
In pc imaginative and prescient (CV), including tags to determine objects of curiosity or bounding bins to find the objects is named labeling. It’s one of many prerequisite duties to arrange coaching information to coach a deep studying mannequin. Lots of of 1000’s of labor hours are spent producing high-quality labels from pictures and movies for varied CV use circumstances. You should use Amazon SageMaker Data Labeling in two methods to create these labels:
- Amazon SageMaker Ground Truth Plus – This service gives an knowledgeable workforce that’s educated on ML duties and will help meet your information safety, privateness, and compliance necessities. You add your information, and the Floor Fact Plus staff creates and manages information labeling workflows and the workforce in your behalf.
- Amazon SageMaker Ground Truth – Alternatively, you may handle your individual information labeling workflows and workforce to label information.
Particularly, for deep learning-based autonomous car (AV) and Superior Driver Help Methods (ADAS), there’s a must label complicated multi-modal information from scratch, together with synchronized LiDAR, RADAR, and multi-camera streams. For instance, the next determine reveals a 3D bounding field round a automobile within the Level Cloud view for LiDAR information, aligned orthogonal LiDAR views on the facet, and 7 totally different digital camera streams with projected labels of the bounding field.
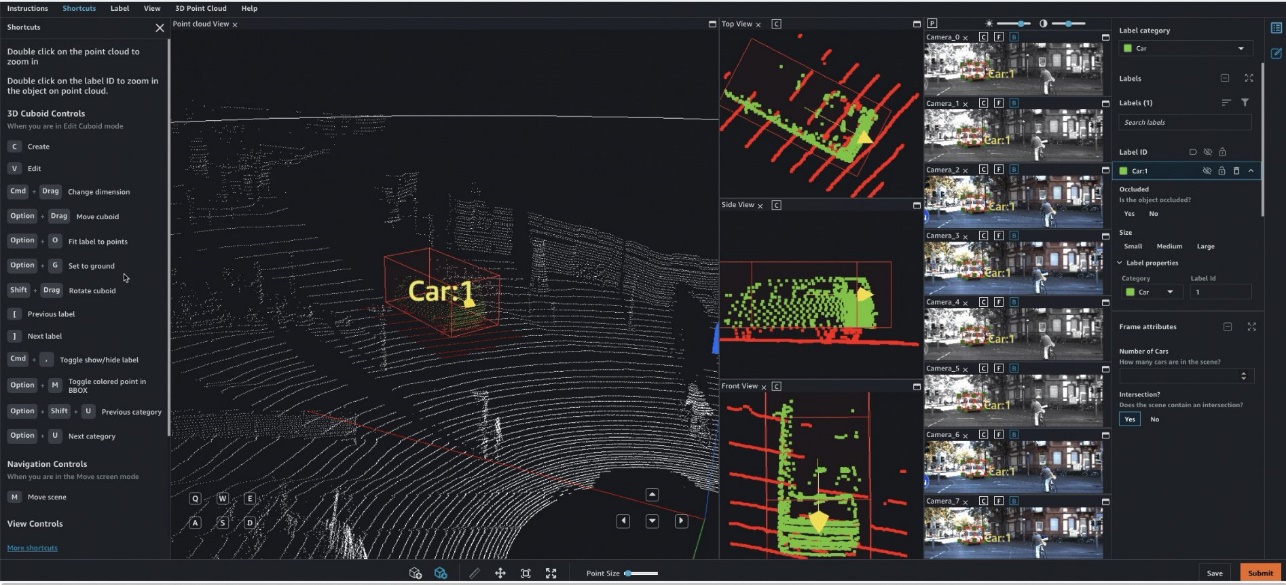
AV/ADAS groups must label a number of thousand frames from scratch, and depend on methods like label consolidation, automated calibration, body choice, body sequence interpolation, and lively studying to get a single labeled dataset. Floor Fact helps these options. For a full record of options, confer with Amazon SageMaker Data Labeling Features. Nonetheless, it may be difficult, costly, and time-consuming to label tens of 1000’s of miles of recorded video and LiDAR information for firms which can be within the enterprise of making AV/ADAS techniques. One method used to resolve this drawback immediately is auto-labeling, which is highlighted within the following diagram for a modular functions design for ADAS on AWS.

On this publish, we exhibit use SageMaker options resembling Amazon SageMaker JumpStart fashions and asynchronous inference capabilities together with Floor Fact’s performance to carry out auto-labeling.
Auto-labeling overview
Auto-labeling (generally known as pre-labeling) happens earlier than or alongside handbook labeling duties. On this module, the best-so-far mannequin educated for a selected job (for instance, pedestrian detection or lane segmentation) is used to generate high-quality labels. Handbook labelers merely confirm or modify the routinely created labels from the ensuing dataset. That is simpler, sooner and cheaper than labeling these massive datasets from scratch. Downstream modules such because the coaching or validation modules can use these labels as is.
