
Expertise deployed in the true world inevitably faces unexpected challenges. These challenges come up as a result of the setting the place the know-how was developed differs from the setting the place will probably be deployed. When a know-how transfers efficiently we are saying it generalises. In a multi-agent system, equivalent to autonomous automobile know-how, there are two doable sources of generalisation problem: (1) physical-environment variation equivalent to adjustments in climate or lighting, and (2) social-environment variation: adjustments within the behaviour of different interacting people. Dealing with social-environment variation is no less than as essential as dealing with physical-environment variation, nevertheless it has been a lot much less studied.
For instance of a social setting, contemplate how self-driving vehicles work together on the street with different vehicles. Every automobile has an incentive to move its personal passenger as shortly as doable. Nonetheless, this competitors can result in poor coordination (street congestion) that negatively impacts everybody. If vehicles work cooperatively, extra passengers would possibly get to their vacation spot extra shortly. This battle is named a social dilemma.
Nonetheless, not all interactions are social dilemmas. As an illustration, there are synergistic interactions in open-source software program, there are zero-sum interactions in sports activities, and coordination issues are on the core of provide chains. Navigating every of those conditions requires a really completely different method.
Multi-agent reinforcement studying gives instruments that permit us to discover how synthetic brokers might work together with each other and with unfamiliar people (equivalent to human customers). This class of algorithms is anticipated to carry out higher when examined for his or her social generalisation talents than others. Nonetheless, till now, there was no systematic analysis benchmark for assessing this.
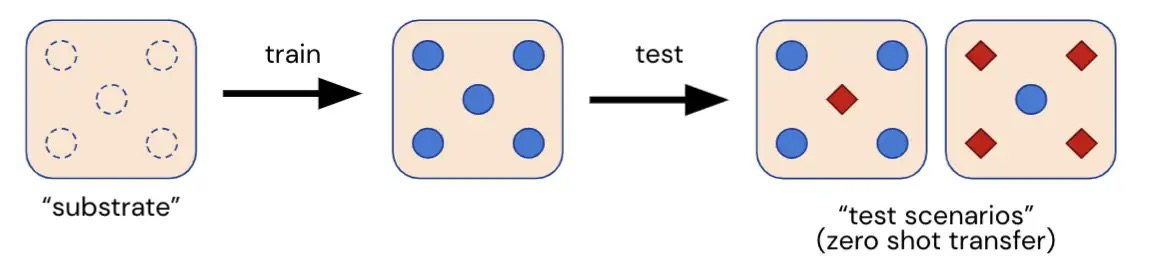
Right here we introduce Melting Pot, a scalable analysis suite for multi-agent reinforcement studying. Melting Pot assesses generalization to novel social conditions involving each acquainted and unfamiliar people, and has been designed to check a broad vary of social interactions equivalent to: cooperation, competitors, deception, reciprocation, belief, stubbornness and so forth. Melting Pot presents researchers a set of 21 MARL “substrates” (multi-agent video games) on which to coach brokers, and over 85 distinctive check eventualities on which to judge these skilled brokers. The efficiency of brokers on these held-out check eventualities quantifies whether or not brokers:
- Carry out nicely throughout a variety of social conditions the place people are interdependent,
- Work together successfully with unfamiliar people not seen throughout coaching,
- Go a universalisation check: answering positively to the query “what if everybody behaved like that?”
The ensuing rating can then be used to rank completely different multi-agent RL algorithms by their potential to generalise to novel social conditions.
We hope Melting Pot will grow to be a regular benchmark for multi-agent reinforcement studying. We plan to keep up it, and can be extending it within the coming years to cowl extra social interactions and generalisation eventualities.
Be taught extra from our GitHub page.

