The video gaming trade has an estimated person base of over 3 billion worldwide1. It consists of large quantities of gamers nearly interacting with one another each single day. Sadly, as in the true world, not all gamers talk appropriately and respectfully. In an effort to create and preserve a socially accountable gaming atmosphere, AWS Skilled Providers was requested to construct a mechanism that detects inappropriate language (poisonous speech) inside on-line gaming participant interactions. The general enterprise consequence was to enhance the group’s operations by automating an current guide course of and to enhance person expertise by rising pace and high quality in detecting inappropriate interactions between gamers, finally selling a cleaner and more healthy gaming atmosphere.
The shopper ask was to create an English language detector that classifies voice and textual content excerpts into their very own customized outlined poisonous language classes. They wished to first decide if the given language excerpt is poisonous, after which classify the excerpt in a selected customer-defined class of toxicity corresponding to profanity or abusive language.
AWS ProServe solved this use case by a joint effort between the Generative AI Innovation Heart (GAIIC) and the ProServe ML Supply Staff (MLDT). The AWS GAIIC is a gaggle inside AWS ProServe that pairs clients with specialists to develop generative AI options for a variety of enterprise use instances utilizing proof of idea (PoC) builds. AWS ProServe MLDT then takes the PoC by manufacturing by scaling, hardening, and integrating the answer for the client.
This buyer use case will probably be showcased in two separate posts. This submit (Half 1) serves as a deep dive into the scientific methodology. It’ll clarify the thought course of and experimentation behind the answer, together with the mannequin coaching and improvement course of. Half 2 will delve into the productionized resolution, explaining the design choices, information circulate, and illustration of the mannequin coaching and deployment structure.
This submit covers the next matters:
- The challenges AWS ProServe needed to clear up for this use case
- Historic context about giant language fashions (LLMs) and why this expertise is an ideal match for this use case
- AWS GAIIC’s PoC and AWS ProServe MLDT’s resolution from an information science and machine studying (ML) perspective
Knowledge problem
The primary problem AWS ProServe confronted with coaching a poisonous language classifier was acquiring sufficient labeled information from the client to coach an correct mannequin from scratch. AWS obtained about 100 samples of labeled information from the client, which is lots lower than the 1,000 samples advisable for fine-tuning an LLM within the information science neighborhood.
As an added inherent problem, pure language processing (NLP) classifiers are traditionally recognized to be very expensive to coach and require a big set of vocabulary, often known as a corpus, to supply correct predictions. A rigorous and efficient NLP resolution, if offered enough quantities of labeled information, could be to coach a customized language mannequin utilizing the client’s labeled information. The mannequin could be skilled solely with the gamers’ recreation vocabulary, making it tailor-made to the language noticed within the video games. The shopper had each value and time constraints that made this resolution unviable. AWS ProServe was pressured to discover a resolution to coach an correct language toxicity classifier with a comparatively small labeled dataset. The answer lay in what’s often known as switch studying.
The concept behind switch studying is to make use of the information of a pre-trained mannequin and apply it to a distinct however comparatively related drawback. For instance, if a picture classifier was skilled to foretell if a picture incorporates a cat, you can use the information that the mannequin gained throughout its coaching to acknowledge different animals like tigers. For this language use case, AWS ProServe wanted to discover a beforehand skilled language classifier that was skilled to detect poisonous language and fine-tune it utilizing the client’s labeled information.
The answer was to search out and fine-tune an LLM to categorise poisonous language. LLMs are neural networks which were skilled utilizing a large variety of parameters, usually within the order of billions, utilizing unlabeled information. Earlier than going into the AWS resolution, the next part offers an summary into the historical past of LLMs and their historic use instances.
Tapping into the ability of LLMs
LLMs have lately change into the point of interest for companies in search of new functions of ML, ever since ChatGPT captured the general public mindshare by being the quickest rising shopper software in historical past2, reaching 100 million lively customers by January 2023, simply 2 months after its launch. Nonetheless, LLMs usually are not a brand new expertise within the ML area. They’ve been used extensively to carry out NLP duties corresponding to analyzing sentiment, summarizing corpuses, extracting key phrases, translating speech, and classifying textual content.
