Within the previous article of this sequence, we explored the OpenAI Python API and used it to make a customized chatbot. One draw back of this API, nevertheless, is that API calls value cash, which can not scale nicely for some use circumstances.
In these situations, it might be advantageous to show to open-source options. One well-liked means to do that is by way of Hugging Face’s Transformers library.
Hugging Face is an AI firm that has grow to be a serious hub for open-source machine studying (ML). Their platform has 3 main components which permit customers to entry and share machine studying sources.
First is their quickly rising repository of pre-trained open-source ML fashions for issues corresponding to pure language processing (NLP), laptop imaginative and prescient, and extra. Second is their library of datasets for coaching ML fashions for nearly any process. Third, and at last, is Areas which is a set of open-source ML apps hosted by Hugging Face.
The facility of those sources is that they’re neighborhood generated, which leverages all the advantages of open-source (i.e. cost-free, large range of instruments, high-quality sources, and fast tempo of innovation). Whereas these make constructing highly effective ML initiatives extra accessible than earlier than, there may be one other key ingredient of the Hugging Face ecosystem — the Transformers library.
Transformers is a Python library that makes downloading and coaching state-of-the-art ML fashions simple. Though it was initially made for creating language fashions, its performance has expanded to incorporate fashions for laptop imaginative and prescient, audio processing, and past.
Two large strengths of this library are, one, it simply integrates with Hugging Face’s (beforehand talked about) Fashions, Datasets, and Areas repositories, and two, the library helps different well-liked ML frameworks corresponding to PyTorch and TensorFlow.
This ends in a easy and versatile all-in-one platform for downloading, coaching, and deploying machine studying fashions and apps.
Pipeline()
The best method to begin utilizing the library is by way of the pipeline() perform, which abstracts NLP (and different) duties into 1 line of code. For instance, if we need to do sentiment evaluation, we would wish to pick a mannequin, tokenize the enter textual content, move it by way of the mannequin, and decode the numerical output to find out the sentiment label (constructive or adverse).
Whereas this may occasionally seem to be numerous steps, we are able to do all this in 1 line by way of the pipeline() perform, as proven within the code snippet under.
pipeline(process="sentiment-analysis")("Love this!")# output -> [{'label': 'POSITIVE', 'score': 0.9998745918273926}]
In fact, sentiment evaluation just isn’t the one factor we are able to do right here. Nearly any NLP process will be executed on this means e.g. summarization, translation, question-answering, characteristic extraction (i.e. textual content embedding), textual content era, zero-shot-classification, and extra — for a full checklist of the built-in duties, try the pipleine() documentation.
Within the above instance code, since we didn’t specify a mannequin, the default mannequin for sentiment evaluation was used (i.e. distilbert-base-uncased-finetuned-sst-2-english). Nevertheless, if we wished to be extra specific, we might have used the next line of code.
pipeline(process="sentiment-analysis",
mannequin='distilbert-base-uncased-finetuned-sst-2-english')("Love this!")# ouput -> [{'label': 'POSITIVE', 'score': 0.9998745918273926}]
One of many best advantages of the Transformers library is we might have simply as simply used any of the 28,000+ textual content classification fashions on Hugging Face’s Models repository by merely altering the mannequin title handed into the pipeline() perform.
Fashions
There’s a huge repository of pre-trained fashions accessible on Hugging Face (277,528 on the time of scripting this). Each one of these fashions will be simply used by way of Transformers, utilizing the identical syntax we noticed within the above code block.
Nevertheless, the fashions on Hugging Face aren’t just for the Transformers library. There are fashions for different well-liked machine studying frameworks e.g. PyTorch, Tensorflow, Jax. This makes Hugging Face’s Fashions repository helpful to ML practitioners past the context of the Transformers library.
To see what navigating the repository appears like, let’s think about an instance. Say we wish a mannequin that may do textual content era, however we wish it to be accessible by way of the Transformers library so we are able to use it in a single line of code (as we did above). We will simply view all fashions that match these standards utilizing the “Duties” and “Libraries” filters.
A mannequin that meets these standards is the newly launched Llama 2. Extra particularly, Llama-2–7b-chat-hf, which is a mannequin within the Llama 2 household with about 7 billion parameters, optimized for chat, and within the Hugging Face Transformers format. We will get extra details about this mannequin by way of its mannequin card, which is proven within the determine under.

Now that now we have a primary thought of the sources supplied by Hugging Face and the Transformers library let’s see how we are able to use them. We begin by putting in the library and different dependencies.
Hugging Face supplies an installation guide on its web site. So, I gained’t attempt to (poorly) duplicate that information right here. Nevertheless, I’ll present a fast 2-step information on how one can arrange the conda setting for the instance code under.
Step 1) Step one is to obtain the hf-env.yml file accessible on the GitHub repository. You’ll be able to both obtain the file straight or clone the entire repo.
Step 2) Subsequent, in your terminal (or anaconda command immediate), you possibly can create a brand new conda setting primarily based on hf-env.yml utilizing the next instructions
>>> cd <listing with hf-env.yml>>>> conda env create --file hf-env.yml
This will likely take a few minutes to put in, however as soon as it’s full, you need to be able to go!
