
People are an interactive species. We work together with the bodily world and with each other. For synthetic intelligence (AI) to be typically useful, it should be capable to work together capably with people and their setting. On this work we current the Multimodal Interactive Agent (MIA), which blends visible notion, language comprehension and manufacturing, navigation, and manipulation to have interaction in prolonged and infrequently stunning bodily and linguistic interactions with people.

We construct upon the method launched by Abramson et al. (2020), which primarily makes use of imitation studying to coach brokers. After coaching, MIA shows some rudimentary clever behaviour that we hope to later refine utilizing human suggestions. This work focuses on the creation of this clever behavioural prior, and we go away additional feedback-based studying for future work.
We created the Playhouse setting, a 3D digital setting composed of a randomised set of rooms and numerous home interactable objects, to supply an area and setting for people and brokers to work together collectively. People and brokers can work together within the Playhouse by controlling digital robots that locomote, manipulate objects, and talk by way of textual content. This digital setting permits a variety of located dialogues, starting from easy directions (e.g., “Please decide up the ebook from the ground and place it on the blue bookshelf”) to artistic play (e.g., “Deliver meals to the desk in order that we are able to eat”).
We collected human examples of Playhouse interactions utilizing language video games, a group of cues prompting people to improvise sure behaviours. In a language recreation one participant (the setter) receives a prewritten immediate indicating a type of process to suggest to the opposite participant (the solver). For instance, the setter would possibly obtain the immediate “Ask the opposite participant a query in regards to the existence of an object,” and after some exploration, the setter may ask, ”Please inform me whether or not there’s a blue duck in a room that doesn’t even have any furnishings.” To make sure ample behavioural range, we additionally included free-form prompts, which granted setters free option to improvise interactions (E.g. “Now take any object that you simply like and hit the tennis ball off the stool in order that it rolls close to the clock, or someplace close to it.”). In complete, we collected 2.94 years of real-time human interactions within the Playhouse.
.jpg)
Our coaching technique is a mix of supervised prediction of human actions (behavioural cloning) and self-supervised studying. When predicting human actions, we discovered that utilizing a hierarchical management technique considerably improved agent efficiency. On this setting, the agent receives new observations roughly 4 occasions per second. For every commentary, it produces a sequence of open-loop motion actions and optionally emits a sequence of language actions. Along with behavioural cloning we use a type of self-supervised studying, which duties brokers with classifying whether or not sure imaginative and prescient and language inputs belong to the identical or completely different episodes.
To judge agent efficiency, we requested human individuals to work together with brokers and supply binary suggestions indicating whether or not the agent efficiently carried out an instruction. MIA achieves over 70% success charge in human-rated on-line interactions, representing 75% of the success charge that people themselves obtain after they play as solvers. To raised perceive the position of assorted elements in MIA, we carried out a sequence of ablations, eradicating, for instance, visible or language inputs, the self-supervised loss, or the hierarchical management.
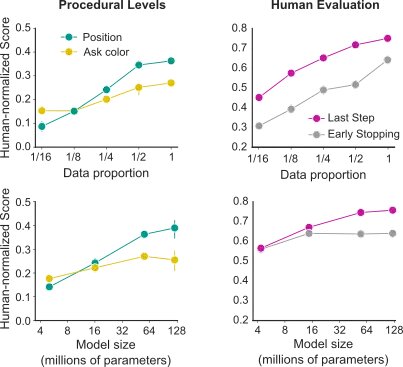
Modern machine studying analysis has uncovered exceptional regularities of efficiency with respect to completely different scale parameters; specifically, mannequin efficiency scales as a power-law with dataset measurement, mannequin measurement, and compute. These results have been most crisply famous within the language area, which is characterised by large dataset sizes and extremely developed architectures and coaching protocols. On this work, nonetheless, we’re in a decidedly completely different regime – with comparatively small datasets and multimodal, multi-task goal features coaching heterogeneous architectures. However, we display clear results of scaling: as we improve dataset and mannequin measurement, efficiency will increase appreciably.
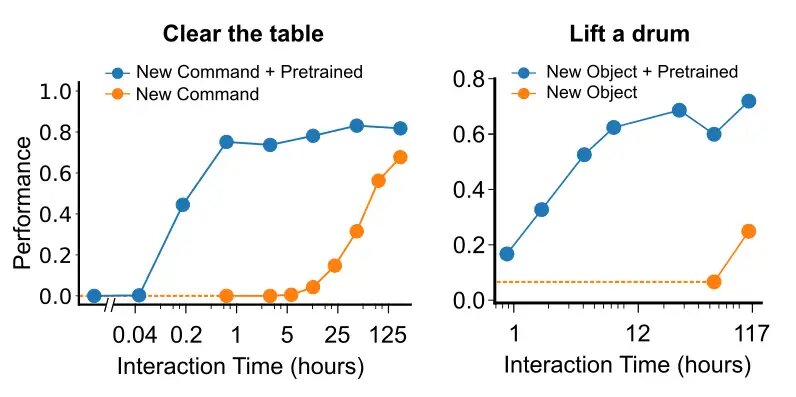
In a great case, coaching turns into extra environment friendly given a pretty big dataset, as information is transferred between experiences. To research how excellent our circumstances are, we examined how a lot information is required to study to work together with a brand new, beforehand unseen object and to learn to observe a brand new, beforehand unheard command / verb. We partitioned our information into background information and information involving a language instruction referring to the thing or the verb. After we reintroduced the info referring to the brand new object, we discovered that fewer than 12 hours of human interplay was sufficient to accumulate the ceiling efficiency. Analogously, once we launched the brand new command or verb ‘to clear’ (i.e. to take away all objects from a floor), we discovered that just one hour of human demonstrations was sufficient to succeed in ceiling efficiency in duties involving this phrase.
MIA displays startlingly wealthy behaviour, together with a range of behaviours that weren’t preconceived by researchers, together with tidying a room, discovering a number of specified objects, and asking clarifying questions when an instruction is ambiguous. These interactions regularly encourage us. Nevertheless, the open-endedness of MIA’s behaviour presents immense challenges for quantitative analysis. Creating complete methodologies to seize and analyse open-ended behaviour in human-agent interactions will likely be an essential focus in our future work.
For a extra detailed description of our work, see our paper.