Because of the sequential nature of textual content, recurrent neural networks (RNNs) had been the state-of-the-art for NLP modeling. Particularly, the encoder-decoder community structure was formulated as a result of it created an RNN construction able to taking an enter of arbitrary size and producing an output of arbitrary size. This was excellent for NLP duties like translation the place an output phrase of 1 language could possibly be predicted from an enter phrase of one other language, usually with differing numbers of phrases between the enter and output. The Transformer structure3 (Vaswani, 2017) was a breakthrough enchancment on the encoder-decoder; it launched the idea of self-attention, which allowed the mannequin to focus its consideration on completely different phrases on the enter and output phrases. In a typical encoder-decoder, every phrase is interpreted by the mannequin in an similar vogue. Because the mannequin sequentially processes every phrase in an enter phrase, the semantic info initially could also be misplaced by the top of the phrase. The self-attention mechanism modified this by including an consideration layer to each the encoder and decoder block, in order that the mannequin may put completely different weightings on sure phrases from the enter phrase when producing a sure phrase within the output phrase. Thus the premise of the transformer mannequin was born.
The transformer structure was the inspiration for 2 of probably the most well-known and in style LLMs in use right this moment, the Bidirectional Encoder Representations from Transformers (BERT)4 (Radford, 2018) and the Generative Pretrained Transformer (GPT)5 (Devlin 2018). Later variations of the GPT mannequin, particularly GPT3 and GPT4, are the engine that powers the ChatGPT software. The ultimate piece of the recipe that makes LLMs so highly effective is the power to distill info from huge textual content corpuses with out in depth labeling or preprocessing by way of a course of known as ULMFiT. This methodology has a pre-training part the place normal textual content will be gathered and the mannequin is skilled on the duty of predicting the following phrase based mostly on earlier phrases; the profit right here is that any enter textual content used for coaching comes inherently prelabeled based mostly on the order of the textual content. LLMs are actually able to studying from internet-scale information. For instance, the unique BERT mannequin was pre-trained on the BookCorpus and full English Wikipedia textual content datasets.
This new modeling paradigm has given rise to 2 new ideas: basis fashions (FMs) and Generative AI. Versus coaching a mannequin from scratch with task-specific information, which is the standard case for classical supervised studying, LLMs are pre-trained to extract normal information from a broad textual content dataset earlier than being tailored to particular duties or domains with a a lot smaller dataset (usually on the order of a whole lot of samples). The brand new ML workflow now begins with a pre-trained mannequin dubbed a basis mannequin. It’s necessary to construct on the correct basis, and there are an rising variety of choices, corresponding to the brand new Amazon Titan FMs, to be launched by AWS as a part of Amazon Bedrock. These new fashions are additionally thought-about generative as a result of their outputs are human interpretable and in the identical information sort because the enter information. Whereas previous ML fashions have been descriptive, corresponding to classifying pictures of cats vs. canine, LLMs are generative as a result of their output is the following set of phrases based mostly on enter phrases. That permits them to energy interactive functions corresponding to ChatGPT that may be expressive within the content material they generate.
Hugging Face has partnered with AWS to democratize FMs and make them simple to entry and construct with. Hugging Face has created a Transformers API that unifies greater than 50 completely different transformer architectures on completely different ML frameworks, together with entry to pre-trained mannequin weights of their Model Hub, which has grown to over 200,000 fashions as of scripting this submit. Within the subsequent sections, we discover the proof of idea, the answer, and the FMs that have been examined and chosen as the premise for fixing this poisonous speech classification use case for the client.
AWS GAIIC proof of idea
AWS GAIIC selected to experiment with LLM basis fashions with the BERT structure to fine-tune a poisonous language classifier. A complete of three fashions from Hugging Face’s mannequin hub have been examined:
All three mannequin architectures are based mostly on the BERTweet structure. BERTweet is skilled based mostly on the RoBERTa pre-training process. The RoBERTa pre-training process is an consequence of a replication research of BERT pre-training that evaluated the results of hyperparameter tuning and coaching set dimension to enhance the recipe for coaching BERT fashions6 (Liu 2019). The experiment sought to discover a pre-training methodology that improved the efficiency outcomes of BERT with out altering the underlying structure. The conclusion of the research discovered that the next pre-training modifications considerably improved the efficiency of BERT:
- Coaching the mannequin with larger batches over extra information
- Eradicating the following sentence prediction goal
- Coaching on longer sequences
- Dynamically altering the masking sample utilized to the coaching information
The bertweet-base mannequin makes use of the previous pre-training process from the RoBERTa research to pre-train the unique BERT structure utilizing 850 million English tweets. It’s the first public large-scale language mannequin pre-trained for English tweets.
