
Amazon Redshift is the preferred cloud information warehouse that’s utilized by tens of hundreds of consumers to investigate exabytes of knowledge every single day. Many practitioners are extending these Redshift datasets at scale for machine studying (ML) utilizing Amazon SageMaker, a totally managed ML service, with necessities to develop options offline in a code manner or low-code/no-code manner, retailer featured information from Amazon Redshift, and make this occur at scale in a manufacturing setting.
On this put up, we present you three choices to arrange Redshift supply information at scale in SageMaker, together with loading information from Amazon Redshift, performing characteristic engineering, and ingesting options into Amazon SageMaker Feature Store:
Should you’re an AWS Glue consumer and wish to do the method interactively, contemplate possibility A. Should you’re acquainted with SageMaker and writing Spark code, possibility B could possibly be your alternative. If you wish to do the method in a low-code/no-code manner, you may observe possibility C.
Amazon Redshift makes use of SQL to investigate structured and semi-structured information throughout information warehouses, operational databases, and information lakes, utilizing AWS-designed {hardware} and ML to ship the very best price-performance at any scale.
SageMaker Studio is the primary totally built-in growth setting (IDE) for ML. It supplies a single web-based visible interface the place you may carry out all ML growth steps, together with making ready information and constructing, coaching, and deploying fashions.
AWS Glue is a serverless information integration service that makes it simple to find, put together, and mix information for analytics, ML, and software growth. AWS Glue allows you to seamlessly accumulate, remodel, cleanse, and put together information for storage in your information lakes and information pipelines utilizing quite a lot of capabilities, together with built-in transforms.
Answer overview
The next diagram illustrates the answer structure for every possibility.

Conditions
To proceed with the examples on this put up, it’s good to create the required AWS assets. To do that, we offer an AWS CloudFormation template to create a stack that accommodates the assets. Whenever you create the stack, AWS creates a variety of assets in your account:
- A SageMaker area, which incorporates an related Amazon Elastic File System (Amazon EFS) quantity
- An inventory of approved customers and quite a lot of safety, software, coverage, and Amazon Virtual Private Cloud (Amazon VPC) configurations
- A Redshift cluster
- A Redshift secret
- An AWS Glue connection for Amazon Redshift
- An AWS Lambda perform to arrange required assets, execution roles and insurance policies
Just be sure you don’t have already two SageMaker Studio domains within the Area the place you’re operating the CloudFormation template. That is the utmost allowed variety of domains in every supported Area.
Deploy the CloudFormation template
Full the next steps to deploy the CloudFormation template:
- Save the CloudFormation template sm-redshift-demo-vpc-cfn-v1.yaml regionally.
- On the AWS CloudFormation console, select Create stack.
- For Put together template, choose Template is prepared.
- For Template supply, choose Add a template file.
- Select Select File and navigate to the placement in your pc the place the CloudFormation template was downloaded and select the file.
- Enter a stack title, corresponding to
Demo-Redshift. - On the Configure stack choices web page, go away all the things as default and select Subsequent.
- On the Evaluate web page, choose I acknowledge that AWS CloudFormation would possibly create IAM assets with customized names and select Create stack.
It is best to see a brand new CloudFormation stack with the title Demo-Redshift being created. Await the standing of the stack to be CREATE_COMPLETE (roughly 7 minutes) earlier than shifting on. You possibly can navigate to the stack’s Sources tab to examine what AWS assets have been created.
Launch SageMaker Studio
Full the next steps to launch your SageMaker Studio area:
- On the SageMaker console, select Domains within the navigation pane.
- Select the area you created as a part of the CloudFormation stack (
SageMakerDemoDomain). - Select Launch and Studio.
This web page can take 1–2 minutes to load if you entry SageMaker Studio for the primary time, after which you’ll be redirected to a Dwelling tab.
Obtain the GitHub repository
Full the next steps to obtain the GitHub repo:
- Within the SageMaker pocket book, on the File menu, select New and Terminal.
