks, pinpointing each unique object instance in the source image. The final step involves overlaying the masks and bounding boxes onto the original image, yielding a processed image that is presented as a multimodal output.
When the input query seeks to interpret an image, the pipeline engages the LLM to organize the sub-tasks and refine the query with targeted goals. Subsequently, the outcome is directed to the VLM API, accompanied by few-shot instructions, the URL of the input image, and the rephrased text prompt. In response, the VLM provides the textual output. The VLP pipeline can be implemented using a Python-based workflow pipeline or alternative orchestration utilities. Such pipelines operate by chaining a sequential set of sophisticated models, culminating in a structured modeling procedure sequentially. The pipeline integrates with the Gradio engine for demonstration purposes:
def vlp_text_pipeline(str input_text, str original_image_path, chat_history):
intent_class = intent_classification(input_text)
key_words = keyword_extraction(input_text)
image_caption = vlm(input_text, original_image_path)
chat_history.append(image_caption)
if intent_class in {supported intents}:
object_bounding_box = object_detection(intent_class, key_words, original_image_path)
mask_image_path = image_segmentation(object_bounding_box, key_words, original_image_path)
chat_history.append(mask_image_path)
return chat_history
def vlp_voice_pipeline(str audio_file_path, str original_image_path, chat_history):
asr_text = whisper_transcrib(audio_file_path)
chat_history.append(asr_text, original_image_path, chat_history)
return chat_history
chat_history = map(vlp_pipelines, input_text, original_image_path, chat_history) \
if (audio_file_path is None) \
else map(vlp_voice_pipelines, original_image_path, chat_history)
Limitations
Using pre-trained VLM models for VLP has demonstrated promising potential for image understanding. Along with language-based object detection and segmentation, VLP can produce useful outputs with reasonable quality. However, VLP still suffers from inconsistent results, missing details from pictures, and it might even hallucinate. Moreover, models might produce factually incorrect texts and should not be relied on to produce factually accurate information. Since none of the referenced pre-trained VLM, SAM, or LLM models has been trained or fine-tuned for domain-specific production-grade applications, this solution is not designed for mission-critical applications that might impact livelihood or cause material losses
With prompt engineering, the IDEFICS model sometimes can recognize extra details after a text hint; however, the result is far from consistent and reliable. It can be persistent in maintaining inaccuracies and may be unable or unwilling to make corrections even when users highlight those during a conversation. Enhancing the backbone model by integrating Swin-ViT and fusing it with CNN-based models like DualToken-ViT, along with training using more advanced models like Llama-v2, could potentially address some of these limitations.
Next steps
The VLP solution is poised for notable progress. As we look ahead, there are several key opportunities to advance VLP solutions:
- Prioritize integrating dynamic prompt instructions and few-shot learning hints. These improvements will enable more accurate AI feedback.
- Intent classification teams should focus efforts on refining the classifier to pick up on nuanced, domain-specific intents from open prompts. Being able to understand precise user intents will be critical.
- Implement an agent tree of thoughts model into the reasoning pipeline. This structure will allow for explicit reasoning steps to complete sub-tasks.
- Pilot fine-tuning initiatives on leading models. Tailoring VLM, LLM, and SAM models to key industries and use cases through fine-tuning will be pivotal.
Acknowledgment
The authors extend their gratitude to Vivek Madan and Ashish Rawat for their insightful feedback and review of this post.
About the authors
 Alfred Shen is a Senior AI/ML Specialist at AWS. He has been working in Silicon Valley, holding technical and managerial positions in diverse sectors including healthcare, finance, and high-tech. He is a dedicated applied AI/ML researcher, concentrating on CV, NLP, and multimodality. His work has been showcased in publications such as EMNLP, ICLR, and Public Health.
Alfred Shen is a Senior AI/ML Specialist at AWS. He has been working in Silicon Valley, holding technical and managerial positions in diverse sectors including healthcare, finance, and high-tech. He is a dedicated applied AI/ML researcher, concentrating on CV, NLP, and multimodality. His work has been showcased in publications such as EMNLP, ICLR, and Public Health.
 Dr. Li Zhang is a Principal Product Manager-Technical for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms, a service that helps data scientists and machine learning practitioners get started with training and deploying their models, and uses reinforcement learning with Amazon SageMaker. His past work as a principal research staff member and master inventor at IBM Research has won the test of time paper award at IEEE INFOCOM.
Dr. Li Zhang is a Principal Product Manager-Technical for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms, a service that helps data scientists and machine learning practitioners get started with training and deploying their models, and uses reinforcement learning with Amazon SageMaker. His past work as a principal research staff member and master inventor at IBM Research has won the test of time paper award at IEEE INFOCOM.
 Dr. Changsha Ma is an AI/ML Specialist at AWS. She is a technologist with a PhD in Computer Science, a master’s degree in Education Psychology, and years of experience in data science and independent consulting in AI/ML. She is passionate about researching methodological approaches for machine and human intelligence. Outside of work, she loves hiking, cooking, hunting food, mentoring college students for entrepreneurship, and spending time with friends and families.
Dr. Changsha Ma is an AI/ML Specialist at AWS. She is a technologist with a PhD in Computer Science, a master’s degree in Education Psychology, and years of experience in data science and independent consulting in AI/ML. She is passionate about researching methodological approaches for machine and human intelligence. Outside of work, she loves hiking, cooking, hunting food, mentoring college students for entrepreneurship, and spending time with friends and families.
 Xin Huang is a Senior Applied Scientist for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms. He focuses on developing scalable machine learning algorithms. His research interests are in the area of natural language processing, explainable deep learning on tabular data, and robust analysis of non-parametric space-time clustering. He has published many papers in ACL, ICDM, KDD conferences, and Royal Statistical Society: Series A.
Xin Huang is a Senior Applied Scientist for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms. He focuses on developing scalable machine learning algorithms. His research interests are in the area of natural language processing, explainable deep learning on tabular data, and robust analysis of non-parametric space-time clustering. He has published many papers in ACL, ICDM, KDD conferences, and Royal Statistical Society: Series A.