With the mandatory libraries put in, let’s soar into some instance code. Right here we’ll survey 3 NLP use circumstances, particularly, sentiment evaluation, summarization, and conversational textual content era, utilizing the pipeline() perform.
Towards the top, we’ll use Gradio to shortly generate a Person Interface (UI) for any of those use circumstances and deploy it as an app on Hugging Face Areas. All instance code is accessible on the GitHub repository.
Sentiment Evaluation
We begin sentiment evaluation. Recall from earlier after we used the pipeline perform to do one thing just like the code block under, the place we create a classifier that may label the enter textual content as being both constructive or adverse.
from transformers import pipelineclassifier = pipeline(process="sentiment-analysis",
mannequin="distilbert-base-uncased-finetuned-sst-2-english")
classifier("Hate this.")
# output -> [{'label': 'NEGATIVE', 'score': 0.9997110962867737}]
To go one step additional, as a substitute of processing textual content one after the other, we are able to move an inventory to the classifier to course of as a batch.
text_list = ["This is great",
"Thanks for nothing",
"You've got to work on your face",
"You're beautiful, never change!"]classifier(text_list)
# output -> [{'label': 'POSITIVE', 'score': 0.9998785257339478},
# {'label': 'POSITIVE', 'score': 0.9680058360099792},
# {'label': 'NEGATIVE', 'score': 0.8776106238365173},
# {'label': 'POSITIVE', 'score': 0.9998120665550232}]
Nevertheless, the textual content classification fashions on Hugging Face aren’t restricted to only positive-negative sentiment. For instance, the “roberta-base-go_emotions” mannequin by SamLowe generates a set of sophistication labels. We will simply as simply apply this mannequin to textual content, as proven within the code snippet under.
classifier = pipeline(process="text-classification",
mannequin="SamLowe/roberta-base-go_emotions", top_k=None)classifier(text_list[0])
# output -> [[{'label': 'admiration', 'score': 0.9526104927062988},
# {'label': 'approval', 'score': 0.03047208860516548},
# {'label': 'neutral', 'score': 0.015236231498420238},
# {'label': 'excitement', 'score': 0.006063772831112146},
# {'label': 'gratitude', 'score': 0.005296189337968826},
# {'label': 'joy', 'score': 0.004475208930671215},
# ... and many more
Summarization
Another way we can use the pipeline() function is for text summarization. Although this is an entirely different task than sentiment analysis, the syntax is almost identical.
We first load in a summarization model. Then pass in some text along with a couple of input parameters.
summarizer = pipeline("summarization", model="facebook/bart-large-cnn")text = """
Hugging Face is an AI company that has become a major hub for open-source machine learning.
Their platform has 3 major elements which allow users to access and share machine learning resources.
First, is their rapidly growing repository of pre-trained open-source machine learning models for things such as natural language processing (NLP), computer vision, and more.
Second, is their library of datasets for training machine learning models for almost any task.
Third, and finally, is Spaces which is a collection of open-source ML apps.
The power of these resources is that they are community generated, which leverages all the benefits of open source i.e. cost-free, wide diversity of tools, high quality resources, and rapid pace of innovation.
While these make building powerful ML projects more accessible than before, there is another key element of the Hugging Face ecosystem—their Transformers library.
"""
summarized_text = summarizer(text, min_length=5, max_length=140)[0]['summary_text']
print(summarized_text)
# output -> 'Hugging Face is an AI firm that has grow to be a serious hub for
# open-source machine studying. They've 3 main components which permit customers
# to entry and share machine studying sources.'
For extra subtle use circumstances, it might be crucial to make use of a number of fashions in succession. For instance, we are able to apply sentiment evaluation to the summarized textual content to hurry up the runtime.
classifier(summarized_text)# output -> [[{'label': 'neutral', 'score': 0.9101783633232117},
# {'label': 'approval', 'score': 0.08781372010707855},
# {'label': 'realization', 'score': 0.023256294429302216},
# {'label': 'annoyance', 'score': 0.006623792927712202},
# {'label': 'admiration', 'score': 0.004981081001460552},
# {'label': 'disapproval', 'score': 0.004730119835585356},
# {'label': 'optimism', 'score': 0.0033590723760426044},
# ... and many more
Conversational
Finally, we can use models developed specifically to generate conversational text. Since conversations require past prompts and responses to be passed to subsequent model responses, the syntax is a little different here. However, we start by instantiating our model using the pipeline() function.
chatbot = pipeline(model="facebook/blenderbot-400M-distill")
Next, we can use the Conversation() class to handle the back-and-forth. We initialize it with a user prompt, then pass it into the chatbot model from the previous code block.