- Within the terminal, enter the next command:
Now you can see the amazon-sagemaker-featurestore-redshift-integration folder in navigation pane of SageMaker Studio.
Arrange batch ingestion with the Spark connector
Full the next steps to arrange batch ingestion:
- In SageMaker Studio, open the pocket book 1-uploadJar.ipynb beneath
amazon-sagemaker-featurestore-redshift-integration. - If you’re prompted to decide on a kernel, select Knowledge Science because the picture and Python 3 because the kernel, then select Choose.
- For the next notebooks, select the identical picture and kernel besides the AWS Glue Interactive Classes pocket book (4a).
- Run the cells by urgent Shift+Enter in every of the cells.
Whereas the code runs, an asterisk (*) seems between the sq. brackets. When the code is completed operating, the * shall be changed with numbers. This motion can also be workable for all different notebooks.
Arrange the schema and cargo information to Amazon Redshift
The subsequent step is to arrange the schema and cargo information from Amazon Simple Storage Service (Amazon S3) to Amazon Redshift. To take action, run the pocket book 2-loadredshiftdata.ipynb.
Create characteristic shops in SageMaker Function Retailer
To create your characteristic shops, run the pocket book 3-createFeatureStore.ipynb.
Carry out characteristic engineering and ingest options into SageMaker Function Retailer
On this part, we current the steps for all three choices to carry out characteristic engineering and ingest processed options into SageMaker Function Retailer.
Choice A: Use SageMaker Studio with a serverless AWS Glue interactive session
Full the next steps for possibility A:
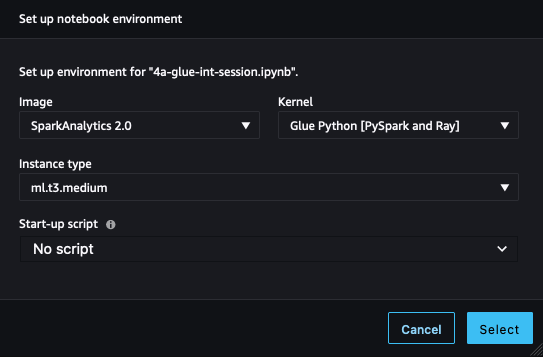
- In SageMaker Studio, open the pocket book 4a-glue-int-session.ipynb.
- If you’re prompted to decide on a kernel, select SparkAnalytics 2.0 because the picture and Glue Python [PySpark and Ray] because the kernel, then select Choose.
The setting preparation course of might take a while to finish.
Choice B: Use a SageMaker Processing job with Spark
On this possibility, we use a SageMaker Processing job with a Spark script to load the unique dataset from Amazon Redshift, carry out characteristic engineering, and ingest the information into SageMaker Function Retailer. To take action, open the pocket book 4b-processing-rs-to-fs.ipynb in your SageMaker Studio setting.
Right here we use RedshiftDatasetDefinition to retrieve the dataset from the Redshift cluster. RedshiftDatasetDefinition is one sort of enter of the processing job, which supplies a easy interface for practitioners to configure Redshift connection-related parameters corresponding to identifier, database, desk, question string, and extra. You possibly can simply set up your Redshift connection utilizing RedshiftDatasetDefinition with out sustaining a connection full time. We additionally use the SageMaker Feature Store Spark connector library within the processing job to hook up with SageMaker Function Retailer in a distributed setting. With this Spark connector, you may simply ingest information to the characteristic group’s on-line and offline retailer from a Spark DataFrame. Additionally, this connector accommodates the performance to robotically load characteristic definitions to assist with creating characteristic teams. Above all, this resolution provides you a local Spark method to implement an end-to-end information pipeline from Amazon Redshift to SageMaker. You possibly can carry out any characteristic engineering in a Spark context and ingest closing options into SageMaker Function Retailer in only one Spark venture.
To make use of the SageMaker Function Retailer Spark connector, we lengthen a pre-built SageMaker Spark container with sagemaker-feature-store-pyspark put in. Within the Spark script, use the system executable command to run pip set up, set up this library in your native setting, and get the native path of the JAR file dependency. Within the processing job API, present this path to the parameter of submit_jars to the node of the Spark cluster that the processing job creates.
