
Differential privacy (DP) is a rigorous mathematical definition of privateness. DP algorithms are randomized to guard person information by guaranteeing that the chance of any explicit output is sort of unchanged when a knowledge level is added or eliminated. Due to this fact, the output of a DP algorithm doesn’t disclose the presence of anyone information level. There was important progress in each foundational analysis and adoption of differential privateness with contributions such because the Privacy Sandbox and Google Open Source Library.
ML and information analytics algorithms can usually be described as performing a number of fundamental computation steps on the identical dataset. When every such step is differentially personal, so is the output, however with a number of steps the general privateness assure deteriorates, a phenomenon often known as the value of composition. Composition theorems certain the rise in privateness loss with the quantity ok of computations: Within the normal case, the privateness loss will increase with the sq. root of ok. Because of this we’d like a lot stricter privateness ensures for every step with a view to meet our general privateness assure aim. However in that case, we lose utility. A technique to enhance the privateness vs. utility trade-off is to establish when the use circumstances admit a tighter privateness evaluation than what follows from composition theorems.
Good candidates for such enchancment are when every step is utilized to a disjoint half (slice) of the dataset. When the slices are chosen in a data-independent approach, every level impacts solely one of many ok outputs and the privateness ensures don’t deteriorate with ok. Nevertheless, there are purposes by which we have to choose the slices adaptively (that’s, in a approach that will depend on the output of prior steps). In these circumstances, a change of a single information level could cascade — altering a number of slices and thus growing composition value.
In “Õptimal Differentially Private Learning of Thresholds and Quasi-Concave Optimization”, offered at STOC 2023, we describe a brand new paradigm that permits for slices to be chosen adaptively and but avoids composition value. We present that DP algorithms for a number of elementary aggregation and studying duties could be expressed on this Reorder-Slice-Compute (RSC) paradigm, gaining important enhancements in utility.
The Reorder-Slice-Compute (RSC) paradigm
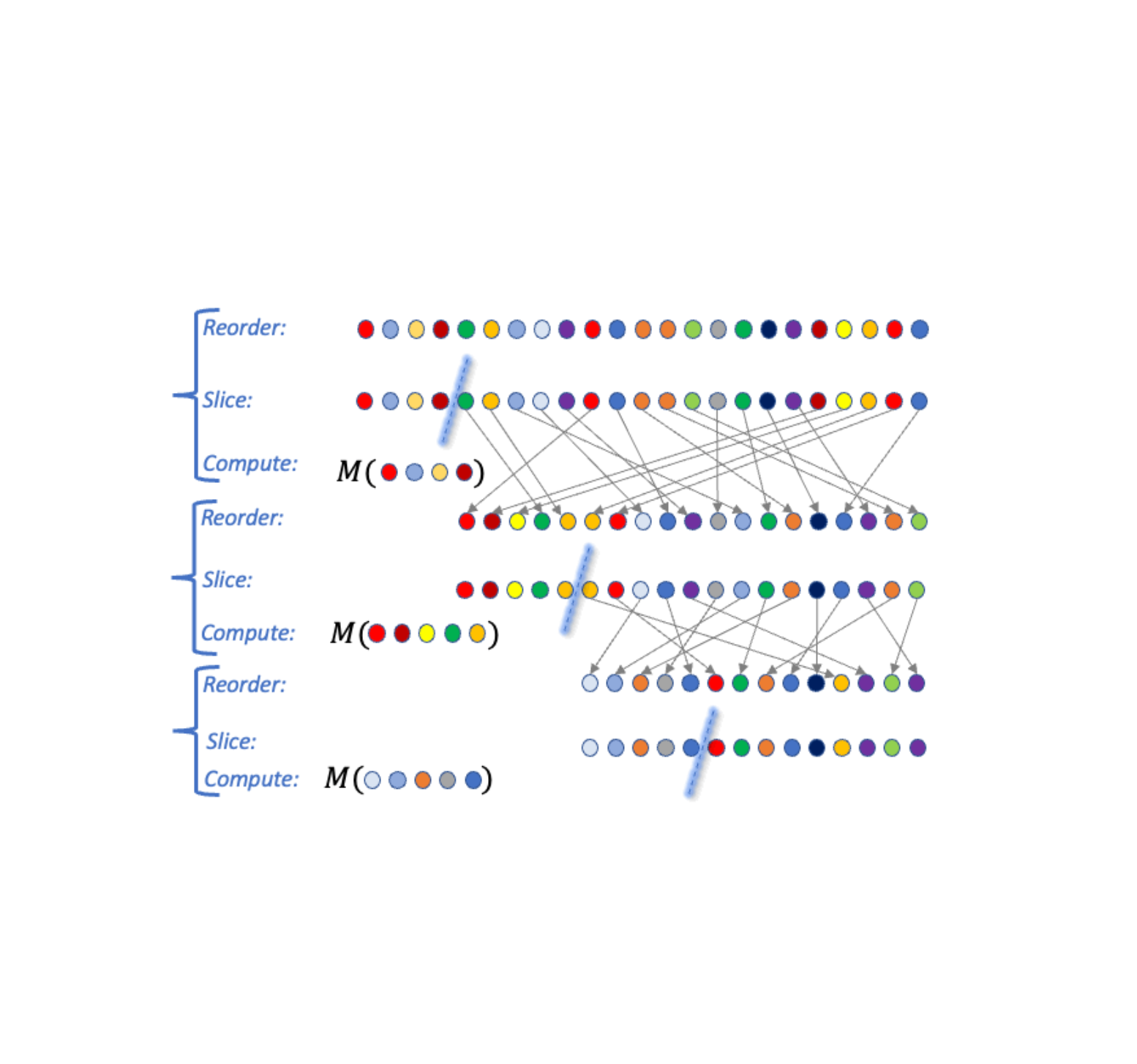
An algorithm A falls within the RSC paradigm if it may be expressed within the following normal kind (see visualization under). The enter is a delicate set D of information factors. The algorithm then performs a sequence of ok steps as follows:
- Choose an ordering over information factors, a slice measurement m, and a DP algorithm M. The choice could rely upon the output of A in prior steps (and therefore is adaptive).
- Slice out the (roughly) prime m information factors based on the order from the dataset D, apply M to the slice, and output the outcome.
 |
| A visualization of three Reorder-Slice-Compute (RSC) steps. |
