
Open-source giant language fashions (LLMs) have grow to be in style, permitting researchers, builders, and organizations to entry these fashions to foster innovation and experimentation. This encourages collaboration from the open-source group to contribute to developments and enchancment of LLMs. Open-source LLMs present transparency to the mannequin structure, coaching course of, and coaching knowledge, which permits researchers to grasp how the mannequin works and establish potential biases and handle moral considerations. These open-source LLMs are democratizing generative AI by making superior pure language processing (NLP) expertise obtainable to a variety of customers to construct mission-critical enterprise purposes. GPT-NeoX, LLaMA, Alpaca, GPT4All, Vicuna, Dolly, and OpenAssistant are a few of the in style open-source LLMs.
OpenChatKit is an open-source LLM used to construct general-purpose and specialised chatbot purposes, launched by Collectively Laptop in March 2023 below the Apache-2.0 license. This mannequin permits builders to have extra management over the chatbot’s conduct and tailor it to their particular purposes. OpenChatKit gives a set of instruments, base bot, and constructing blocks to construct absolutely custom-made, highly effective chatbots. The important thing parts are as follows:
- An instruction-tuned LLM, fine-tuned for chat from EleutherAI’s GPT-NeoX-20B with over 43 million directions on 100% carbon unfavourable compute. The
GPT-NeoXT-Chat-Base-20Bmannequin is predicated on EleutherAI’s GPT-NeoX mannequin, and is fine-tuned with knowledge specializing in dialog-style interactions. - Customization recipes to fine-tune the mannequin to realize excessive accuracy in your duties.
- An extensible retrieval system enabling you to reinforce bot responses with info from a doc repository, API, or different live-updating info supply at inference time.
- A moderation mannequin, fine-tuned from GPT-JT-6B, designed to filter which questions the bot responds to.
The growing scale and measurement of deep studying fashions current obstacles to efficiently deploy these fashions in generative AI purposes. To satisfy the calls for for low latency and excessive throughput, it turns into important to make use of subtle strategies like mannequin parallelism and quantization. Missing proficiency within the software of those strategies, quite a few customers encounter difficulties in initiating the internet hosting of sizable fashions for generative AI use instances.
On this put up, we present the way to deploy OpenChatKit fashions (GPT-NeoXT-Chat-Base-20B and GPT-JT-Moderation-6B) fashions on Amazon SageMaker utilizing DJL Serving and open-source mannequin parallel libraries like DeepSpeed and Hugging Face Speed up. We use DJL Serving, which is a high-performance common mannequin serving answer powered by the Deep Java Library (DJL) that’s programming language agnostic. We exhibit how the Hugging Face Speed up library simplifies deployment of huge fashions into a number of GPUs, thereby decreasing the burden of working LLMs in a distributed vogue. Let’s get began!
Extensible retrieval system
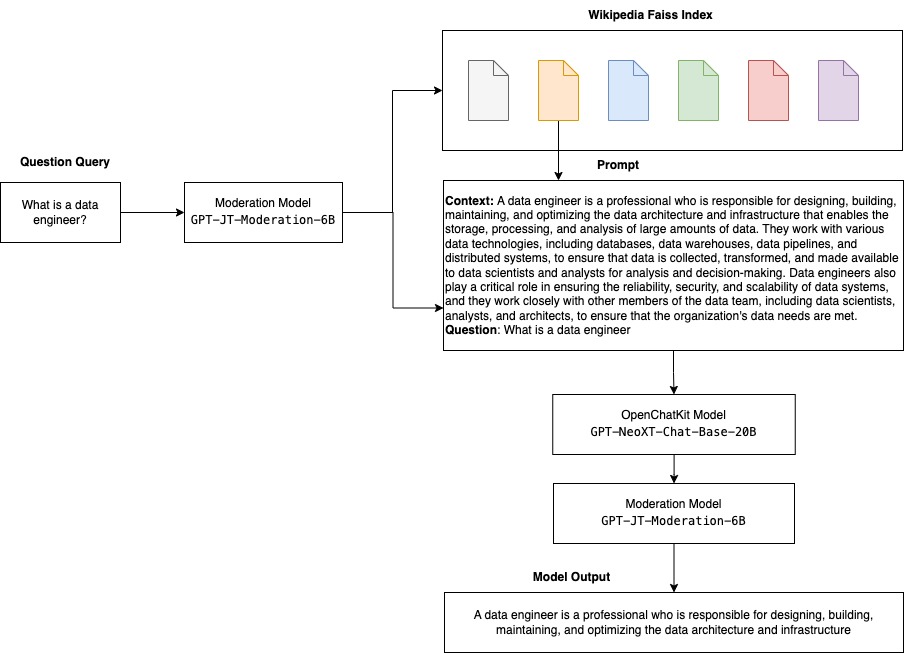
An extensible retrieval system is among the key parts of OpenChatKit. It lets you customise the bot response based mostly on a closed area data base. Though LLMs are capable of retain factual data of their mannequin parameters and might obtain outstanding efficiency on downstream NLP duties when fine-tuned, their capability to entry and predict closed area data precisely stays restricted. Due to this fact, once they’re introduced with knowledge-intensive duties, their efficiency suffers to that of task-specific architectures. You need to use the OpenChatKit retrieval system to reinforce data of their responses from exterior data sources comparable to Wikipedia, doc repositories, APIs, and different info sources.
