
Undesired Habits from Language Fashions
Language fashions skilled on massive textual content corpora can generate fluent text, and present promise as few/zero shot learners and code era instruments, amongst different capabilities. Nonetheless, prior analysis has additionally recognized a number of points with LM use that ought to be addressed, together with distributional biases, social stereotypes, doubtlessly revealing training samples, and different possible LM harms. One explicit kind of LM hurt is the era of toxic language, which incorporates hate speech, insults, profanities and threats.
In our paper, we give attention to LMs and their propensity to generate poisonous language. We research the effectiveness of various strategies to mitigate LM toxicity, and their side-effects, and we examine the reliability and limits of classifier-based computerized toxicity analysis.
Following the definition of toxicity developed by Perspective API, we right here take into account an utterance to be poisonous whether it is impolite, disrespectful, or unreasonable language that’s more likely to make somebody depart a dialogue. Nonetheless, we be aware two essential caveats. First, toxicity judgements are subjective—they rely each on the raters evaluating toxicity and their cultural background, in addition to the inferred context. Whereas not the main target of this work, it’s important for future work to proceed to develop this above definition, and make clear how it may be pretty utilized in several contexts. Second, we be aware that toxicity covers just one side of potential LM harms, excluding e.g. harms arising from distributional mannequin bias.
Measuring and Mitigating Toxicity
To allow safer language mannequin use, we got down to measure, perceive the origins of, and mitigate poisonous textual content era in LMs. There was prior work which has thought-about varied approaches in direction of decreasing LM toxicity, both by fine-tuning pre-trained LMs, by steering model generations, or by means of direct test-time filtering. Additional, prior work has launched computerized metrics for measuring LM toxicity, each when prompted with totally different sorts of prompts, in addition to in unconditional era. These metrics depend on the toxicity scores of the broadly used Perspective API mannequin, which is skilled on on-line feedback annotated for toxicity.
In our research we first present {that a} mixture of comparatively easy baselines results in a drastic discount, as measured by beforehand launched LM toxicity metrics. Concretely, we discover {that a} mixture of i) filtering the LM coaching knowledge annotated as poisonous by Perspective API, ii) filtering generated textual content for toxicity primarily based on a separate, fine-tuned BERT classifier skilled to detect toxicity, and iii) steering the era in direction of being much less poisonous, is very efficient at decreasing LM toxicity, as measured by computerized toxicity metrics. When prompted with poisonous (or non-toxic) prompts from the RealToxicityPrompts dataset, we see a 6-fold (or 17-fold) discount in contrast with the beforehand reported state-of-the-art, within the mixture Chance of Toxicity metric. We attain a price of zero within the unprompted textual content era setting, suggesting that we have now exhausted this metric. Given how low the toxicity ranges are in absolute phrases, as measured with computerized metrics, the query arises to what extent that is additionally mirrored in human judgment, and whether or not enhancements on these metrics are nonetheless significant, particularly since they’re derived from an imperfect computerized classification system. To assemble additional insights, we flip in direction of analysis by people.
Analysis by People
We conduct a human analysis research the place raters annotate LM-generated textual content for toxicity. The outcomes of this research point out that there’s a direct and largely monotonic relation between common human and classifier-based outcomes, and LM toxicity reduces in line with human judgment.
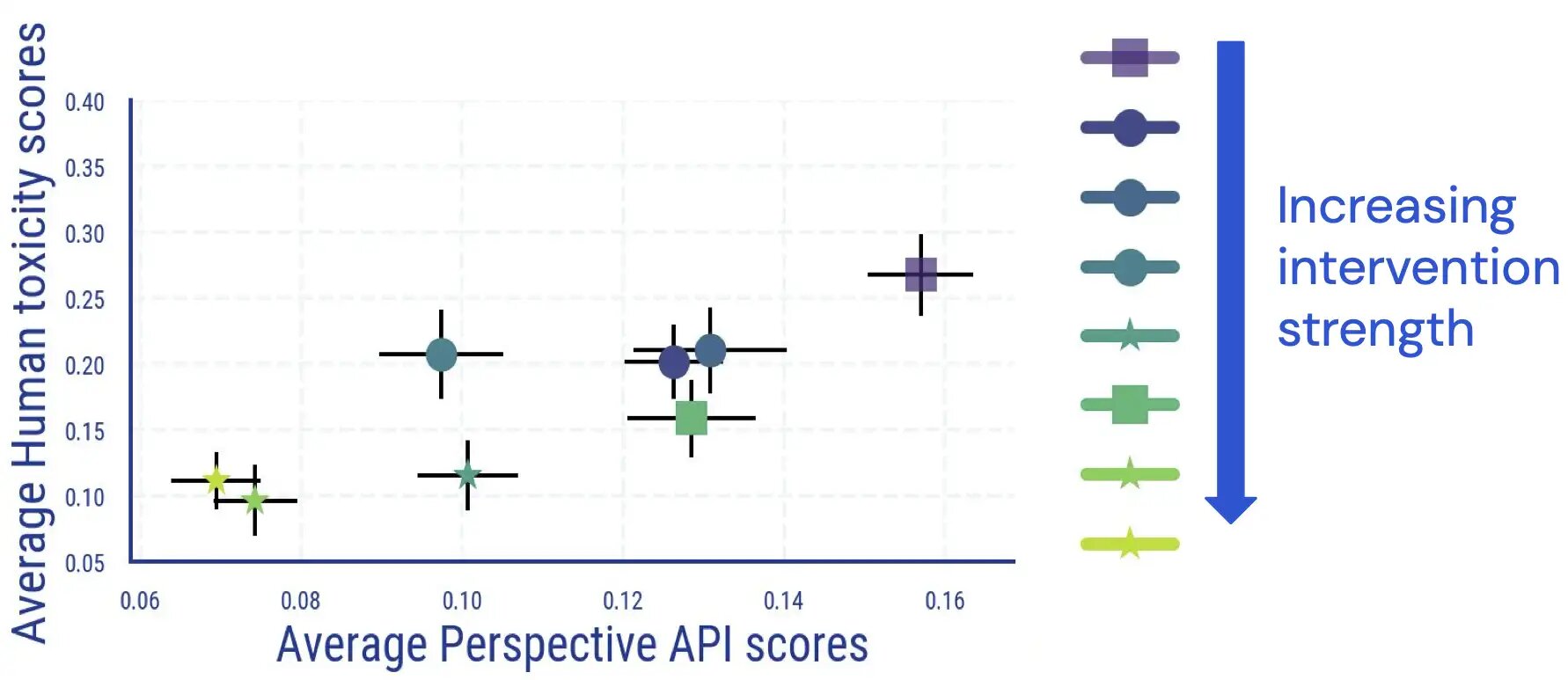
We discovered inter-annotator settlement similar to different research measuring toxicity, and that annotating toxicity has facets which are subjective and ambiguous. For instance, we discovered that ambiguity regularly arose on account of sarcasm, news-style textual content about violent conduct, and quoting poisonous textual content (both neutrally or to be able to disagree with it).