If we analyze the general privateness lack of an RSC algorithm utilizing DP composition theorems, the privateness assure suffers from the anticipated composition value, i.e., it deteriorates with the sq. root of the variety of steps ok. To eradicate this composition value, we offer a novel evaluation that removes the dependence on ok altogether: the general privateness assure is near that of a single step! The concept behind our tighter evaluation is a novel approach that limits the potential cascade of affected steps when a single information level is modified (particulars in the paper).
Tighter privateness evaluation means higher utility. The effectiveness of DP algorithms is commonly acknowledged when it comes to the smallest enter measurement (variety of information factors) that suffices with a view to launch an accurate outcome that meets the privateness necessities. We describe a number of issues with algorithms that may be expressed within the RSC paradigm and for which our tighter evaluation improved utility.
Personal interval level
We begin with the next fundamental aggregation activity. The enter is a dataset D of n factors from an ordered area X (consider the area because the pure numbers between 1 and |X|). The aim is to return some extent y in X that’s within the interval of D, that’s between the minimal and the utmost factors in D.
The answer to the interval level drawback is trivial with out the privateness requirement: merely return any level within the dataset D. However this answer shouldn’t be privacy-preserving because it discloses the presence of a selected datapoint within the enter. We will additionally see that if there is just one level within the dataset, a privacy-preserving answer shouldn’t be attainable, because it should return that time. We will subsequently ask the next elementary query: What’s the smallest enter measurement N for which we will clear up the personal interval level drawback?
It’s recognized that N should enhance with the area measurement |X| and that this dependence is no less than the iterated log function log* |X| [1, 2]. However, the best prior DP algorithm required the enter measurement to be no less than (log* |X|)1.5. To shut this hole, we designed an RSC algorithm that requires solely an order of log* |X| factors.
The iterated log function is extraordinarily sluggish rising: It’s the variety of occasions we have to take a logarithm of a price earlier than we attain a price that is the same as or smaller than 1. How did this operate naturally come out within the evaluation? Every step of the RSC algorithm remapped the area to a logarithm of its prior measurement. Due to this fact there have been log* |X| steps in whole. The tighter RSC evaluation eradicated a sq. root of the variety of steps from the required enter measurement.
Regardless that the interval level activity appears very fundamental, it captures the essence of the problem of personal options for frequent aggregation duties. We subsequent describe two of those duties and categorical the required enter measurement to those duties when it comes to N.