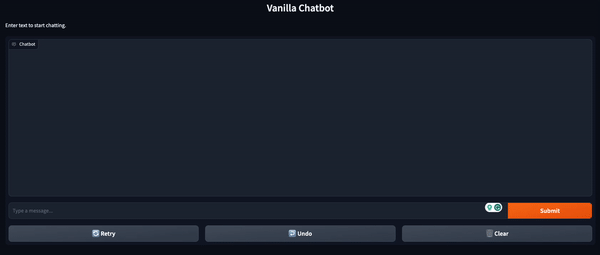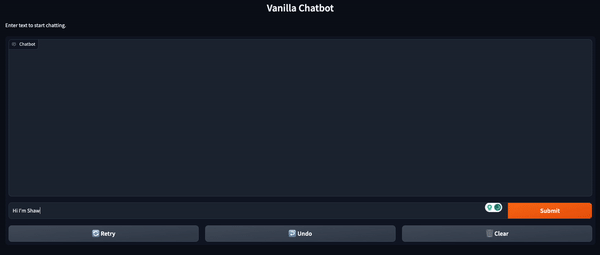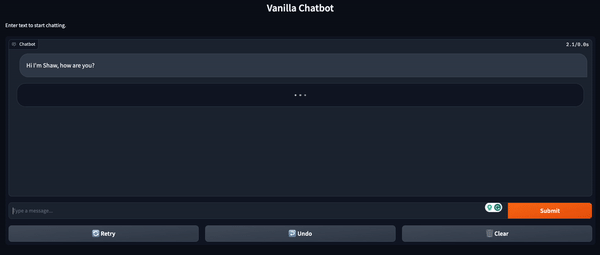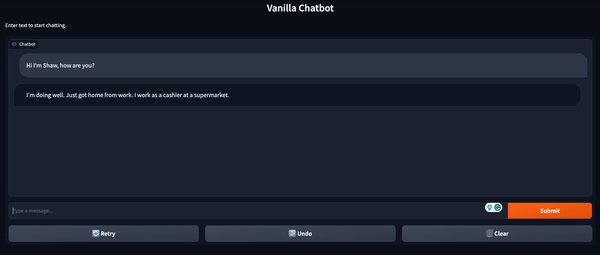
from transformers import Conversationconversation = Conversation("Hi I'm Shaw, how are you?")
conversation = chatbot(conversation)
print(conversation)
# output -> Conversation id: 9248ee7d-2a58-4355-9fba-525189fae206
# user >> Hi I'm Shaw, how are you?
# bot >> I'm doing well. How are you doing this evening? I just got home from work.
To keep the conversation going, we can use the add_user_input() method to add another prompt to the conversation. We then pass the conversation object back into the chatbot.
conversation.add_user_input("Where do you work?")
conversation = chatbot(conversation)
print(conversation)# output -> Conversation id: 9248ee7d-2a58-4355-9fba-525189fae206
# user >> Hi I'm Shaw, how are you?
# bot >> I'm doing well. How are you doing this evening? I just got home from work.
# user >> Where do you work?
# bot >> I work at a grocery store. What about you? What do you do for a living?
Chatbot UI with Gradio
While we get the base chatbot functionality with the Transformer library, this is an inconvenient way to interact with a chatbot. To make the interaction a bit more intuitive, we can use Gradio to spin up a front end in a few lines of Python code.
This is done with the code shown below. At the top, we initialize two lists to store user messages and model responses, respectively. Then we define a function that will take the user prompt and generate a chatbot output. Next, we create the chat UI using the Gradio ChatInterface() class. Finally, we launch the app.
message_list = []
response_list = []def vanilla_chatbot(message, historical past):
dialog = Dialog(textual content=message, past_user_inputs=message_list, generated_responses=response_list)
dialog = chatbot(dialog)
return dialog.generated_responses[-1]
demo_chatbot = gr.ChatInterface(vanilla_chatbot, title="Vanilla Chatbot", description="Enter textual content to begin chatting.")
demo_chatbot.launch()
This can spin up the UI by way of an area URL. If the window doesn’t open robotically, you possibly can copy and paste the URL straight into your browser.
Hugging Face Areas
To go one step additional, we are able to shortly deploy this UI by way of Hugging Face Areas. These are Git repositories hosted by Hugging Face and augmented by computational sources. Each free and paid choices can be found relying on the use case. Right here we’ll keep on with the free possibility.
To make a brand new Area, we first go to the Spaces page and click on “Create new area”. Then, configure the Area by giving it the title e.g. “my-first-space” and deciding on Gradio because the SDK. Then hit “Create Area”.

Subsequent, we have to add app.py and necessities.txt recordsdata to the Area. The app.py file homes the code we used to generate the Gradio UI, and the necessities.txt file specifies the app’s dependencies. The recordsdata for this instance can be found on the GitHub repo and the Hugging Face Space.
Lastly, we push the code to the Area similar to we might to GitHub. The top result’s a public software hosted on Hugging Face Areas.
App hyperlink: https://huggingface.co/spaces/shawhin/my-first-space
Hugging Face has grow to be synonymous with open-source language fashions and machine studying. The most important benefit of their ecosystem is it provides small-time builders, researchers, and tinkers entry to highly effective ML sources.
Whereas we coated numerous materials on this submit, we’ve solely scratched the floor of what the Hugging Face ecosystem can do. In future articles of this sequence, we’ll discover extra superior use circumstances and canopy how one can fine-tune fashions utilizing 🤗Transformers.
👉 Extra on LLMs: Introduction | OpenAI API