The retrieval system permits the chatbot to entry present info by acquiring pertinent particulars in response to a selected question, thereby supplying the required context for the mannequin to generate solutions. As an example the performance of this retrieval system, we offer assist for an index of Wikipedia articles and supply instance code demonstrating the way to invoke an online search API for info retrieval. By following the supplied documentation, you possibly can combine the retrieval system with any dataset or API in the course of the inference course of, permitting the chatbot to include dynamically up to date knowledge into its responses.
Moderation mannequin
Moderation fashions are vital in chatbot purposes to implement content material filtering, high quality management, person security, and authorized and compliance causes. Moderation is a troublesome and subjective process, and relies upon quite a bit on the area of the chatbot software. OpenChatKit gives instruments to reasonable the chatbot software and monitor enter textual content prompts for any inappropriate content material. The moderation mannequin gives a superb baseline that may be tailored and customised to varied wants.
OpenChatKit has a 6-billion-parameter moderation mannequin, GPT-JT-Moderation-6B, which may reasonable the chatbot to restrict the inputs to the moderated topics. Though the mannequin itself does have some moderation inbuilt, TogetherComputer skilled a GPT-JT-Moderation-6B mannequin with Ontocord.ai’s OIG-moderation dataset. This mannequin runs alongside the principle chatbot to verify that each the person enter and reply from the bot don’t comprise inappropriate outcomes. You too can use this to detect any out of area inquiries to the chatbot and override when the query isn’t a part of the chatbot’s area.
The next diagram illustrates the OpenChatKit workflow.
Extensible retrieval system use instances
Though we are able to apply this method in numerous industries to construct generative AI purposes, for this put up we talk about use instances within the monetary business. Retrieval augmented technology may be employed in monetary analysis to mechanically generate analysis studies on particular corporations, industries, or monetary merchandise. By retrieving related info from inside data bases, monetary archives, information articles, and analysis papers, you possibly can generate complete studies that summarize key insights, monetary metrics, market developments, and funding suggestions. You need to use this answer to watch and analyze monetary information, market sentiment, and developments.
Resolution overview
The next steps are concerned to construct a chatbot utilizing OpenChatKit fashions and deploy them on SageMaker:
- Obtain the chat base
GPT-NeoXT-Chat-Base-20Bmannequin and package deal the mannequin artifacts to be uploaded to Amazon Simple Storage Service (Amazon S3). - Use a SageMaker giant mannequin inference (LMI) container, configure the properties, and arrange customized inference code to deploy this mannequin.
- Configure mannequin parallel methods and use inference optimization libraries in DJL serving properties. We’ll use Hugging Face Speed up because the engine for DJL serving. Moreover, we outline tensor parallel configurations to partition the mannequin.
- Create a SageMaker mannequin and endpoint configuration, and deploy the SageMaker endpoint.
You’ll be able to comply with alongside by working the pocket book within the GitHub repo.
Obtain the OpenChatKit mannequin
First, we obtain the OpenChatKit base mannequin. We use huggingface_hub and use snapshot_download to obtain the mannequin, which downloads a whole repository at a given revision. Downloads are made concurrently to hurry up the method. See the next code:
DJL Serving properties
You need to use SageMaker LMI containers to host giant generative AI fashions with customized inference code with out offering your individual inference code. That is extraordinarily helpful when there isn’t a customized preprocessing of the enter knowledge or postprocessing of the mannequin’s predictions. You too can deploy a mannequin utilizing customized inference code. On this put up, we exhibit the way to deploy OpenChatKit fashions with customized inference code.
SageMaker expects the mannequin artifacts in tar format. We create every OpenChatKit mannequin with the next information: serving.properties and mannequin.py.
The serving.properties configuration file signifies to DJL Serving which mannequin parallelization and inference optimization libraries you wish to use. The next is a listing of settings we use on this configuration file:
This incorporates the next parameters:
- engine – The engine for DJL to make use of.
- choice.entryPoint – The entry level Python file or module. This could align with the engine that’s getting used.
- choice.s3url – Set this to the URI of the S3 bucket that incorporates the mannequin.