Pre-trained FMs utilizing tweets have been thought to suit the use case for 2 primary theoretical causes:
- The size of a tweet is similar to the size of an inappropriate or poisonous phrase present in on-line recreation chats
- Tweets come from a inhabitants with a big number of completely different customers, much like that of the inhabitants present in gaming platforms
AWS determined to first fine-tune BERTweet with the client’s labeled information to get a baseline. Then selected to fine-tune two different FMs in bertweet-base-offensive and bertweet-base-hate that have been additional pre-trained particularly on extra related poisonous tweets to realize probably increased accuracy. The bertweet-base-offensive mannequin makes use of the bottom BertTweet FM and is additional pre-trained on 14,100 annotated tweets that have been deemed as offensive7 (Zampieri 2019). The bertweet-base-hate mannequin additionally makes use of the bottom BertTweet FM however is additional pre-trained on 19,600 tweets that have been deemed as hate speech8 (Basile 2019).
To additional improve the efficiency of the PoC mannequin, AWS GAIIC made two design choices:
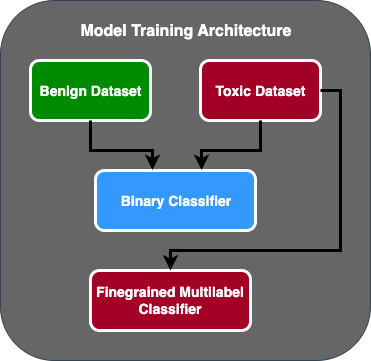
- Created a two-stage prediction circulate the place the primary mannequin acts as a binary classifier that classifies whether or not a chunk of textual content is poisonous or not poisonous. The second mannequin is a fine-grained mannequin that classifies textual content based mostly on the client’s outlined poisonous varieties. Provided that the primary mannequin predicts the textual content as poisonous does it get handed to the second mannequin.
- Augmented the coaching information and added a subset of a third-party-labeled poisonous textual content dataset from a public Kaggle competitors (Jigsaw Toxicity) to the unique 100 samples obtained from the client. They mapped the Jigsaw labels to the related customer-defined toxicity labels and did an 80% break up as coaching information and 20% break up as take a look at information to validate the mannequin.
AWS GAIIC used Amazon SageMaker notebooks to run their fine-tuning experiments and located that the bertweet-base-offensive mannequin achieved the very best scores on the validation set. The next desk summarizes the noticed metric scores.
| Mannequin | Precision | Recall | F1 | AUC |
| Binary | .92 | .90 | .91 | .92 |
| Superb-grained | .81 | .80 | .81 | .89 |
From this level, GAIIC handed off the PoC to the AWS ProServe ML Supply Staff to productionize the PoC.
AWS ProServe ML Supply Staff resolution
To productionize the mannequin structure, the AWS ProServe ML Supply Staff (MLDT) was requested by the client to create an answer that’s scalable and simple to keep up. There have been just a few upkeep challenges of a two-stage mannequin strategy:
- The fashions would require double the quantity of mannequin monitoring, which makes retraining timing inconsistent. There could also be instances that one mannequin must be retrained extra typically than the opposite.
- Elevated prices of operating two fashions versus one.
- The pace of inference slows as a result of inference goes by two fashions.
To deal with these challenges, AWS ProServe MLDT had to determine the way to flip the two-stage mannequin structure right into a single mannequin structure whereas nonetheless having the ability to preserve the accuracy of the two-stage structure.
The answer was to first ask the client for extra coaching information, then to fine-tune the bertweet-base-offensive mannequin on all of the labels, together with non-toxic samples, into one mannequin. The concept was that fine-tuning one mannequin with extra information would end in related outcomes as fine-tuning a two-stage mannequin structure on much less information. To fine-tune the two-stage mannequin structure, AWS ProServe MLDT up to date the pre-trained mannequin multi-label classification head to incorporate one further node to characterize the non-toxic class.
The next is a code pattern of how you’ll fine-tune a pre-trained mannequin from the Hugging Face mannequin hub utilizing their transformers platform and alter the mannequin’s multi-label classification head to foretell the specified variety of lessons. AWS ProServe MLDT used this blueprint as its foundation for fine-tuning. It assumes that you’ve got your prepare information and validation information prepared and within the right enter format.
First, Python modules are imported in addition to the specified pre-trained mannequin from the Hugging Face mannequin hub:
The pre-trained mannequin then will get loaded and prepped for fine-tuning. That is the step the place the variety of poisonous classes and all mannequin parameters get outlined:
Mannequin fine-tuning begins with inputting paths to the coaching and validation datasets:
AWS ProServe MLDT obtained roughly 5,000 extra labeled information samples, 3,000 being non-toxic and a pair of,000 being poisonous, and fine-tuned all three bertweet-base fashions, combining all labels into one mannequin. They used this information along with the 5,000 samples from the PoC to fine-tune new one-stage fashions utilizing the identical 80% prepare set, 20% take a look at set methodology. The next desk reveals that the efficiency scores have been corresponding to that of the two-stage mannequin.
| Mannequin | Precision | Recall | F1 | AUC |
| bertweet-base (1-Stage) | .76 | .72 | .74 | .83 |
| bertweet-base-hate (1-Stage) | .85 | .82 | .84 | .87 |
| bertweet-base-offensive (1-Stage) | .88 | .83 | .86 | .89 |
| bertweet-base-offensive (2-Stage) | .91 | .90 | .90 | .92 |
The one-stage mannequin strategy delivered the price and upkeep enhancements whereas solely reducing the precision by 3%. After weighing the trade-offs, the client opted for AWS ProServe MLDT to productionize the one-stage mannequin.