Energetic studying is one other idea that’s intently associated to auto-labeling. It’s a machine studying (ML) method that identifies information that ought to be labeled by your employees. Floor Fact’s automated information labeling performance is an instance of lively studying. When Floor Fact begins an automatic information labeling job, it selects a random pattern of enter information objects and sends them to human employees. When the labeled information is returned, it’s used to create a coaching set and a validation set. Floor Fact makes use of these datasets to coach and validate the mannequin used for auto-labeling. Floor Fact then runs a batch rework job to generate labels for unlabeled information, together with confidence scores for brand new information. Labeled information with low confidence scores is shipped to human labelers. This course of of coaching, validating, and batch rework is repeated till the total dataset is labeled.
In distinction, auto-labeling assumes {that a} high-quality, pre-trained mannequin exists (both privately inside the firm, or publicly in a hub). This mannequin is used to generate labels that may be trusted and used for downstream duties resembling label verification duties, coaching, or simulation. This pre-trained mannequin within the case of AV/ADAS techniques is deployed onto the automobile on the edge, and can be utilized inside large-scale, batch inference jobs on the cloud to generate high-quality labels.
JumpStart gives pretrained, open-source fashions for a variety of drawback sorts that can assist you get began with machine studying. You should use JumpStart to share fashions inside your group. Let’s get began!
Answer overview
For this publish, we define the key steps with out going over each cell in our instance pocket book. To comply with alongside or attempt it by yourself, you may run the Jupyter notebook in Amazon SageMaker Studio.
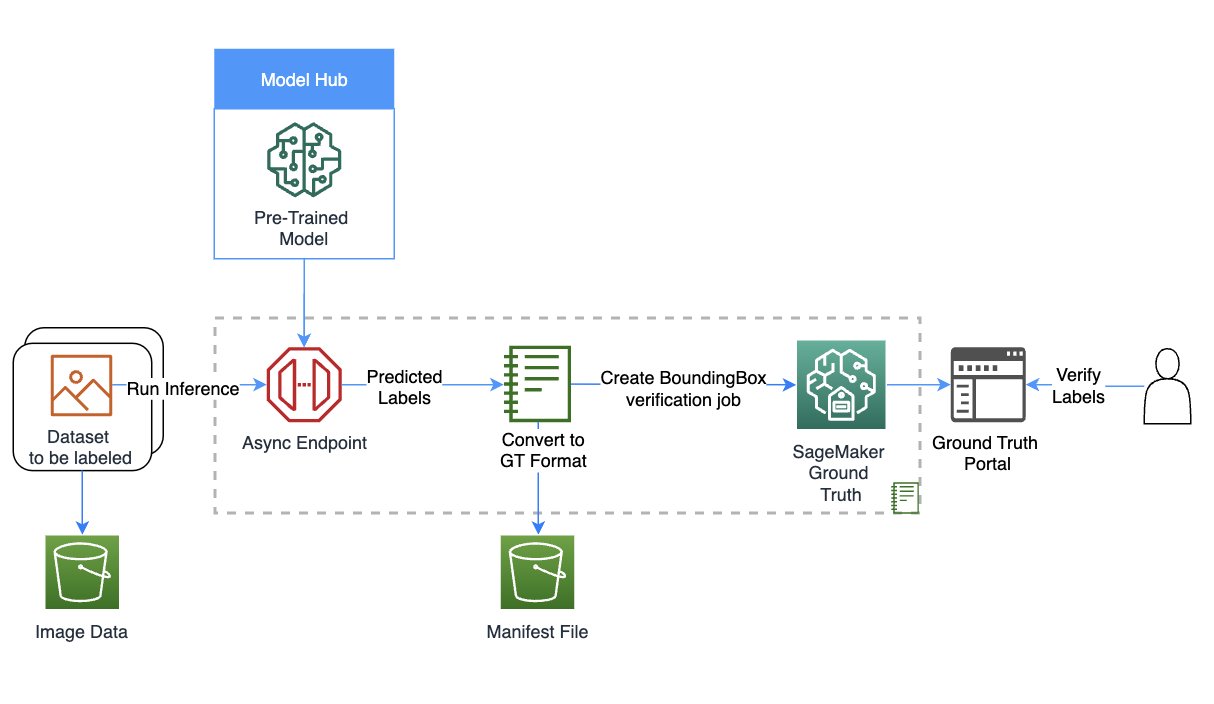
The next diagram gives an answer overview.