- choice.modelid – If you wish to obtain the mannequin from huggingface.co, you possibly can set
choice.modelidto the mannequin ID of a pretrained mannequin hosted inside a mannequin repository on huggingface.co (https://huggingface.co/models). The container makes use of this mannequin ID to obtain the corresponding mannequin repository on huggingface.co. - choice.tensor_parallel_degree – Set this to the variety of GPU units over which DeepSpeed must partition the mannequin. This parameter additionally controls the variety of employees per mannequin that can be began up when DJL Serving runs. For instance, if we’ve got an 8 GPU machine and we’re creating eight partitions, then we can have one employee per mannequin to serve the requests. It’s essential to tune the parallelism diploma and establish the optimum worth for a given mannequin structure and {hardware} platform. We name this means inference-adapted parallelism.
Seek advice from Configurations and settings for an exhaustive checklist of choices.
OpenChatKit fashions
The OpenChatKit base mannequin implementation has the next 4 information:
- mannequin.py – This file implements the dealing with logic for the principle OpenChatKit GPT-NeoX mannequin. It receives the inference enter request, masses the mannequin, masses the Wikipedia index, and serves the response. Seek advice from
mannequin.py(created a part of the pocket book) for added particulars.mannequin.pymakes use of the next key lessons:- OpenChatKitService – This handles passing the information between the GPT-NeoX mannequin, Faiss search, and dialog object.
WikipediaIndexandDialogobjects are initialized and enter chat conversations are despatched to the index to seek for related content material from Wikipedia. This additionally generates a singular ID for every invocation if one isn’t provided for the aim of storing the prompts in Amazon DynamoDB. - ChatModel – This class masses the mannequin and tokenizer and generates the response. It handles partitioning the mannequin throughout a number of GPUs utilizing
tensor_parallel_degree, and configures thedtypesanddevice_map. The prompts are handed to the mannequin to generate responses. A stopping standardsStopWordsCriteriais configured for the technology to solely produce the bot response on inference. - ModerationModel – We use two moderation fashions within the
ModerationModelclass: the enter mannequin to point to the chat mannequin that the enter is inappropriate to override the inference outcome, and the output mannequin to override the inference outcome. We classify the enter immediate and output response with the next potential labels:- informal
- wants warning
- wants intervention (that is flagged to be moderated by the mannequin)
- probably wants warning
- in all probability wants warning
- OpenChatKitService – This handles passing the information between the GPT-NeoX mannequin, Faiss search, and dialog object.
- wikipedia_prepare.py – This file handles downloading and getting ready the Wikipedia index. On this put up, we use a Wikipedia index supplied on Hugging Face datasets. To look the Wikipedia paperwork for related textual content, the index must be downloaded from Hugging Face as a result of it’s not packaged elsewhere. The
wikipedia_prepare.pyfile is liable for dealing with the obtain when imported. Solely a single course of within the a number of which might be working for inference can clone the repository. The remaining wait till the information are current within the native file system. - wikipedia.py – This file is used for looking the Wikipedia index for contextually related paperwork. The enter question is tokenized and embeddings are created utilizing
mean_pooling. We compute cosine similarity distance metrics between the question embedding and the Wikipedia index to retrieve contextually related Wikipedia sentences. Seek advice fromwikipedia.pyfor implementation particulars.
- dialog.py – This file is used for storing and retrieving the dialog thread in DynamoDB for passing to the mannequin and person.
dialog.pyis tailored from the open-source OpenChatKit repository. This file is liable for defining the thing that shops the dialog turns between the human and the mannequin. With this, the mannequin is ready to retain a session for the dialog, permitting a person to confer with earlier messages. As a result of SageMaker endpoint invocations are stateless, this dialog must be saved in a location exterior to the endpoint cases. On startup, the occasion creates a DynamoDB desk if it doesn’t exist. All updates to the dialog are then saved in DynamoDB based mostly on thesession_idkey, which is generated by the endpoint. Any invocation with a session ID will retrieve the related dialog string and replace it as required.
Construct an LMI inference container with customized dependencies
The index search makes use of Fb’s Faiss library for performing the similarity search. As a result of this isn’t included within the base LMI picture, the container must be tailored to put in this library. The next code defines a Dockerfile that installs Faiss from the supply alongside different libraries wanted by the bot endpoint. We use the sm-docker utility to construct and push the picture to Amazon Elastic Container Registry (Amazon ECR) from Amazon SageMaker Studio. Seek advice from Using the Amazon SageMaker Studio Image Build CLI to build container images from your Studio notebooks for extra particulars.
The DJL container doesn’t have Conda put in, so Faiss must be cloned and compiled from the supply. To put in Faiss, the dependencies for utilizing the BLAS APIs and Python assist have to be put in. After these packages are put in, Faiss is configured to make use of AVX2 and CUDA earlier than being compiled with the Python extensions put in.
pandas, fastparquet, boto3, and git-lfs are put in afterwards as a result of these are required for downloading and studying the index information.