Within the Spark script for the processing job, we first learn the unique dataset information from Amazon S3, which quickly shops the unloaded dataset from Amazon Redshift as a medium. Then we carry out characteristic engineering in a Spark manner and use feature_store_pyspark to ingest information into the offline characteristic retailer.
For the processing job, we offer a ProcessingInput with a redshift_dataset_definition. Right here we construct a construction based on the interface, offering Redshift connection-related configurations. You should utilize query_string to filter your dataset by SQL and unload it to Amazon S3. See the next code:
It’s good to wait 6–7 minutes for every processing job together with USER, PLACE, and RATING datasets.
For extra particulars about SageMaker Processing jobs, consult with Process data.
For SageMaker native options for characteristic processing from Amazon Redshift, you may also use Feature Processing in SageMaker Function Retailer, which is for underlying infrastructure together with provisioning the compute environments and creating and sustaining SageMaker pipelines to load and ingest information. You possibly can solely focus in your characteristic processor definitions that embrace transformation features, the supply of Amazon Redshift, and the sink of SageMaker Function Retailer. The scheduling, job administration, and different workloads in manufacturing are managed by SageMaker. Function Processor pipelines are SageMaker pipelines, so the standard monitoring mechanisms and integrations can be found.
Choice C: Use SageMaker Knowledge Wrangler