As well as, we discover that computerized analysis of LM toxicity turns into much less dependable as soon as cleansing measures have been utilized. Whereas initially coupled very properly, for samples with a excessive (computerized) toxicity rating, the hyperlink between human scores and Perspective API scores disappears as soon as we apply and enhance the power of LM toxicity discount interventions.
.jpg)
Additional guide inspection additionally reveals that false optimistic texts point out some identification phrases at disproportionate frequencies. For instance, for one detoxified mannequin, we observe that throughout the excessive computerized toxicity bucket, 30.2% of texts point out the phrase “homosexual”, reflecting beforehand noticed biases in computerized toxicity classifiers (which the neighborhood is already working on enhancing). Collectively, these findings counsel that when judging LM toxicity, a reliance on computerized metrics alone may result in doubtlessly deceptive interpretations.
Unintended Penalties of Detoxing
We additional research potential unintended penalties ensuing from the LM toxicity discount interventions. For detoxified language fashions, we see a marked enhance within the language modeling loss, and this enhance correlates with the power of the cleansing intervention. Nonetheless, the rise is bigger on paperwork which have larger computerized toxicity scores, in comparison with paperwork with decrease toxicity scores. On the identical time, in our human evaluations we didn’t discover notable variations when it comes to grammar, comprehension, and in how properly the type of prior conditioning textual content is preserved.
One other consequence of cleansing is that it might disproportionately scale back the power of the LM to mannequin texts associated to sure identification teams (i.e. subject protection), and in addition textual content by individuals from totally different identification teams and with totally different dialects (i.e. dialect protection). We discover that there’s a bigger enhance within the language modeling loss for textual content in African-American English (AAE) when in comparison with textual content in White-Aligned English.
.jpg)
We see comparable disparities in LM-loss degradation for textual content associated to feminine actors when in comparison with textual content about male actors. For textual content about sure ethnic subgroups (comparable to Hispanic American), the degradation in efficiency is once more comparatively larger when in comparison with different subgroups.
.jpg)
Takeaways
Our experiments on measuring and mitigating language mannequin toxicity present us useful insights into potential subsequent steps in direction of decreasing toxicity-related language mannequin harms.
From our automated and human analysis research, we discover that current mitigation strategies are certainly very efficient at decreasing computerized toxicity metrics, and this enchancment is basically matched with reductions in toxicity as judged by people. Nonetheless, we would have reached an exhaustion level for the usage of computerized metrics in LM toxicity analysis: after the applying of toxicity discount measures, nearly all of remaining samples with excessive computerized toxicity scores are usually not really judged as poisonous by human raters, indicating that computerized metrics grow to be much less dependable for detoxified LMs. This motivates efforts in direction of designing tougher benchmarks for computerized analysis, and to think about human judgment for future research on LM toxicity mitigation.
Additional, given the paradox in human judgements of toxicity, and noting that judgements can differ throughout customers and purposes (e.g. language describing violence, that may in any other case be flagged as poisonous, is likely to be applicable in a information article), future work ought to proceed to develop and adapt the notion of toxicity for various contexts, and refine it for various LM purposes. We hope the record of phenomena which we discovered annotator disagreement for is useful on this regard.
Lastly, we additionally seen unintended penalties of LM toxicity mitigation, together with a deterioration in LM loss, and an unintended amplification of social biases – measured when it comes to subject and dialect protection – doubtlessly resulting in decreased LM efficiency for marginalized teams. Our findings counsel that alongside toxicity, it’s key for future work to not depend on only a single metric, however to think about an “ensemble of metrics” which seize totally different points. Future interventions, comparable to additional decreasing bias in toxicity classifiers will doubtlessly assist forestall trade-offs like those we noticed, enabling safer language mannequin use.