Arrange the position and session
For this instance, we used a Knowledge Science 3.0 kernel in Studio on an ml.m5.massive occasion kind. First, we do some primary imports and arrange the position and session to be used later within the pocket book:
Create your mannequin utilizing SageMaker
On this step, we create a mannequin for the auto-labeling job. You possibly can select from three choices to create a mannequin:
- Create a mannequin from JumpStart – With JumpStart, we are able to carry out inference on the pre-trained mannequin, even with out fine-tuning it first on a brand new dataset
- Use a mannequin shared by way of JumpStart together with your staff or group – You should use this feature if you wish to use a mannequin developed by one of many groups inside your group
- Use an current endpoint – You should use this feature in case you have an current mannequin already deployed in your account
To make use of the primary possibility, we choose a mannequin from JumpStart (right here, we use mxnet-is-mask-rcnn-fpn-resnet101-v1d-coco. An inventory of fashions is on the market within the models_manifest.json file offered by JumpStart.
We use this JumpStart mannequin that’s publicly obtainable and educated on the occasion segmentation job, however you might be free to make use of a non-public mannequin as properly. Within the following code, we use the image_uris, model_uris, and script_uris to retrieve the best parameter values to make use of this MXNet mannequin within the sagemaker.mannequin.Mannequin API to create the mannequin:
Arrange asynchronous inference and scaling
Right here we arrange an asynchronous inference config earlier than deploying the mannequin. We selected asynchronous inference as a result of it might probably deal with massive payload sizes and might meet near-real-time latency necessities. As well as, you may configure the endpoint to auto scale and apply a scaling coverage to set the occasion rely to zero when there aren’t any requests to course of. Within the following code, we set max_concurrent_invocations_per_instance to 4. We additionally arrange auto scaling such that the endpoint scales up when wanted and scales all the way down to zero after the auto-labeling job is full.
Obtain information and carry out inference
We use the Ford Multi-AV Seasonal dataset from the AWS Open Knowledge Catalog.
First, we obtain and put together the date for inference. We’ve got offered preprocessing steps to course of the dataset within the pocket book; you may change it to course of your dataset. Then, utilizing the SageMaker API, we are able to begin the asynchronous inference job as follows:
This may occasionally take as much as half-hour or extra relying on how a lot information you’ve got uploaded for asynchronous inference. You possibly can visualize one among these inferences as follows:

Convert the asynchronous inference output to a Floor Fact enter manifest
On this step, we create an enter manifest for a bounding field verification job on Floor Fact. We add the Floor Fact UI template and label classes file, and create the verification job. The pocket book linked to this publish makes use of a non-public workforce to carry out the labeling; you may change this if you happen to’re utilizing different kinds of workforces. For extra particulars, confer with the total code within the pocket book.
Confirm labels from the auto-labeling course of in Floor Fact
On this step, we full the verification by accessing the labeling portal. For extra particulars, confer with here.
If you entry the portal as a workforce member, it is possible for you to to see the bounding bins created by the JumpStart mannequin and make changes as required.

You should use this template to repeat auto-labeling with many task-specific fashions, doubtlessly merge labels, and use the ensuing labeled dataset in downstream duties.
Clear up
On this step, we clear up by deleting the endpoint and the mannequin created in earlier steps:
Conclusion
On this publish, we walked by an auto-labeling course of involving JumpStart and asynchronous inference. We used the outcomes of the auto-labeling course of to transform and visualize labeled information on a real-world dataset. You should use the answer to carry out auto-labeling with many task-specific fashions, doubtlessly merge labels, and use the ensuing labeled dataset in downstream duties. You can too discover utilizing instruments just like the Segment Anything Model for producing phase masks as a part of the auto-labeling course of. In future posts on this collection, we are going to cowl the notion module and segmentation. For extra data on JumpStart and asynchronous inference, confer with SageMaker JumpStart and Asynchronous inference, respectively. We encourage you to reuse this content material to be used circumstances past AV/ADAS, and attain out to AWS for any assist.
Concerning the authors
 Gopi Krishnamurthy is a Senior AI/ML Options Architect at Amazon Net Providers primarily based in New York Metropolis. He works with massive Automotive prospects as their trusted advisor to rework their Machine Studying workloads and migrate to the cloud. His core pursuits embody deep studying and serverless applied sciences. Outdoors of labor, he likes to spend time together with his household and discover a variety of music.
Gopi Krishnamurthy is a Senior AI/ML Options Architect at Amazon Net Providers primarily based in New York Metropolis. He works with massive Automotive prospects as their trusted advisor to rework their Machine Studying workloads and migrate to the cloud. His core pursuits embody deep studying and serverless applied sciences. Outdoors of labor, he likes to spend time together with his household and discover a variety of music.
 Shreyas Subramanian is a Principal AI/ML specialist Options Architect, and helps prospects by utilizing Machine Studying to resolve their enterprise challenges utilizing the AWS platform. Shreyas has a background in massive scale optimization and Machine Studying, and in use of Machine Studying and Reinforcement Studying for accelerating optimization duties.
Shreyas Subramanian is a Principal AI/ML specialist Options Architect, and helps prospects by utilizing Machine Studying to resolve their enterprise challenges utilizing the AWS platform. Shreyas has a background in massive scale optimization and Machine Studying, and in use of Machine Studying and Reinforcement Studying for accelerating optimization duties.