SageMaker Knowledge Wrangler means that you can import information from numerous information sources together with Amazon Redshift for a low-code/no-code method to put together, remodel, and featurize your information. After you end information preparation, you should use SageMaker Knowledge Wrangler to export options to SageMaker Function Retailer.
There are some AWS Identity and Access Management (IAM) settings that enable SageMaker Knowledge Wrangler to hook up with Amazon Redshift. First, create an IAM function (for instance, redshift-s3-dw-connect) that features an Amazon S3 entry coverage. For this put up, we hooked up the AmazonS3FullAccess coverage to the IAM function. When you’ve got restrictions of accessing a specified S3 bucket, you may outline it within the Amazon S3 entry coverage. We hooked up the IAM function to the Redshift cluster that we created earlier. Subsequent, create a coverage for SageMaker to entry Amazon Redshift by getting its cluster credentials, and connect the coverage to the SageMaker IAM function. The coverage seems like the next code:
After this setup, SageMaker Knowledge Wrangler means that you can question Amazon Redshift and output the outcomes into an S3 bucket. For directions to hook up with a Redshift cluster and question and import information from Amazon Redshift to SageMaker Knowledge Wrangler, consult with Import data from Amazon Redshift.
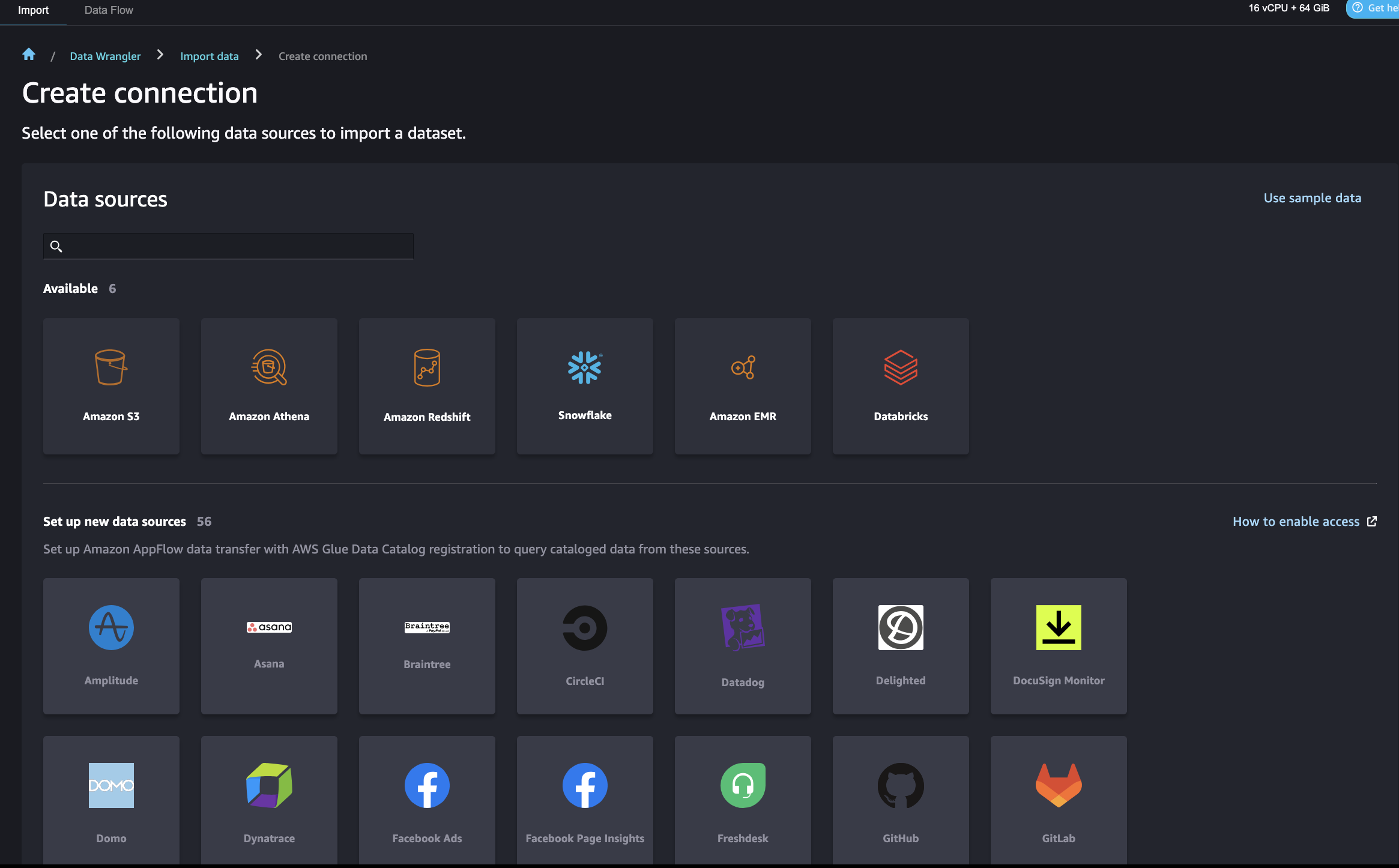
SageMaker Knowledge Wrangler provides a choice of over 300 pre-built information transformations for frequent use circumstances corresponding to deleting duplicate rows, imputing lacking information, one-hot encoding, and dealing with time sequence information. It’s also possible to add customized transformations in pandas or PySpark. In our instance, we utilized some transformations corresponding to drop column, information sort enforcement, and ordinal encoding to the information.
