
In our recent paper, we discover how populations of deep reinforcement studying (deep RL) brokers can be taught microeconomic behaviours, similar to manufacturing, consumption, and buying and selling of products. We discover that synthetic brokers be taught to make economically rational choices about manufacturing, consumption, and costs, and react appropriately to produce and demand modifications. The inhabitants converges to native costs that mirror the close by abundance of sources, and a few brokers be taught to move items between these areas to “purchase low and promote excessive”. This work advances the broader multi-agent reinforcement studying analysis agenda by introducing new social challenges for brokers to learn to resolve.
Insofar because the purpose of multi-agent reinforcement studying analysis is to ultimately produce brokers that work throughout the total vary and complexity of human social intelligence, the set of domains up to now thought-about has been woefully incomplete. It’s nonetheless lacking essential domains the place human intelligence excels, and people spend important quantities of time and vitality. The subject material of economics is one such area. Our purpose on this work is to determine environments based mostly on the themes of buying and selling and negotiation to be used by researchers in multi-agent reinforcement studying.
Economics makes use of agent-based fashions to simulate how economies behave. These agent-based fashions usually construct in financial assumptions about how brokers ought to act. On this work, we current a multi-agent simulated world the place brokers can be taught financial behaviours from scratch, in methods acquainted to any Microeconomics 101 pupil: choices about manufacturing, consumption, and costs. However our brokers additionally should make different selections that observe from a extra bodily embodied mind-set. They need to navigate a bodily atmosphere, discover bushes to select fruits, and companions to commerce them with. Current advances in deep RL methods now make it attainable to create brokers that may be taught these behaviours on their very own, with out requiring a programmer to encode area information.
Our surroundings, referred to as Fruit Market, is a multiplayer atmosphere the place brokers produce and eat two kinds of fruit: apples and bananas. Every agent is expert at producing one sort of fruit, however has a desire for the opposite – if the brokers can be taught to barter and alternate items, each events can be higher off.

In our experiments, we reveal that present deep RL brokers can be taught to commerce, and their behaviours in response to produce and demand shifts align with what microeconomic principle predicts. We then construct on this work to current eventualities that may be very troublesome to unravel utilizing analytical fashions, however that are simple for our deep RL brokers. For instance, in environments the place every sort of fruit grows in a special space, we observe the emergence of various value areas associated to the native abundance of fruit, in addition to the next studying of arbitrage behaviour by some brokers, who start to specialize in transporting fruit between these areas.
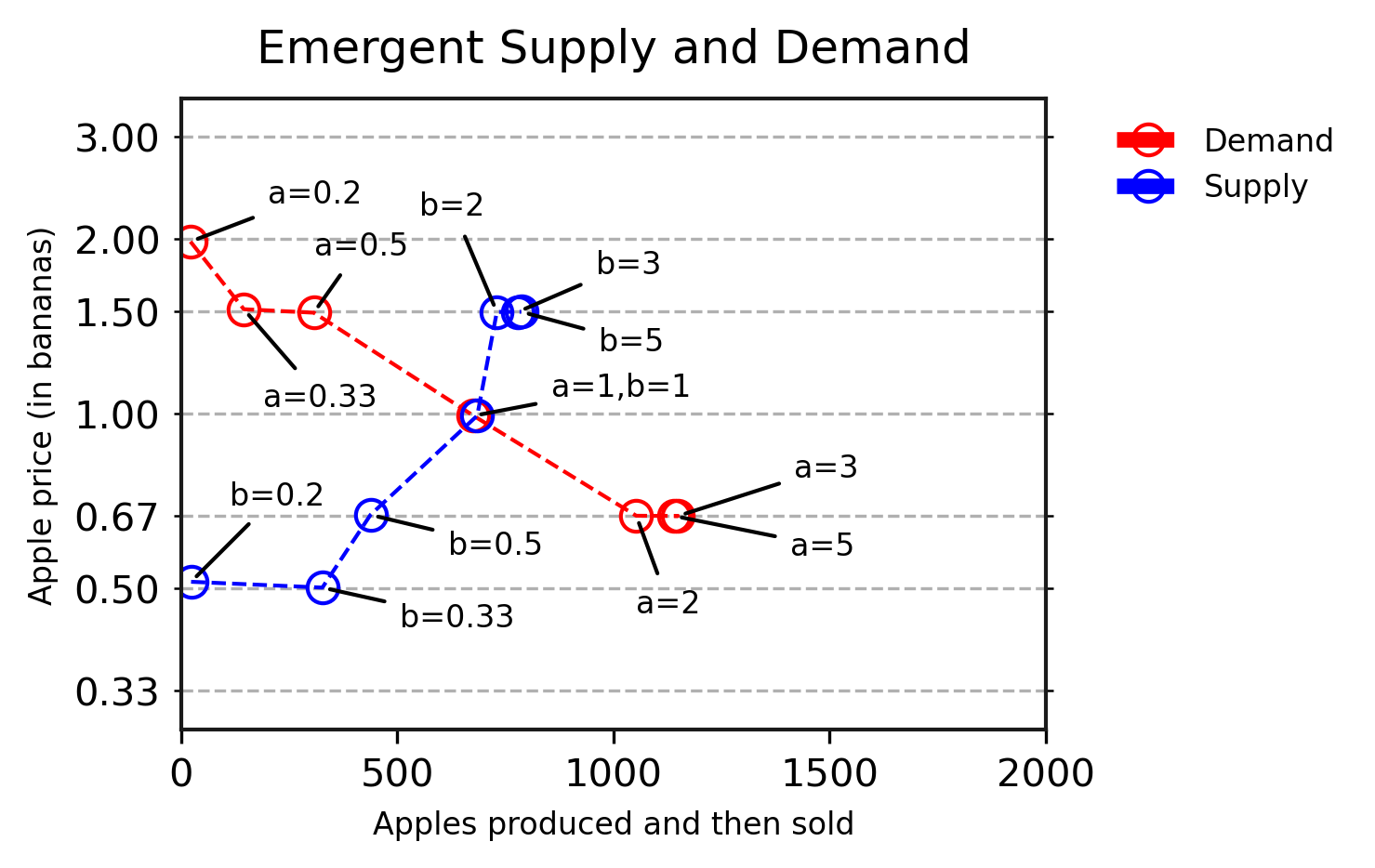
The sector of agent-based computational economics makes use of related simulations for economics analysis. On this work, we additionally reveal that state-of-the-art deep RL methods can flexibly be taught to behave in these environments from their very own expertise, with no need to have financial information in-built. This highlights the reinforcement studying neighborhood’s latest progress in multi-agent RL and deep RL, and demonstrates the potential of multi-agent methods as instruments to advance simulated economics analysis.
As a path to artificial general intelligence (AGI), multi-agent reinforcement studying analysis ought to embody all essential domains of social intelligence. Nevertheless, till now it hasn’t integrated conventional financial phenomena similar to commerce, bargaining, specialisation, consumption, and manufacturing. This paper fills this hole and supplies a platform for additional analysis. To assist future analysis on this space, the Fruit Market atmosphere might be included within the subsequent launch of the Melting Pot suite of environments.