Create the mannequin
Now that we’ve got the Docker picture in Amazon ECR, we are able to proceed with creating the SageMaker mannequin object for the OpenChatKit fashions. We deploy GPT-NeoXT-Chat-Base-20B enter and output moderation fashions utilizing GPT-JT-Moderation-6B. Seek advice from create_model for extra particulars.
Configure the endpoint
Subsequent, we outline the endpoint configurations for the OpenChatKit fashions. We deploy the fashions utilizing the ml.g5.12xlarge occasion sort. Seek advice from create_endpoint_config for extra particulars.
Deploy the endpoint
Lastly, we create an endpoint utilizing the mannequin and endpoint configuration we outlined within the earlier steps:
Run inference from OpenChatKit fashions
Now it’s time to ship inference requests to the mannequin and get the responses. We go the enter textual content immediate and mannequin parameters comparable to temperature, top_k, and max_new_tokens. The standard of the chatbot responses is predicated on the parameters specified, so it’s advisable to benchmark mannequin efficiency towards these parameters to seek out the optimum setting in your use case. The enter immediate is first despatched to the enter moderation mannequin, and the output is distributed to ChatModel to generate the responses. Throughout this step, the mannequin makes use of the Wikipedia index to retrieve contextually related sections to the mannequin because the immediate to get domain-specific responses from the mannequin. Lastly, the mannequin response is distributed to the output moderation mannequin to verify for classification, after which the responses are returned. See the next code:
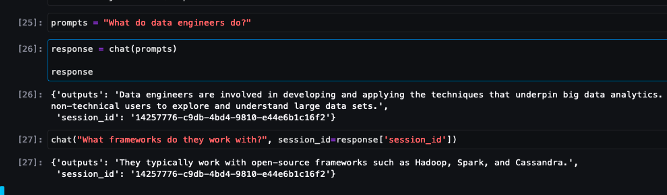
Seek advice from pattern chat interactions under.
Clear up
Observe the directions within the cleanup part of the to delete the sources provisioned as a part of this put up to keep away from pointless prices. Seek advice from Amazon SageMaker Pricing for particulars about the price of the inference cases.
Conclusion
On this put up, we mentioned the significance of open-source LLMs and the way to deploy an OpenChatKit mannequin on SageMaker to construct next-generation chatbot purposes. We mentioned numerous parts of OpenChatKit fashions, moderation fashions, and the way to use an exterior data supply like Wikipedia for retrieval augmented technology (RAG) workflows. You could find step-by-step directions within the GitHub notebook. Tell us concerning the superb chatbot purposes you’re constructing. Cheers!
Concerning the Authors
 Dhawal Patel is a Principal Machine Studying Architect at AWS. He has labored with organizations starting from giant enterprises to mid-sized startups on issues associated to distributed computing, and Synthetic Intelligence. He focuses on Deep studying together with NLP and Laptop Imaginative and prescient domains. He helps clients obtain excessive efficiency mannequin inference on SageMaker.
Dhawal Patel is a Principal Machine Studying Architect at AWS. He has labored with organizations starting from giant enterprises to mid-sized startups on issues associated to distributed computing, and Synthetic Intelligence. He focuses on Deep studying together with NLP and Laptop Imaginative and prescient domains. He helps clients obtain excessive efficiency mannequin inference on SageMaker.
 Vikram Elango is a Sr. AIML Specialist Options Architect at AWS, based mostly in Virginia, US. He’s presently targeted on generative AI, LLMs, immediate engineering, giant mannequin inference optimization, and scaling ML throughout enterprises. Vikram helps monetary and insurance coverage business clients with design and thought management to construct and deploy machine studying purposes at scale. In his spare time, he enjoys touring, mountain climbing, cooking, and tenting along with his household.
Vikram Elango is a Sr. AIML Specialist Options Architect at AWS, based mostly in Virginia, US. He’s presently targeted on generative AI, LLMs, immediate engineering, giant mannequin inference optimization, and scaling ML throughout enterprises. Vikram helps monetary and insurance coverage business clients with design and thought management to construct and deploy machine studying purposes at scale. In his spare time, he enjoys touring, mountain climbing, cooking, and tenting along with his household.
 Andrew Smith is a Cloud Help Engineer within the SageMaker, Imaginative and prescient & Different group at AWS, based mostly in Sydney, Australia. He helps clients utilizing many AI/ML companies on AWS with experience in working with Amazon SageMaker. Outdoors of labor, he enjoys spending time with family and friends in addition to studying about completely different applied sciences.
Andrew Smith is a Cloud Help Engineer within the SageMaker, Imaginative and prescient & Different group at AWS, based mostly in Sydney, Australia. He helps clients utilizing many AI/ML companies on AWS with experience in working with Amazon SageMaker. Outdoors of labor, he enjoys spending time with family and friends in addition to studying about completely different applied sciences.