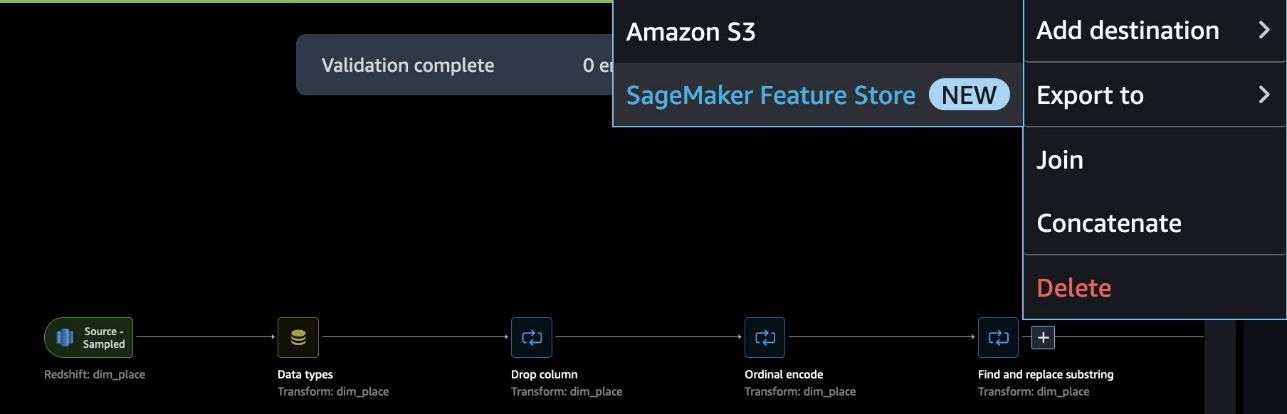
When your information movement is full, you may export it to SageMaker Function Retailer. At this level, it’s good to create a characteristic group: give the characteristic group a reputation, choose each on-line and offline storage, present the title of a S3 bucket to make use of for the offline retailer, and supply a task that has SageMaker Function Retailer entry. Lastly, you may create a job, which creates a SageMaker Processing job that runs the SageMaker Knowledge Wrangler movement to ingest options from the Redshift information supply to your characteristic group.

Right here is one end-to-end information movement within the situation of PLACE characteristic engineering.
Use SageMaker Function Retailer for mannequin coaching and prediction
To make use of SageMaker Function retailer for mannequin coaching and prediction, open the pocket book 5-classification-using-feature-groups.ipynb.
After the Redshift information is reworked into options and ingested into SageMaker Function Retailer, the options can be found for search and discovery throughout groups of knowledge scientists liable for many impartial ML fashions and use circumstances. These groups can use the options for modeling with out having to rebuild or rerun characteristic engineering pipelines. Function teams are managed and scaled independently, and could be reused and joined collectively whatever the upstream information supply.
The subsequent step is to construct ML fashions utilizing options chosen from one or a number of characteristic teams. You determine which characteristic teams to make use of in your fashions. There are two choices to create an ML dataset from characteristic teams, each using the SageMaker Python SDK:
- Use the SageMaker Function Retailer DatasetBuilder API – The SageMaker Function Retailer
DatasetBuilderAPI permits information scientists create ML datasets from a number of characteristic teams within the offline retailer. You should utilize the API to create a dataset from a single or a number of characteristic teams, and output it as a CSV file or a pandas DataFrame. See the next instance code:
- Run SQL queries utilizing the athena_query perform within the FeatureGroup API – An alternative choice is to make use of the auto-built AWS Glue Knowledge Catalog for the FeatureGroup API. The FeatureGroup API consists of an
Athena_queryperform that creates an AthenaQuery occasion to run user-defined SQL question strings. You then run the Athena question and arrange the question end result right into a pandas DataFrame. This feature means that you can specify extra sophisticated SQL queries to extract data from a characteristic group. See the next instance code:
Subsequent, we will merge the queried information from completely different characteristic teams into our closing dataset for mannequin coaching and testing. For this put up, we use batch transform for mannequin inference. Batch remodel means that you can get mannequin inferene on a bulk of knowledge in Amazon S3, and its inference result’s saved in Amazon S3 as effectively. For particulars on mannequin coaching and inference, consult with the pocket book 5-classification-using-feature-groups.ipynb.
Run a be a part of question on prediction leads to Amazon Redshift
Lastly, we question the inference end result and be a part of it with unique consumer profiles in Amazon Redshift. To do that, we use Amazon Redshift Spectrum to hitch batch prediction leads to Amazon S3 with the unique Redshift information. For particulars, consult with the pocket book run 6-read-results-in-redshift.ipynb.
Clear up
On this part, we offer the steps to scrub up the assets created as a part of this put up to keep away from ongoing expenses.
Shut down SageMaker Apps
Full the next steps to close down your assets:
- In SageMaker Studio, on the File menu, select Shut Down.
- Within the Shutdown affirmation dialog, select Shutdown All to proceed.
- After you get the “Server stopped” message, you may shut this tab.