Personal approximate median
One in all these frequent aggregation duties is approximate median: The enter is a dataset D of n factors from an ordered area X. The aim is to return some extent y that’s between the ⅓ and ⅔ quantiles of D. That’s, no less than a 3rd of the factors in D are smaller or equal to y and no less than a 3rd of the factors are bigger or equal to y. Observe that returning an actual median shouldn’t be attainable with differential privateness, because it discloses the presence of a datapoint. Therefore we take into account the relaxed requirement of an approximate median (proven under).
We will compute an approximate median by discovering an interval level: We slice out the N smallest factors and the N largest factors after which compute an interval level of the remaining factors. The latter have to be an approximate median. This works when the dataset measurement is no less than 3N.
 |
| An instance of a knowledge D over area X, the set of interval factors, and the set of approximate medians. |
Personal studying of axis-aligned rectangles
For the subsequent activity, the enter is a set of n labeled information factors, the place every level x = (x1,….,xd) is a d-dimensional vector over a website X. Displayed under, the aim is to study values ai , bi for the axes i=1,…,d that outline a d-dimensional rectangle, in order that for every instance x
- If x is positively labeled (proven as crimson plus indicators under) then it lies inside the rectangle, that’s, for all axes i, xi is within the interval [ai ,bi], and
- If x is negatively labeled (proven as blue minus indicators under) then it lies exterior the rectangle, that’s, for no less than one axis i, xi is exterior the interval [ai ,bi].
 |
| A set of 2-dimensional labeled factors and a respective rectangle. |
Any DP answer for this drawback have to be approximate in that the discovered rectangle have to be allowed to mislabel some information factors, with some positively labeled factors exterior the rectangle or negatively labeled factors inside it. It’s because an actual answer might be very delicate to the presence of a selected information level and wouldn’t be personal. The aim is a DP answer that retains this essential variety of mislabeled factors small.
We first take into account the one-dimensional case (d = 1). We’re on the lookout for an interval [a,b] that covers all optimistic factors and not one of the unfavorable factors. We present that we will do that with at most 2N mislabeled factors. We give attention to the positively labeled factors. Within the first RSC step we slice out the N smallest factors and compute a personal interval level as a. We then slice out the N largest factors and compute a personal interval level as b. The answer [a,b] accurately labels all negatively labeled factors and mislabels at most 2N of the positively labeled factors. Thus, at most ~2N factors are mislabeled in whole.
 |
| Illustration for d = 1, we slice out N left optimistic factors and compute an interval level a, slice out N proper optimistic factors and compute an interval level b. |
With d > 1, we iterate over the axes i = 1,….,d and apply the above for the ith coordinates of enter factors to acquire the values ai , bi. In every iteration, we carry out two RSC steps and slice out 2N positively labeled factors. In whole, we slice out 2dN factors and all remaining factors have been accurately labeled. That’s, all negatively-labeled factors are exterior the ultimate d-dimensional rectangle and all positively-labeled factors, besides maybe ~2dN, lie contained in the rectangle. Observe that this algorithm makes use of the complete flexibility of RSC in that the factors are ordered otherwise by every axis. Since we carry out d steps, the RSC evaluation shaves off an element of sq. root of d from the variety of mislabeled factors.
Coaching ML fashions with adaptive choice of coaching examples
The coaching effectivity or efficiency of ML fashions can typically be improved by deciding on coaching examples in a approach that will depend on the present state of the mannequin, e.g., self-paced curriculum learning or active learning.
The commonest methodology for personal coaching of ML fashions is DP-SGD, the place noise is added to the gradient replace from every minibatch of coaching examples. Privateness evaluation with DP-SGD usually assumes that coaching examples are randomly partitioned into minibatches. But when we impose a data-dependent choice order on coaching examples, and additional modify the choice standards ok occasions throughout coaching, then evaluation via DP composition leads to deterioration of the privateness ensures of a magnitude equal to the sq. root of ok.
Fortuitously, instance choice with DP-SGD could be naturally expressed within the RSC paradigm: every choice standards reorders the coaching examples and every minibatch is a slice (for which we compute a loud gradient). With RSC evaluation, there is no such thing as a privateness deterioration with ok, which brings DP-SGD coaching with instance choice into the sensible area.
Conclusion
The RSC paradigm was launched with a view to sort out an open drawback that’s primarily of theoretical significance, however seems to be a flexible software with the potential to boost information effectivity in manufacturing environments.
Acknowledgments
The work described right here was completed collectively with Xin Lyu, Jelani Nelson, and Tamas Sarlos.