By fine-tuning one mannequin with extra labeled information, AWS ProServe MLDT was capable of ship an answer that met the client’s threshold for mannequin accuracy, in addition to ship on their ask for ease of upkeep, whereas reducing value and rising robustness.
Conclusion
A big gaming buyer was in search of a method to detect poisonous language inside their communication channels to advertise a socially accountable gaming atmosphere. AWS GAIIC created a PoC of a poisonous language detector by fine-tuning an LLM to detect poisonous language. AWS ProServe MLDT then up to date the mannequin coaching circulate from a two-stage strategy to a one-stage strategy and productionized the LLM for the client for use at scale.
On this submit, AWS demonstrates the effectiveness and practicality of fine-tuning an LLM to resolve this buyer use case, shares context on the historical past of basis fashions and LLMs, and introduces the workflow between the AWS Generative AI Innovation Heart and the AWS ProServe ML Supply Staff. Within the subsequent submit on this collection, we are going to dive deeper into how AWS ProServe MLDT productionized the ensuing one-stage mannequin utilizing SageMaker.
In case you are concerned with working with AWS to construct a Generative AI resolution, please attain out to the GAIIC. They’ll assess your use case, construct out a Generative-AI-based proof of idea, and have choices to increase collaboration with AWS to implement the ensuing PoC into manufacturing.
References
- Gamer Demographics: Facts and Stats About the Most Popular Hobby in the World
- ChatGPT sets record for fastest-growing user base – analyst note
- Vaswani et al., “Consideration is All You Want”
- Radford et al., “Bettering Language Understanding by Generative Pre-Coaching”
- Devlin et al., “BERT: Pre-Coaching of Deep Bidirectional Transformers for Language Understanding”
- Yinhan Liu et al., “RoBERTa: A Robustly Optimized BERT Pretraining Strategy”
- Marcos Zampieri et al., “SemEval-2019 Task 6: Identifying and Categorizing Offensive Language in Social Media (OffensEval)”
- Valerio Basile et al., “SemEval-2019 Task 5: Multilingual Detection of Hate Speech Against Immigrants and Women in Twitter”
In regards to the authors
 James Poquiz is a Knowledge Scientist with AWS Skilled Providers based mostly in Orange County, California. He has a BS in Laptop Science from the College of California, Irvine and has a number of years of expertise working within the information area having performed many alternative roles. As we speak he works on implementing and deploying scalable ML options to realize enterprise outcomes for AWS purchasers.
James Poquiz is a Knowledge Scientist with AWS Skilled Providers based mostly in Orange County, California. He has a BS in Laptop Science from the College of California, Irvine and has a number of years of expertise working within the information area having performed many alternative roles. As we speak he works on implementing and deploying scalable ML options to realize enterprise outcomes for AWS purchasers.
 Han Man is a Senior Knowledge Science & Machine Studying Supervisor with AWS Skilled Providers based mostly in San Diego, CA. He has a PhD in Engineering from Northwestern College and has a number of years of expertise as a administration guide advising purchasers in manufacturing, monetary companies, and vitality. As we speak, he’s passionately working with key clients from quite a lot of trade verticals to develop and implement ML and GenAI options on AWS.
Han Man is a Senior Knowledge Science & Machine Studying Supervisor with AWS Skilled Providers based mostly in San Diego, CA. He has a PhD in Engineering from Northwestern College and has a number of years of expertise as a administration guide advising purchasers in manufacturing, monetary companies, and vitality. As we speak, he’s passionately working with key clients from quite a lot of trade verticals to develop and implement ML and GenAI options on AWS.
 Safa Tinaztepe is a full-stack information scientist with AWS Skilled Providers. He has a BS in laptop science from Emory College and has pursuits in MLOps, distributed methods, and web3.
Safa Tinaztepe is a full-stack information scientist with AWS Skilled Providers. He has a BS in laptop science from Emory College and has pursuits in MLOps, distributed methods, and web3.