Delete the apps
Full the next steps to delete your apps:
- On the SageMaker console, within the navigation pane, select Domains.
- On the Domains web page, select
SageMakerDemoDomain. - On the area particulars web page, beneath Consumer profiles, select the consumer
sagemakerdemouser. - Within the Apps part, within the Motion column, select Delete app for any lively apps.
- Be sure that the Standing column says Deleted for all of the apps.
Delete the EFS storage quantity related together with your SageMaker area
Find your EFS quantity on the SageMaker console and delete it. For directions, consult with Manage Your Amazon EFS Storage Volume in SageMaker Studio.
Delete default S3 buckets for SageMaker
Delete the default S3 buckets (sagemaker-<region-code>-<acct-id>) for SageMaker If you’re not utilizing SageMaker in that Area.
Delete the CloudFormation stack
Delete the CloudFormation stack in your AWS account in order to scrub up all associated assets.
Conclusion
On this put up, we demonstrated an end-to-end information and ML movement from a Redshift information warehouse to SageMaker. You possibly can simply use AWS native integration of purpose-built engines to undergo the information journey seamlessly. Take a look at the AWS Blog for extra practices about constructing ML options from a contemporary information warehouse.
Concerning the Authors
 Akhilesh Dube, a Senior Analytics Options Architect at AWS, possesses greater than 20 years of experience in working with databases and analytics merchandise. His main function includes collaborating with enterprise shoppers to design sturdy information analytics options whereas providing complete technical steerage on a variety of AWS Analytics and AI/ML providers.
Akhilesh Dube, a Senior Analytics Options Architect at AWS, possesses greater than 20 years of experience in working with databases and analytics merchandise. His main function includes collaborating with enterprise shoppers to design sturdy information analytics options whereas providing complete technical steerage on a variety of AWS Analytics and AI/ML providers.
 Ren Guo is a Senior Knowledge Specialist Options Architect within the domains of generative AI, analytics, and conventional AI/ML at AWS, Larger China Area.
Ren Guo is a Senior Knowledge Specialist Options Architect within the domains of generative AI, analytics, and conventional AI/ML at AWS, Larger China Area.
 Sherry Ding is a Senior AI/ML Specialist Options Architect. She has intensive expertise in machine studying with a PhD diploma in Laptop Science. She primarily works with Public Sector clients on numerous AI/ML-related enterprise challenges, serving to them speed up their machine studying journey on the AWS Cloud. When not serving to clients, she enjoys out of doors actions.
Sherry Ding is a Senior AI/ML Specialist Options Architect. She has intensive expertise in machine studying with a PhD diploma in Laptop Science. She primarily works with Public Sector clients on numerous AI/ML-related enterprise challenges, serving to them speed up their machine studying journey on the AWS Cloud. When not serving to clients, she enjoys out of doors actions.
 Mark Roy is a Principal Machine Studying Architect for AWS, serving to clients design and construct AI/ML options. Mark’s work covers a variety of ML use circumstances, with a main curiosity in pc imaginative and prescient, deep studying, and scaling ML throughout the enterprise. He has helped corporations in lots of industries, together with insurance coverage, monetary providers, media and leisure, healthcare, utilities, and manufacturing. Mark holds six AWS Certifications, together with the ML Specialty Certification. Previous to becoming a member of AWS, Mark was an architect, developer, and know-how chief for over 25 years, together with 19 years in monetary providers.
Mark Roy is a Principal Machine Studying Architect for AWS, serving to clients design and construct AI/ML options. Mark’s work covers a variety of ML use circumstances, with a main curiosity in pc imaginative and prescient, deep studying, and scaling ML throughout the enterprise. He has helped corporations in lots of industries, together with insurance coverage, monetary providers, media and leisure, healthcare, utilities, and manufacturing. Mark holds six AWS Certifications, together with the ML Specialty Certification. Previous to becoming a member of AWS, Mark was an architect, developer, and know-how chief for over 25 years, together with 19 years in monetary providers.

